很多同学在学习目标检测时都会遇到IoU这个概念,但总觉得理解不透彻。这其实很正常,因为IoU就像个"多面手",在目标检测的各个阶段都要"打工",而且每个阶段的"工作内容"还不太一样。
今天我就让IoU自己来做个自我介绍,用最直白的话给大家讲讲它到底在忙些啥:
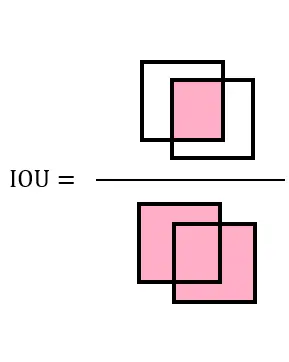
1. 训练阶段:我是“样本匹配的裁判”
我的任务:
-
判断预测框是否合格:当模型提出一个预测框(Bounding Box),我会计算它与真实框(Ground Truth)的重叠程度。
-
如果 IoU ≥ 0.5(阈值可调),我会认定这个预测框是“正确匹配”(正样本),模型会因此受到奖励(降低损失值)。
-
如果 IoU < 0.5,我会判定为“错误匹配”(负样本),模型需要继续优化。
-
-
指导损失函数:在 CIOU Loss、GIOU Loss 中,我的数值直接决定了模型优化的方向(框的位置回归)。
我的烦恼:
-
如果阈值设得太高(如 0.7),模型会变得“吹毛求疵”,导致训练困难;
-
如果阈值太低(如 0.3),模型可能“滥竽充数”,产生大量低质量预测。
2. 评估阶段:我是“性能的考官”
我的任务:
-
计算 mAP:在验证集或测试集上,我会对所有预测框进行严格考核:
-
mAP@0.5:只需 IoU ≥ 0.5 就算正确检测(宽松标准)。
-
mAP@0.5:0.95:从 0.5 到 0.95 逐步提高我的标准,考验模型在严苛条件下的表现(严格标准)。
-
-
生成 PR 曲线:通过调整置信度阈值,我会绘制 Precision-Recall 曲线,揭示模型的权衡能力。
我的高光时刻:
-
当模型的 mAP@0.5:0.95 很高时,说明它不仅能检测目标,还能精准定位边界框!
3. 推理阶段:我是“冗余框的清洁工”
我的任务:
-
配合 NMS(非极大值抑制):模型推理时会生成大量重叠的预测框,我的职责是:
-
计算所有框之间的 IoU,找出哪些框是重复的。
-
如果两个框的 IoU > NMS 阈值(默认 0.45),我会果断删除置信度较低的框,确保最终结果简洁。
-
-
应对极端情况:
-
密集小目标:需要降低 NMS 阈值(如 0.3),避免误删真实目标。
-
大目标重叠:提高阈值(如 0.6),防止过度合并。
-
我的吐槽:
-
有些模型在后处理时完全不用我(如端到端 DETR),让我失业了!
总结:我的核心价值
-
训练时:我是样本匹配的“标准答案”。
-
评估时:我是衡量模型能力的“公平尺子”。
-
推理时:我是优化结果的“过滤器”。
小伙伴们,现在通透了么,没通透就再思考思考,哈哈哈哈哈。