什么是向量数据库?
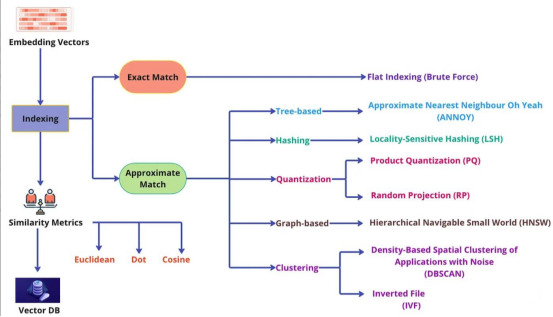
向量数据库是一种专门用于存储、索引和查询向量嵌入的数据库系统。其核心工作机制是通过哈希、量化或基于图表的搜索等算法实现近似最近邻(ANN)搜索,整体流程涵盖预处理、索引构建、相似度查询及后处理四个关键环节。
主流向量数据库对比与选型
在大模型开发中,向量数据库是核心工具之一。以下从核心优势、社区生态、局限性及综合特性等维度,对主流向量数据库进行分析,助力项目选型。
1. Milvus
- 核心优势:专为企业级大规模应用设计,支持毫秒级延迟(单查询 < 100ms),在高并发和亿级数据集场景下表现突出 ——2000 万 768 维向量(HNSW 索引)单机可达 100-500 QPS。支持 HNSW、IVF 等多种索引,且可通过 efSearch 等参数平衡速度与精度,在 ANN-Bench 测试中性能领先。
- 社区生态:由 Zilliz 开发,社区活跃度极高,提供 Python、Java、Go 等多语言 SDK,API 丰富。GitHub 地址:https://github.com/milvus-io/milvus,截至 2025 年 4 月 22 日星标数达 34.2k。
- 局限性:高并发场景需依赖分布式集群,单机 QPS 受内存和 CPU 限制,资源消耗相对较高。
2. Qdrant
- 核心优势:基于 Rust 语言开发的高效引擎,查询延迟控制在毫秒级(<100ms),2000 万向量场景下 QPS 约 100-400。其内存和磁盘上的 HNSW 实现经过优化,性能稳定;同时具备轻量特性,集成简单,对 AI 框架支持友好,成本与 Milvus 接近。
- 社区生态:社区增长迅速,文档和技术支持完善,提供 REST 和 gRPC 接口,Python/JavaScript SDK 易用性强。GitHub 地址:https://github.com/qdrant/qdrant,截至 2025 年 4 月 22 日星标数 23.1k。
- 局限性:分布式性能稳定性不及 Milvus,在大规模数据集和高并发场景下,吞吐量表现略逊。
3. Chroma
- 核心优势:主打 Python 环境适配,尤其与 LangChain 或 LlamaIndex 集成紧密。在小规模数据集(百万级以下)场景中性能优异,查询延迟适中,适合快速原型开发。
- 社区生态:社区规模较小但活跃度高,工具轻量,API 简单,文档清晰,对新手友好。GitHub 地址:https://github.com/chroma-core/chroma,截至 2025 年 4 月 22 日星标数 19.4k。
- 局限性:无原生持久化存储,需依赖外部数据库;当向量规模超过 10 亿时,性能会下降 40% 左右。
4. Weaviate
- 核心优势:在中小规模数据集上性能表现良好,查询延迟较低;支持混合搜索(向量 + 关键词),水平扩展能力较强,可处理亿级向量。
- 社区生态:提供直观的 GraphQL 查询接口,Python/Go SDK 易用,文档详尽,社区支持良好。GitHub 地址:https://github.com/weaviate/weaviate,截至 2025 年 4 月 22 日星标数 13.1k。
- 局限性:GraphQL 存在一定学习曲线;混合搜索和模块化设计虽增强了功能,但也增加了配置复杂度;大规模扩展需较多基础设施资源,成本可能高于 Qdrant。
5. 其他可选工具
- Elasticsearch:功能全面但架构较重,适合对生态兼容性要求高的场景。
- RedisVL:生态较弱,适合对轻量部署有需求但对功能丰富度要求不高的场景。
- 云平台向量数据库:价格相对较高,适合追求开箱即用、不愿投入运维资源的团队。
综合对比表
