大家好,我是玄姐。
▼最近直播超级干,预约保你有收获
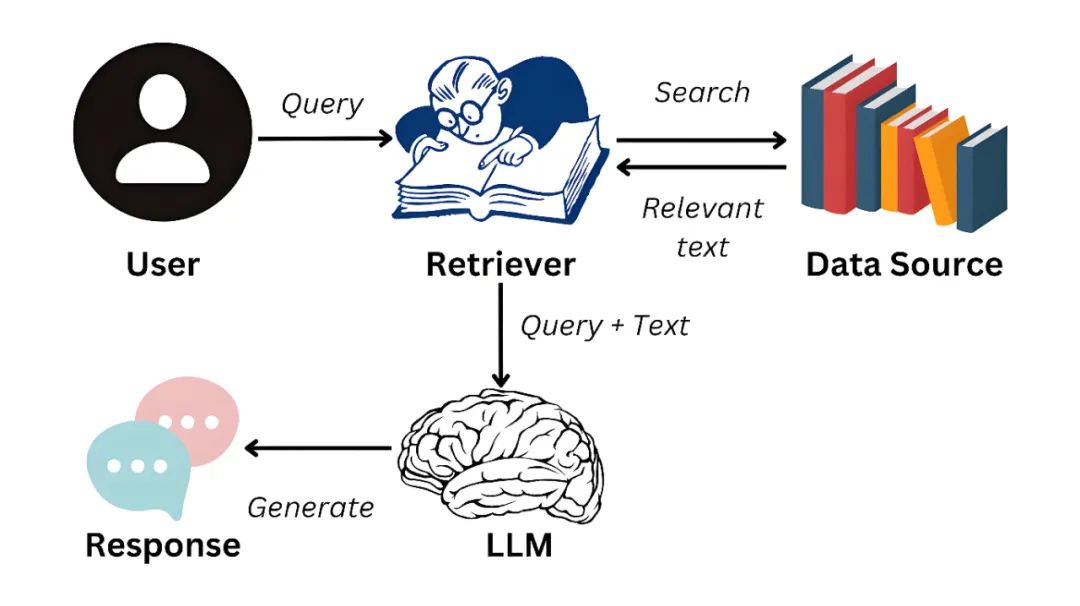
RAG(Retrieval Augmented Generation,检索增强生成)是一种结合数据工程、信息抽取和文本生成的技术范式。
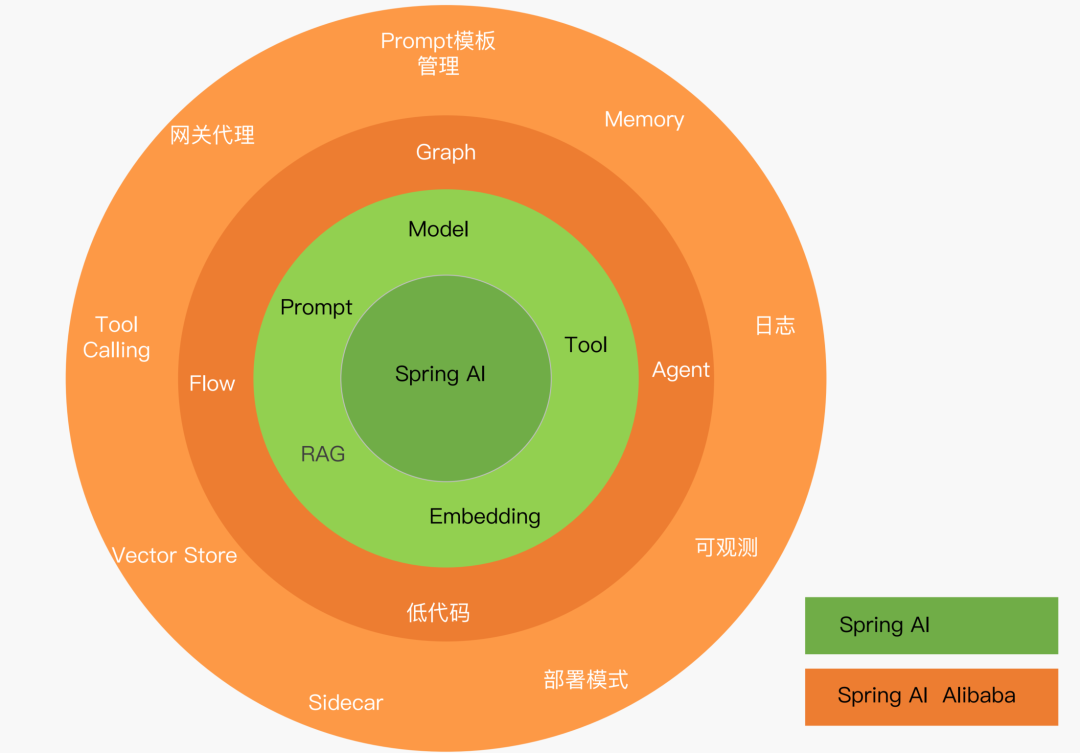
Spring AI Alibaba 是阿里巴巴开源的 AI 应用开发框架,基于 Spring AI 构建并提供了更高层面的抽象,帮助开发者快速构建 AI 应用。
—1—
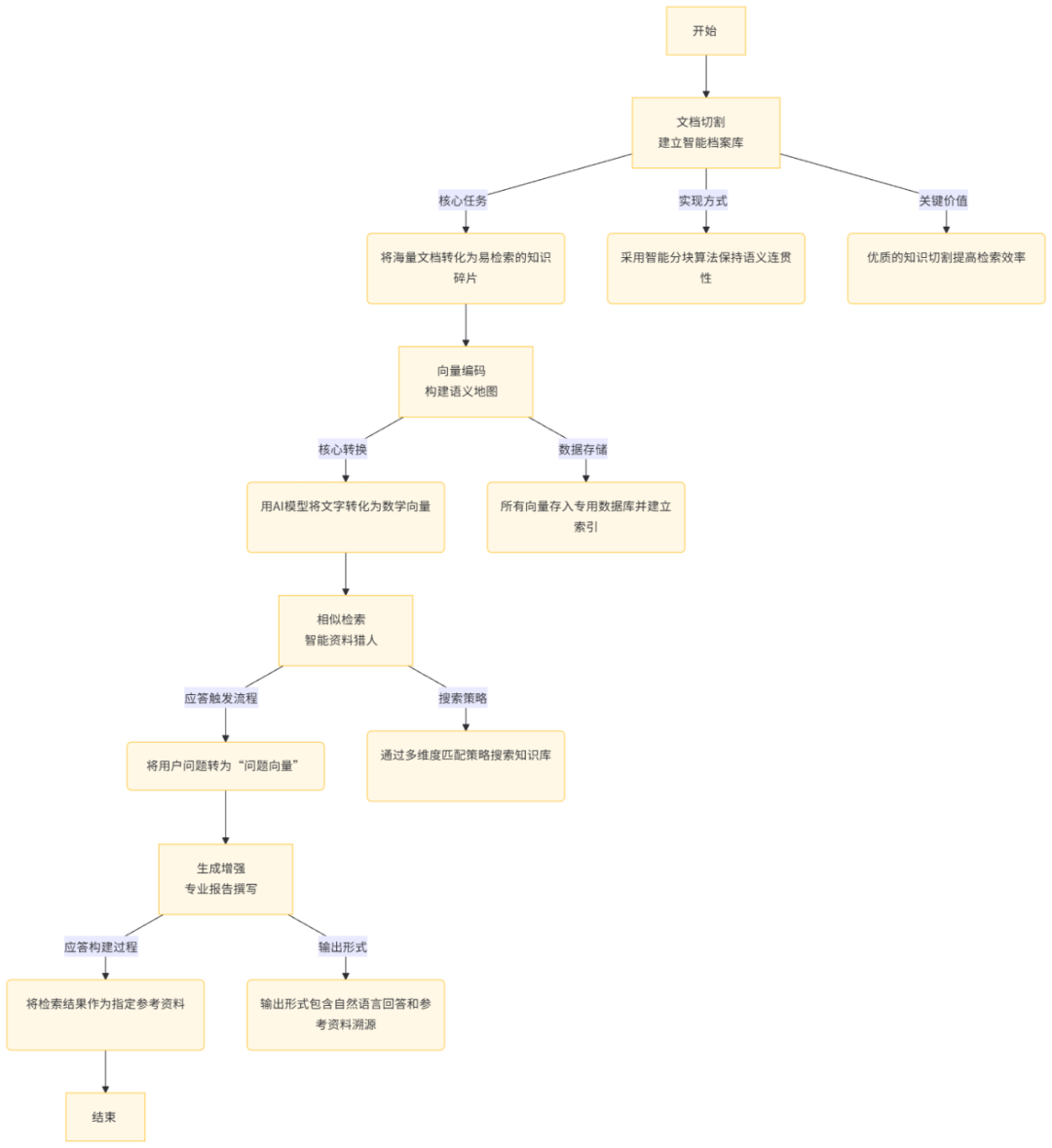
RAG 的四大核心步骤
第一、文档切割与智能档案库的建立
核心任务是将大量文档转化为易于检索的知识碎片,这一过程类似于将厚重的词典拆解成单词卡片。通过采用智能分块算法,保持语义连贯性,同时给每个知识碎片打上标签(如“技术规格”、“操作指南”)。这一步骤的关键价值在于,优质的知识切割如同图书馆的分类系统,决定了检索效率。
第二、向量编码与语义地图的构建
利用 AI 大模型将文字转化为数学向量,使语义相近的内容产生相似的数学特征。所有向量存入专用数据库,并建立快速检索索引,这类似于图书馆的书目检索系统。例如,“续航时间”和“电池容量”会被编码为相似向量。
第三、相似检索与智能资料猎人
应答触发流程包括将用户问题转为“问题向量”,并通过多维度匹配策略搜索知识库,包括语义相似度、关键词匹配度和时效性权重,输出指定个数的最相关文档片段。
第四、生成增强与专业报告撰写
应答构建过程中,将检索结果作为指定参考资料,AI 大模型在生成时自动关联相关知识片段。输出形式可以包含自然语言回答和附参考资料溯源路径。例如,“根据《产品说明技术手册 V1.3》第2章内容:该设备续航时间为...”。
—2—
Spring AI Alibaba 模块化 RAG 增强
