今天,为大家推荐一个高性价比、高回报的研究方向:多模态特征融合。从近期各大顶会的论文占比上就可以看出,这方向仍然是今年的发文热点,尤其在医学图像分析、行人属性识别和机器人导航等垂直领域,这些研究通过整合视觉、语言和音频等模态,显著提升了模型的感知能力和场景适应性。多模态特征融合不仅能增强系统的性能与鲁棒性,还因其通用性在教育、医疗诊断和智能交互等多样化场景中展现出广泛适用性。因此这个方向无论是创新性,还是发展前景都非常可观!
下面小图给大家推荐一些相关研究,满满干货,点赞收藏不迷路~
UniFuse: A Unified All-in-One Framework for Multi-Modal Medical Image Fusion Under Diverse Degradations and Misalignments
方法:文章首先通过 DAPL 模块提取输入图像的多方向特征并构建共享提示,以促进跨模态特征对齐和恢复。接着,OUFR 模块利用 Spatial Mamba 技术进一步消除模态差异,优化特征对齐。然后,特征对齐模块通过多尺度建模预测空间位移,实现精确的特征对齐。最后,UFR&F 模块在单一阶段内完成特征恢复和融合,利用 ALSN 的自适应特征表示能力,结合降解类型指导,实现高效的一体化处理。