| 对比角度 | Milvus | Qdrant | Chroma | Weaviate |
|---|---|---|---|---|
| 核心定位与架构 | 大规模、云原生、企业级;分布式微服务架构(Go/C++),为海量数据和高并发设计。 | 高性能、内存安全、灵活部署;Rust 编写,性能和内存效率优先,支持单节点 / 集群模式,架构简洁。 | 开发者友好、易于上手、本地优先;Python 主导(核心库 C++/Rust),设计初衷为嵌入式 / 本地集成,支持客户端 / 服务器模式。 | GraphQL 原生、模块化、混合搜索;Go 编写,以 GraphQL API 为核心,支持模块化扩展,设计支持向量、标量和混合搜索,支持单节点 / 集群。 |
| 性能与可伸缩性 | 高;专为水平扩展设计(千亿级),支持多种索引(HNSW、IVF、DiskANN),资源消耗较高。 | 高;Rust 带来低延迟 P99 优势,支持高效过滤和量化,集群模式扩展良好。 | 中到高;中小型数据表现好,大规模扩展能力弱于其他三者,但处于快速发展中,性能依赖底层库。 | 高;Go 语言并发性能好,支持 HNSW,混合搜索为亮点,通过分片支持水平扩展,性能依赖配置和模块。 |
| 易用性与开发体验 | 中等;架构复杂,部署运维需投入,SDK 完善(多语言),文档全面。 | 较好;API 清晰,文档质量高,部署相对简单,SDK 丰富(多语言)。 | 高;Python 环境下极易上手,与 LangChain/LlamaIndex 紧密集成,适合快速原型和本地开发。 | 较好;GraphQL API 强大但有学习曲线,SDK 完善(多语言),文档良好,模块化简化部分流程。 |
| 功能丰富度 | 非常丰富;支持多索引、多距离、复杂过滤、多租户、TTL、动态 Schema 等。 | 丰富;支持强元数据过滤、地理 / 全文过滤、推荐 API、集合别名、快照、量化等。 | 基础且实用;核心向量存储 / 搜索 / 过滤完善,API 简洁,生态集成强,满足常见 RAG 需求。 | 非常丰富;支持混合搜索(BM25+Vector)、GraphQL 查询、数据对象关系、模块化扩展、多租户、备份等。 |
| 部署与运维 | 复杂;推荐 K8s 部署(Helm/Operator),组件多,监控维护专业性要求高。 | 灵活;支持 Docker、K8s(Helm)、二进制部署,提供官方云服务,运维复杂度中等。 | 简单(本地 / 基础模式);本地使用极简,客户端 / 服务器 Docker 部署容易,提供官方云服务,大规模自建运维经验较少。 | 灵活;支持 Docker、K8s(Helm)部署,提供官方云服务,运维复杂度中等,集群配置需理解其概念。 |
| 数据管理与持久化 | 强大;支持多种存储后端(S3、MinIO),数据索引分离,提供备份恢复工具、动态字段。 | 可靠;支持磁盘持久化,通过 WAL 保证写入,提供快照备份。 | 基础(演进中);依赖本地文件系统(SQLite/DuckDB + npy),服务器模式持久化更鲁棒。 | 可靠;支持磁盘持久化,可配置存储后端,内置备份 / 恢复 API,支持数据对象间链接。 |
| 许可证 | Apache 2.0 | Apache 2.0 | Apache 2.0 | BSD-3-Clause(更宽松) |
通过以上分析,可根据项目规模、性能需求、开发成本、团队技术栈等因素选择合适的向量数据库:企业级大规模场景优先考虑 Milvus;轻量集成、快速开发可选 Qdrant 或 Chroma;需混合搜索或 GraphQL 支持则侧重 Weaviate。如果想要通过大模型部署、训练过程体验向量库对RAG的强大指引,但是又没有足够的GPU资源,可以在很多公有算力平台比如易嘉云(yijiacloud.com.cn)平台上直接使用云端算力,进行模型部署实战,深度感受向量技术在大模型领域的能量。