政安晨的个人主页:政安晨
欢迎 👍点赞✍评论⭐收藏
希望政安晨的博客能够对您有所裨益,如有不足之处,欢迎在评论区提出指正!
目录
DeepBeepMeep的WanGP:面向GPU资源有限用户的最佳开源视频生成模型
项目简介
本项目依托Wan2.1项目,咱们首先介绍 Wan2.1,这是一个全面且开源的视频基础模型套件,它突破了视频生成的边界。
(开源地址如下:https://github.com/Wan-Video/Wan2.1)
Wan2.1提供以下关键特性:
👍 最先进性能:Wan2.1在多个基准测试中始终优于现有的开源模型和最先进的商业解决方案。
👍 支持消费级GPU:T2V-1.3B模型仅需8.19 GB显存,兼容几乎所有消费级GPU。在RTX 4090上,它可以生成5秒480P视频,耗时约4分钟(无量化等优化技术)。其性能甚至可与一些闭源模型相媲美。
👍 多任务能力:Wan2.1在文本到视频、图像到视频、视频编辑、文本到图像和视频到音频任务中表现出色,推动了视频生成领域的进步。
👍 视觉文本生成:Wan2.1是首个能够生成中英文文本的视频模型,具备强大的文本生成功能,显著增强了实际应用价值。
👍 强大的视频VAE:Wan-VAE提供卓越的效率和性能,能够编码和解码任何长度的1080P视频,同时保留时间信息,是视频和图像生成的理想基础。


WanGP:
DeepBeepMeep的WanGP:面向GPU资源有限用户的最佳开源视频生成模型
WanGP支持Wan(及其衍生模型)、Hunyuan视频和LTV视频模型,并提供以下关键功能:
- 低显存需求:某些模型仅需低至6GB显存即可运行。
- 旧款GPU兼容性:支持RTX 10系列、20系列等旧款显卡。
- 最新GPU高性能:在最新GPU上运行速度极快。
- 易用性:提供完整基于Web的界面,操作简便。
- 模型自动适配:自动下载并适配您特定硬件架构的模型。
- 集成视频生成工具:包括掩码编辑器、提示增强器、时空生成、MMAudio、视频浏览器、姿态/深度/流提取器,以简化视频生成流程。
- LoRA支持:支持LoRA技术以自定义每个模型。
- 队列系统:允许创建视频生成任务列表,用户可稍后返回查看结果。
项目地址:https://github.com/deepbeepmeep/Wan2GP
这个项目是一套方便的工具体系,我们使用这套工具可以利用AI便捷地生成各类视频内容媒体。