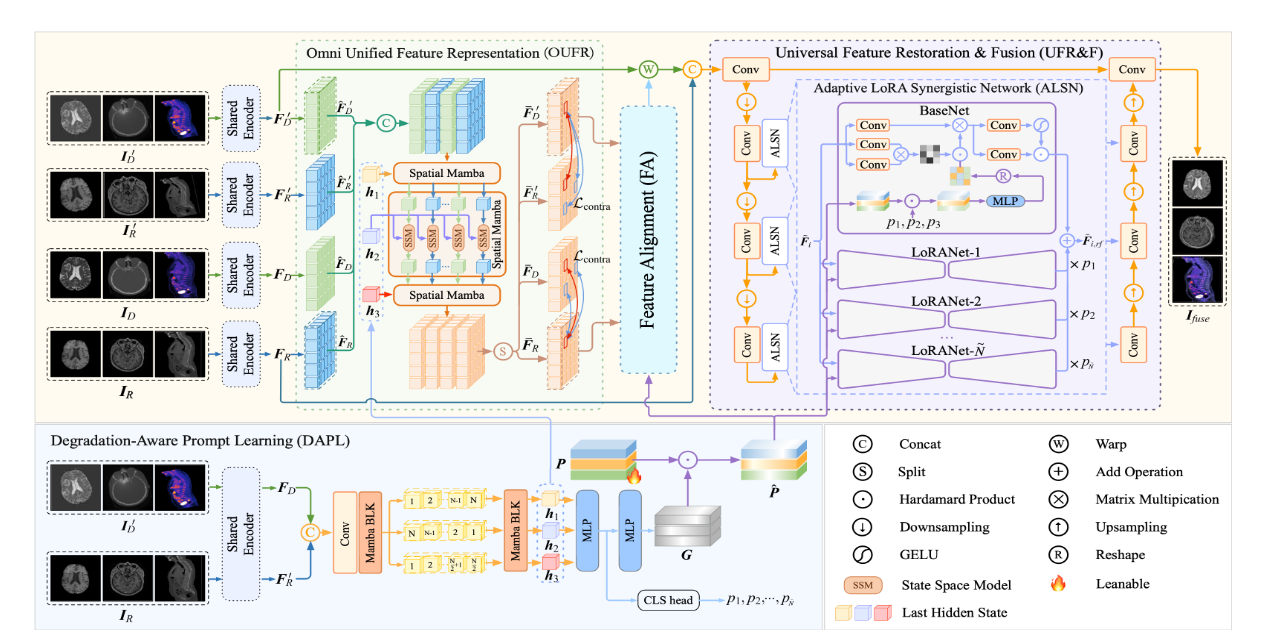
创新点:
-
提出了一种降解感知提示学习模块,在特征对齐、恢复和融合之间建立了强连接,使得这些任务能够在统一框架内进行协作训练。
-
设计了 Omni Unified Feature Representation方法,利用 Spatial Mamba 技术有效嵌入多方向信息,减少模态差异对特征对齐的影响。
-
提出了 Universal Feature Restoration & Fusion模块,借助 Adaptive LoRA Synergistic Network实现高效的特征恢复和融合,同时有效控制模型参数增长。
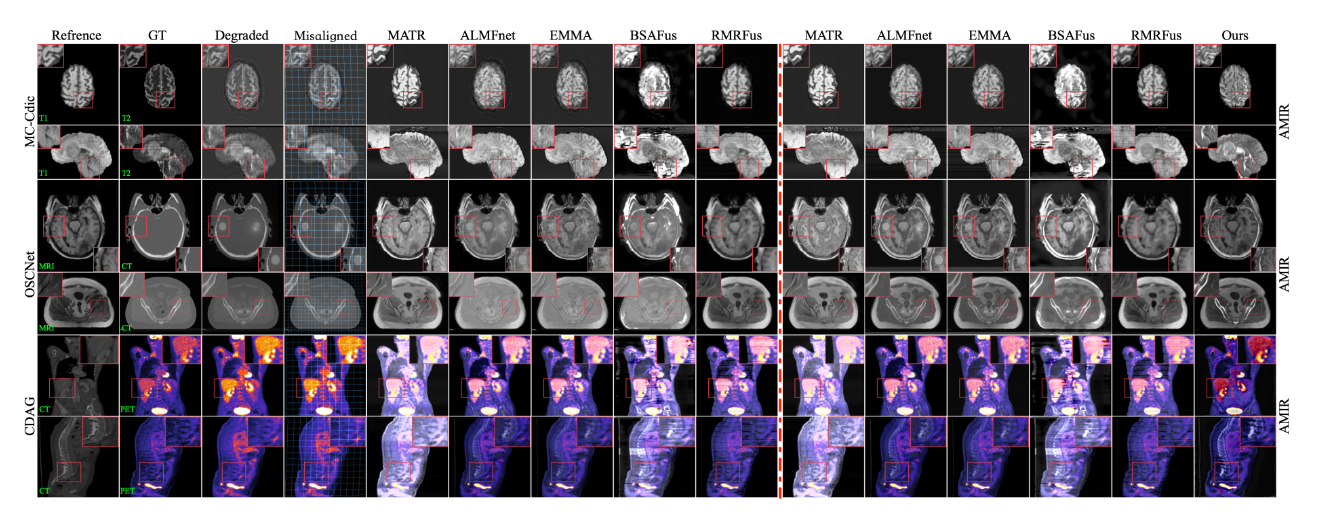
总结:这篇文章提出了一种名为 UniFuse 的统一框架,旨在解决多模态医学图像融合中常见的图像质量退化和像素错位问题,通过创新的模块设计,实现了在单一框架内完成对齐、恢复和融合任务。
VITA-PAR: VISUAL AND TEXTUAL ATTRIBUTE ALIGNMENT WITH ATTRIBUTE PROMPTING FOR PEDESTRIAN ATTRIBUTE RECOGNITION