第一、Multi Query Expansion (多查询扩展)
查询扩展技术对于增强 RAG 系统的搜索效能至关重要。在现实操作中,用户提交的查询往往简洁且信息量有限,这可能会影响搜索结果的精确度和全面性。Spring AI Alibaba 提供了一种高效的查询扩展功能,能够自动产生多个相关的查询版本,进而提升搜索的精确度和覆盖率。
// 创建聊天客户端实例// 设置系统提示信息,定义AI助手作为专业的室内设计顾问角色ChatClient chatClient = builder .defaultSystem("你是一位专业的室内设计顾问,精通各种装修风格、材料选择和空间布局。请基于提供的参考资料,为用户提供专业、详细且实用的建议。在回答时,请注意:\n" + "1. 准确理解用户的具体需求\n" + "2. 结合参考资料中的实际案例\n" + "3. 提供专业的设计理念和原理解释\n" + "4. 考虑实用性、美观性和成本效益\n" + "5. 如有需要,可以提供替代方案") .build();
// 构建查询扩展器// 用于生成多个相关的查询变体,以获得更全面的搜索结果MultiQueryExpander queryExpander = MultiQueryExpander.builder() .chatClientBuilder(builder) .includeOriginal(false) // 不包含原始查询 .numberOfQueries(3) // 生成3个查询变体 .build();
// 执行查询扩展// 将原始问题"请提供几种推荐的装修风格?"扩展成多个相关查询List<Query> queries = queryExpander.expand( new Query("请提供几种推荐的装修风格?"));在这一过程中,系统将自主地构造出多个相关的查询版本。例如,当用户提出“请提供几种推荐的室内装修风格?”的查询时,系统将生成多个从不同视角出发的查询。这种方法不仅增强了搜索结果的广度,还能够揭示用户潜在的查询目的。