本项目在快速发展,在生产视频媒体上非常灵活与出色,我们现在开始部署:
下载项目
目前该项目还没有版本tag,我们直接下载:
git clone https://github.com/deepbeepmeep/Wan2GP.git
创建虚拟环境
cd Wan2GP# Create Python 3.10.9 environment using conda
conda create -n wan2gp python=3.10.9
conda activate wan2gp
# Install PyTorch 2.6.0 with CUDA 12.4
pip install torch==2.6.0 torchvision torchaudio --index-url https://download.pytorch.org/whl/test/cu124 安装PyTorch
时间比较长,喝杯咖啡。
安装依赖
# Install core dependencies
pip install -r requirements.txt
因为该项目在快速发展,所以,今后更新项目代码后,可以使用下面的方式重新更新依赖:
git pull
pip install -r requirements.txt项目依赖安装完毕:
运行项目
python wgp.py # Text-to-video (default)
python wgp.py --i2v # Image-to-video我们先运行一下文生视频的服务:
python wgp.py
因为显存问题,出现一些警告,可以暂时忽略。
服务运行起来之后,小伙伴们已经可以看到服务地址了:http://localhost:7860
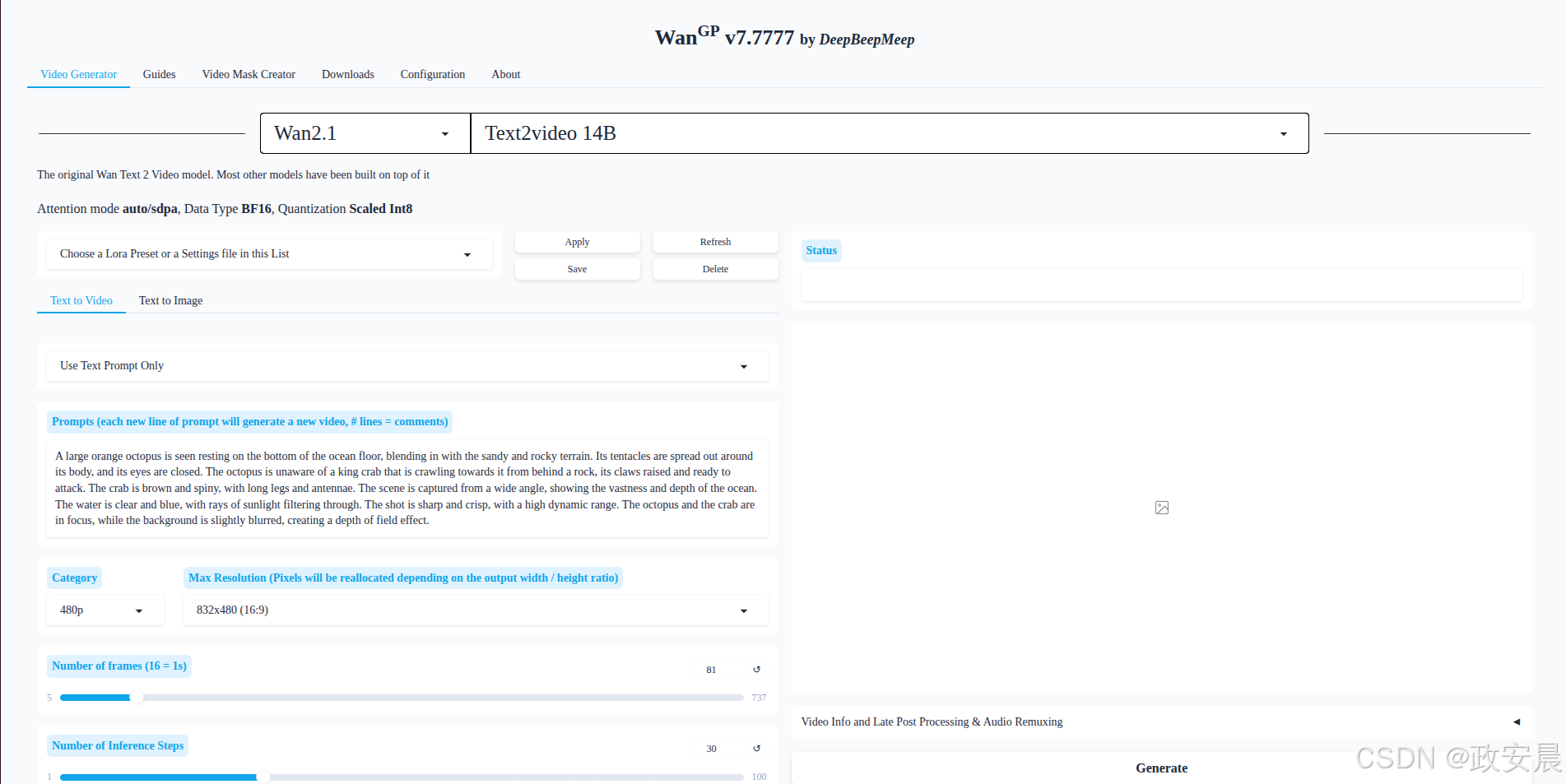
使用默认参数第一次生成时会自动下载模型:

