1.核心思想
MAE 的核心思想是通过掩码和重建的方式,让模型从未标注的图像中学习到有效的特征。其流程如下:
(1)随机掩码:将输入图像分割为多个不重叠的图像块(Patches),随机遮蔽其中一部分(例如75%)。
(2)编码器处理可见部分:仅对未被遮蔽的图像块进行编码,提取高维语义特征。
(3)解码器重建图像:利用编码后的特征和掩码标记(Mask Token)重建被遮蔽的图像区域。
(4)损失函数优化:通过最小化重建图像与原始图像之间的差异(如MSE)来训练模型。
2.MAE的结构
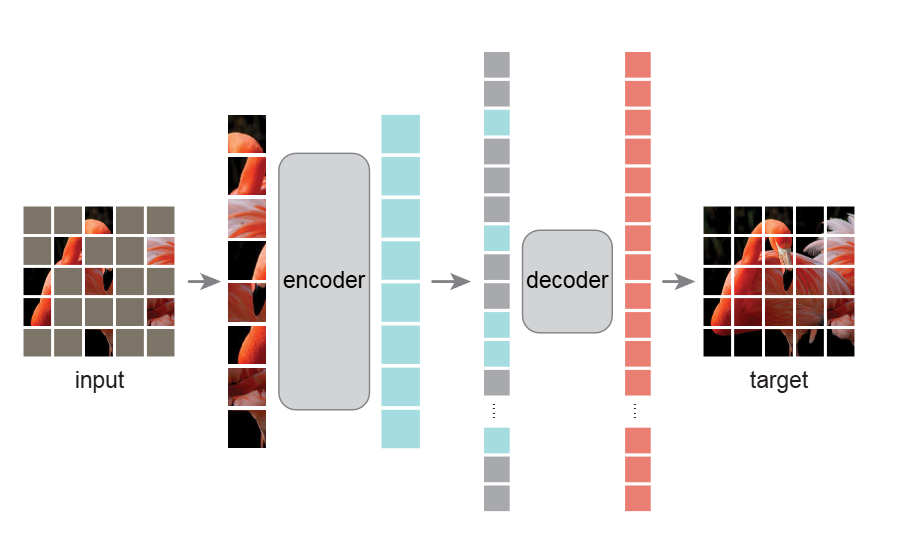
MAE 由两个主要部分组成:
(1)编码器(Encoder)
功能:从可见图像块中提取高维语义特征。
设计:基于 Vision Transformer(ViT),仅处理未被遮蔽的图像块,计算量较小。
特点:输入为未被遮蔽的图像块(约占25%)。输出为潜在的语义表示(Latent Representations)。
(2)解码器(Decoder)
功能:根据潜在表示和掩码标记重建原始图像。
设计:轻量级的 Transformer 结构,输入包括编码器输出的潜在表示(可见部分)和掩码标记(Mask Token)的位置信息。
特点:仅在训练时使用(用于重建任务)。最终输出为完整的图像像素值。
3.关键设计
(1)非对称架构
编码器专注于提取高维语义信息(类似NLP中的BERT),解码器负责低层次的像素重建任务,两者分工明确,提升训练效率。
(2)高掩码比例
实验证明,掩码75%的图像块能有效迫使模型学习全局结构信息,而非局部细节。
(3)位置编码
编码器和解码器均使用位置编码(Sine-Cosine 编码),保留图像的空间信息。
4.训练与优化
(1)训练目标
重建损失(Reconstruction Loss):仅对被掩码的图像块计算损失(如MSE)。
优化策略:使用批量归一化、动态学习率等技术加速收敛。
(2)预训练与微调
预训练阶段:在无标签的图像数据上进行自监督训练,学习通用特征。
微调阶段:在标注数据上进行有监督微调,适配下游任务(如分类、检测)。
5.应用场景
(1)图像重建
从部分掩码的图像中恢复完整内容,常用于超分辨率、去噪等任务。
(2)特征提取
预训练的编码器可提取强通用特征,用于图像分类、目标检测等下游任务。
(3)迁移学习
MAE 在 ImageNet 上的预训练模型(如 ViT-Huge)可达到87.8%的 Top-1 精度,优于有监督预训练。