多查询扩展的效果如下:
扩展后的查询内容:1. 哪些装修风格最受欢迎?请推荐一些。2. 能否推荐一些流行的家居装修风格?3. 想了解不同的装修风格,有哪些是值得推荐的?多查询扩展的优势主要体现在以下几个方面:
提升召回率:通过生成多个查询版本,增加了捕获相关文档的可能性。
多角度覆盖:从多个维度理解和拓展用户的原始查询内容。
加强语义解析:识别查询的多重潜在意义及其相关概念。
改善搜索品质:综合多个查询结果,以获得更加周全的信息集。
第二、Query Rewrite (查询重写)
查询改写是 RAG 系统中的一项关键优化手段,它通过将用户的原始查询转化为更加规范和明确的查询形式,从而提升搜索的精确度,并协助系统更准确地把握用户的真正需求。
Spring AI Aliaba 通过提供 RewriteQueryTransformer 这一工具来实现查询改写功能。以下是一个具体的操作示例:
// 构建一个模拟用户在学习人工智能过程中的查询场景Query query = new Query("我在学习人工智能,能否解释一下什么是大型语言模型?");
// 实例化查询改写转换器QueryTransformer queryTransformer = RewriteQueryTransformer.builder() .chatClientBuilder(builder) // 假设builder是之前定义好的ChatClient构建器 .build();
// 执行查询改写操作Query transformedQuery = queryTransformer.transform(query);
// 打印改写后的查询内容System.out.println(transformedQuery.text());经过改写,查询可能会优化为:
“什么是大型语言模型?”