方法:文章首先引入视觉属性提示来捕获从全局到局部的语义信息,然后设计了一个可学习的文本提示模板——人物和属性上下文提示,以丰富文本嵌入。接着,通过计算视觉和文本属性特征之间的余弦相似度实现视觉-文本属性对齐。在推理阶段,仅使用图像特征,从而在保持性能的同时提高了计算效率。
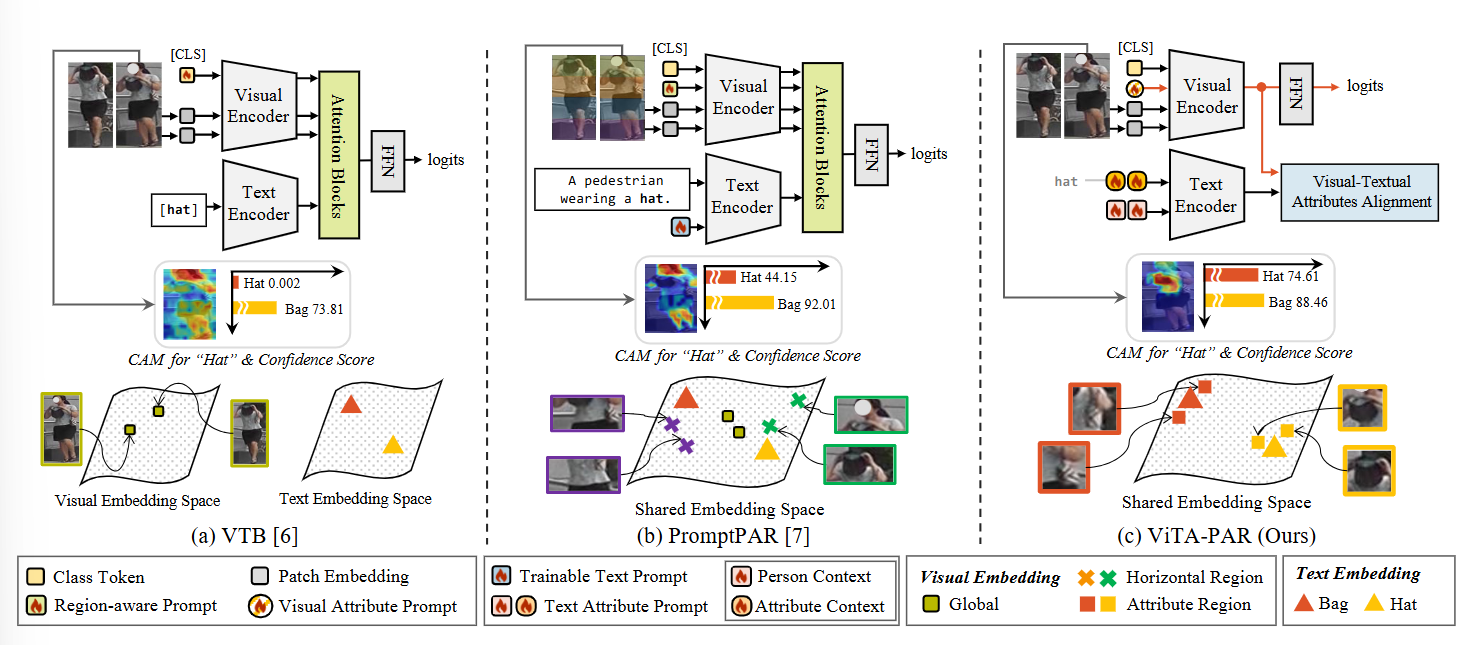
创新点:
-
提出了视觉和文本属性提示,通过视觉-文本属性对齐有效封装多模态属性语义。
-
引入了人物和属性上下文提示作为可学习的文本提示模板,能够捕捉人物和属性的详细特征。
-
在四个广泛使用的数据集上验证了 ViTA-PAR 的有效性,结果表明该方法在保持高准确率的同时,显著提高了推理速度。
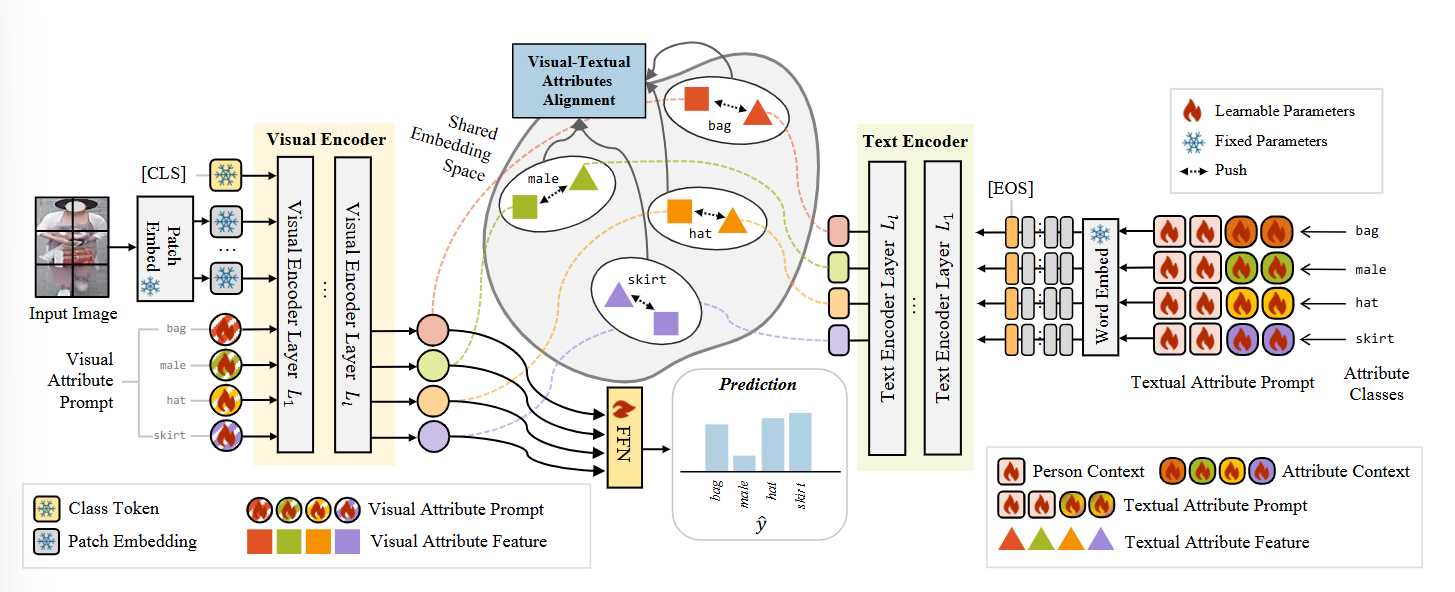
总结:这篇文章提出了一种名为 ViTA-PAR 的框架,用于行人属性识别(PAR),旨在通过视觉和文本属性提示以及视觉-语言对齐来增强属性识别性能,有效解决了现有方法在处理动态位置属性时的局限性。
需要了解更多最新研究趋势的同学,欢迎来gongzhonghao【图灵学术计算机论文辅导】
Multimodal Spatial Language Maps for Robot Navigation and Manipulation