查询改写的主要优势包括:
查询明确化:将含糊不清的问题转化为具体的查询点。
这种改写不仅有助于系统检索到更加相关的文档,同时也能够辅助生成更为全面和专业的答复。
第三、Query Translation (查询翻译)
查询翻译是 RAG 系统中的一项便捷功能,它允许将用户的查询从一个语言版本转换为另一个语言版本。这项功能对于实现多语言支持和执行跨语言搜索查询尤其重要。Spring AI Aliabab 通过 TranslationQueryTransformer 工具来实现查询的翻译功能。
以下是使用该功能的示例代码:
// 初始化一个英文的查询实例Query query =newQuery("What is LLM?");
// 实例化查询翻译转换器,并指定目标语言为中文QueryTransformer queryTransformer =TranslationQueryTransformer.builder().chatClientBuilder(builder)// 假设builder是已定义的聊天客户端构建器.targetLanguage("zh")// 设置目标语言代码为中文.build();
// 执行查询的翻译操作Query translatedQuery = queryTransformer.transform(query);
// 打印出翻译后的查询内容System.out.println(translatedQuery.text());执行上述代码后,查询将被翻译为:
“什么是大语言模型?”查询翻译功能的主要优势包括:
多语言兼容:能够在不同语言之间进行查询内容的转换。
本地化适配:将查询内容适配为目标语言的地道表达方式。
跨语言搜索:使得在不同语言的文档集合中进行有效检索成为可能。
提升用户体验:用户可以利用自己熟悉的语言发起查询,提高了系统的易用性。
第四、Context-aware Queries (上下文感知查询)
在真实的对话场景中,用户的提问经常基于之前的交流内容。为了展示如何实现上下文感知的查询,我们来看一个关于房地产咨询的例子:
// 创建一个包含历史对话的查询实例// 这个示例模拟了一个用户咨询房地产的场景,用户首先询问了小区的位置,随后询问房价Query query =Query.builder().text("那么这个小区的二手房平均价格是多少?")// 用户当前的问题.history(newUserMessage("深圳市南山区的碧海湾小区具体位置是?"),// 用户之前的问题newAssistantMessage("碧海湾小区坐落于深圳市南山区后海中心区,靠近后海地铁站。"))// 系统之前的答复.build();在这个示例中:
用户最初询问了碧海湾小区的位置(历史问题)。
系统提供了该小区的具体位置信息(历史回答)。
用户随后提问关于该小区二手房的平均价格(当前问题)。
如果不考量上下文,系统可能无法识别“这个小区”具体指代的是哪个小区。为解决这一问题,我们利用 CompressionQueryTransformer 来处理上下文信息:
// 初始化查询转换器// QueryTransformer负责将含有上下文的查询转换为一个完整的独立查询QueryTransformer queryTransformer = CompressionQueryTransformer.builder().chatClientBuilder(builder)// 假设builder是之前定义好的聊天客户端构建器.build();
// 执行查询转换操作// 将不明确的指代(“这个小区”)转换为具体的实体名称(“碧海湾小区”)Query transformedQuery = queryTransformer.transform(query);转换后的查询可能变为更加明确的形式,例如:“深圳市南山区碧海湾小区的二手房平均价格是多少?”。这种转换方式具有以下优点:
消除歧义:明确指出了查询的具体对象(碧海湾小区)。
保持上下文:包含了位置信息(深圳市南山区)。
提升精确度:使系统能够更精确地检索到相关信息。
输出的查询: “深圳市南山区碧海湾小区的二手房平均价格是多少?”第五、文档合并器(DocumentJoiner)
在现实世界的应用程序中,我们常常面临从不同的查询或数据源中收集文档的需求。为了高效地管理和整合这些文档,Spring AI 提供了 ConcatenationDocumentJoiner 这一文档合并工具。此工具能够智能地将来自多个来源的文档合并成一个统一的文档集合。
文档合并器的核心特性包括:
智能去重:在遇到重复的文档时,系统仅保留首次出现的版本。
分数保留:在合并过程中,每个文档的原始相关性评分得以保留。
多源兼容:能够同时处理来自不同查询和不同数据源的文档。
顺序保持:合并时维持文档的原始检索顺序不变。
以下是一个具体的使用示例:
// 获取来自多个查询或数据源的文档集合Map<Query,List<List<Document>>> documentsMap =...;
// 实例化文档合并器DocumentJoiner documentJoiner = newConcatenationDocumentJoiner();
// 执行文档合并操作List<Document> mergedDocuments = documentJoiner.join(documentsMap);这种合并机制在以下几种场景中尤其有用:
多轮查询:需要将多个查询返回的文档结果进行合并。
跨源检索:从不同的数据源(例如数据库、文件系统等)中获取文档。
查询扩展:当使用查询扩展技术生成多个相关查询时,需要将所有结果合并。
增量更新:在现有的文档集合中添加新的检索结果。
通过使用 ConcatenationDocumentJoiner,可以确保文档集合的整合过程既高效又准确,从而提升整体的信息检索和处理能力。
除了以上5中模块化 RAG 增强外,Spring AI Alibaba 还提供了检索增强顾问(RetrievalAugmentationAdvisor)和 Document Selection (文档选择)以及 Error Handling and Edge Cases (错误处理和边界情况)等强大功能。
—3—
Spring AI Alibaba 结构化 RAG 最佳实践
在部署和运行 RAG 系统过程中,我们需要从多个方面来优化系统性能。以下是一份全面的优化指南:
第一、文档处理优化策略
1、文档结构优化
结构化内容:确保文档包含明确的结构,例如案例编号、项目概述、设计要点等。
元数据标注:为每个文档添加丰富的元数据。
2、文档切割策略
智能分块算法:采用智能分块算法来保持语义的连贯性。
知识碎片标签:为每个知识碎片打上标签。
文档大小控制:保持文档大小适中,避免过长或过短。
第二、检索增强策略
1、多查询扩展
启用多查询扩展机制:提高检索的准确性。
查询数量设置:建议设置3-5个查询。
核心语义保留:保留原始查询的核心语义。
2、查询重写和翻译
优化查询结构:使用
RewriteQueryTransformer。多语言支持:配置
TranslationQueryTransformer。语义完整性:保持查询的语义完整性。
第三、系统配置优化策略
1、向量存储配置
选择合适的向量存储方案
SimpleVectorStore vectorStore = SimpleVectorStore.builder(embeddingModel) .build();数据规模存储方式选择:根据数据规模选择内存、Redis 或 MongoDB 存储。
2、检索器配置
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder() .vectorStore(vectorStore) .similarityThreshold(0.5) // 相似度阈值 .topK(3) // 返回文档数量 .build();设置合理的相似度阈值:
控制返回文档数量。
配置文档过滤规则。
第四、错误处理机制
1、异常处理
允许空上下文查询。
提供友好的错误提示。
引导用户提供必要信息。
2、边界情况处理
ContextualQueryAugmenter.builder().allowEmptyContext(true).build()处理文档未找到情况:
处理相似度过低情况。
处理查询超时情况。
第五、系统角色设定
1、AI 助手配置
ChatClient chatClient = builder.defaultSystem("你是一位专业的顾问,请注意:\n"+"1. 准确理解用户需求\n"+"2. 结合参考资料\n"+"3. 提供专业解释\n"+"4. 考虑实用性\n"+"5. 提供替代方案").build();设定清晰的角色定位
定义回答规范
确保专业性和实用性。
第六、性能优化建议
1、查询优化
使用文档过滤表达式。
设置合理的检索阈值。
优化查询扩展数量。
2、资源管理
控制文档加载数量。
优化内存使用。
合理设置缓存策略。
通过遵循以上最佳实践,可以构建一个高效、可靠的 RAG 系统,为用户提供准确和专业的回答。这些实践涵盖了从文档处理到系统配置的各个方面,Spring AI Alibaba 能够帮助开发者构建更好的 RAG 应用。
👉 轮到你了:你认为 RAG 企业级落地还有哪些注意点?