方法:文章首先构建了视觉语言地图(VLMaps),将预训练的视觉语言特征与环境的三维重建相结合,实现了对自然语言指令的精准理解和执行。接着,通过扩展VLMaps,引入音频信息,构建了音频视觉语言地图(AVLMaps),进一步增强了机器人对多模态指令的理解能力。最后,通过跨模态推理方法,有效利用视觉、音频和语言信息,解决了目标定位中的歧义问题,使机器人能够在复杂环境中准确执行多模态指令。
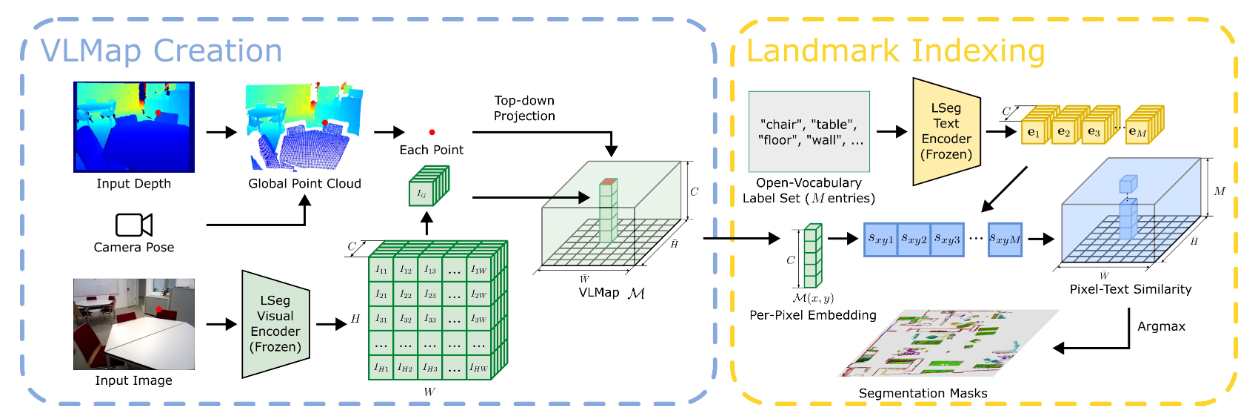
创新点:
-
提出了视觉语言地图和音频视觉语言地图,分别用于融合视觉与语言信息以及视觉、音频与语言信息。
-
引入了跨模态推理方法,通过计算不同模态热图的元素乘积,有效利用互补的多模态信息来解决目标定位中的歧义问题。
-
展示了该方法在模拟和真实世界环境中的有效性,特别是在处理模糊目标导航任务时,AVLMaps在目标定位的准确性和召回率上显著提升。
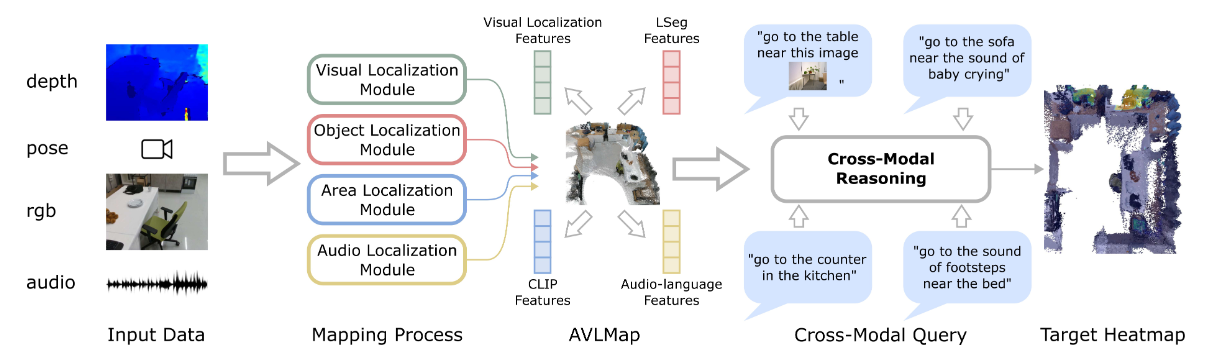
总结:这篇文章提出了一种多模态空间语言地图框架,用于机器人导航和操作任务,旨在通过融合预训练的多模态特征与环境的三维重建,实现对自然语言指令的精准理解和执行。
点击关注,快速拿捏更多计算机SCI/CCF发文资讯~