PS1:
为了帮助同学们彻底掌握 MCP 开发 AI 应用以及 AI 大模型新架构体系设计的新范式,我会开场直播和同学们深度剖析,请同学们点击以下预约按钮免费预约。
PS2:
【全新推出】为了帮助大家更好的掌握 AI 大模型适合的应用落地场景、应用开发技能,推荐大家加入《3天大模型应用开发项目实战直播训练营》,通过3天直播,带你快速掌握 Agent、RAG、Fine-tuning 微调、MCP、Prompt 等技能,让大家快速掌握企业级 AI 大模型应用实战能力。此训练营刚上新,原价199元,为了回馈粉丝的支持,早鸟价19元,点击以下报名。
—4—
3天大模型应用开发项目实战直播课
3天的直播课,带你快速掌握 Agent、RAG、Fine-tuning 微调、MCP、Prompt 等 AI 大模型应用开发核心技术和企业级项目实践经验。
直播模块一:Agent 智能体开发实战篇
Agent 智能体技术原理深度解读
Agent 规划能力深度剖析与实践
Agent 行动能力深度剖析与实现
Agent 工具调用之 MCP 深度剖析
Agent 智能体 ReAct 机制深度解读
从0到1,手搓代码实现企业级智能客服
直播模块二:RAG 知识库 & Fine-tuning 微调篇
RAG 知识库核心技术解读
RAG 知识库知识切分剖析与实践
RAG 知识库两阶段检索剖析与实践
RAG 知识库项目全流程深度实践
LoRA 微调技术原理剖析
RAG 和 Fine-tuning 微调技术选型
直播模块三:综合案例实战:Agent + RAG + Fine-tuning 微调 + MCP + Prompt 案例实战篇
Agentic RAG 项目需求分析
Agentic RAG 架构设计--知识库管理
Agentic RAG 架构设计--在线联网问答
Agentic RAG 架构设计--效果评估
Agentic RAG 架构设计--模型弹性扩容
Agentic RAG 核心代码实现
基于 Agent、RAG、Fine-tuning 微调、MCP、Prompt,从需求分析、架构设计、架构技术选型、硬件资料规划、核心代码落地、服务治理等全流程实践,深度学习企业级 AI 大模型应用落地项目全流程重点难点问题解决。

3天时间,你能学会什么?
在真实项目实践中,你会获得4项硬核能力:
第一、全面掌握 DeepSeek 大模型、Agent、RAG、Fine-tuning 微调、MCP、Prompt 的原理、架构和实现方法,掌握核心技术精髓。
第二、熟练使用 AI 大模型应用开发平台:LangChain、LangGraph、LlamaIndex、AutoGen、Spring AI Alibaba、Swarm 等主流开发框架,为企业级技术实践打下坚实基础。
第三、通过企业级项目实战演练,能够独立完成基于 Agent、RAG、Fine-tuning 微调、MCP、Prompt 的 AI 大模型应用的适用场景、设计开发和维护,真正学会解决企业级实际问题的能力。
第四、为职业发展提供更多可能性,无论是晋升加薪还是转行跳槽,提升核心技术竞争力。
限时优惠:
【全新推出】,刚上线,原价199元,回馈粉丝们支持,早鸟价19元!赶快加入把~~
—5—
添加助教直播学习
购买后,一定记得添加助理,否则无法进行直播学习👇

参考来源:
https://mp.weixin.qq.com/s/68X5qpG86OTZMyiYBAqHjw
⬇戳”阅读原文“,立即报名!
END