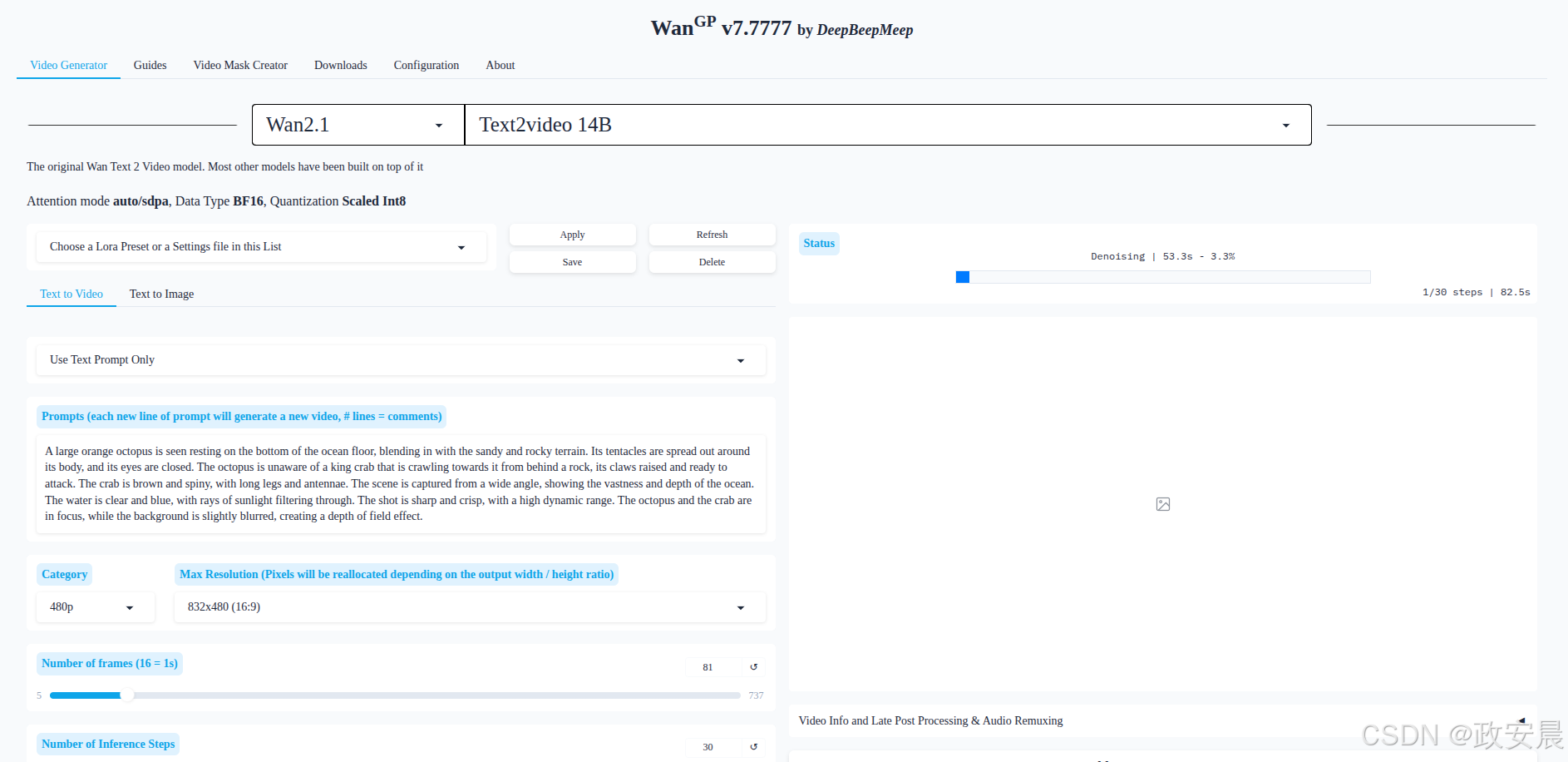
模型下载完成后,WanGP服务开始推理:
优化方案
没有经过优化时,速度会比较慢,可以采用优化方案如下:
方案一:(速度提高30%)
# Windows only: Install Triton
pip install triton-windows
# For both Windows and Linux
pip install sageattention==1.0.6 方案二:(速度提高40%)
# Windows
pip install triton-windows
pip install https://github.com/woct0rdho/SageAttention/releases/download/v2.1.1-windows/sageattention-2.1.1+cu126torch2.6.0-cp310-cp310-win_amd64.whl
# Linux (manual compilation required)
python -m pip install "setuptools<=75.8.2" --force-reinstall
git clone https://github.com/thu-ml/SageAttention
cd SageAttention
pip install -e .我们基于Linux系统,选择方案一。
这里我们先测试一下没有经过优化的速度:

默认提示词,总共用时:16分56秒
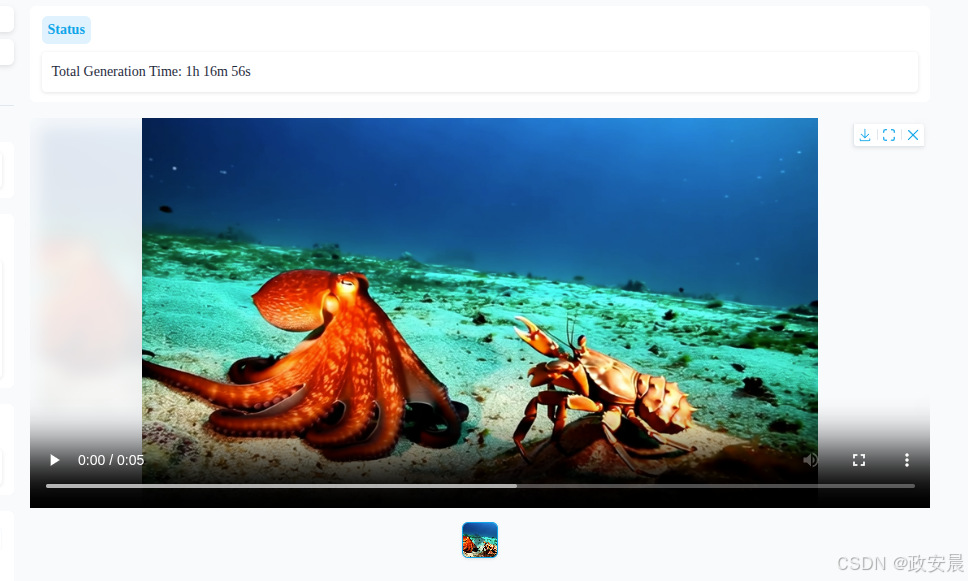

大家可以看到,视频生成总共用了16分56秒,即:1016秒。
我们现在进行优化:
先把服务退出:

因为我是linux系统,所以执行:
pip install sageattention==1.0.6 
再次运行服务:

重新执行视频生成任务:
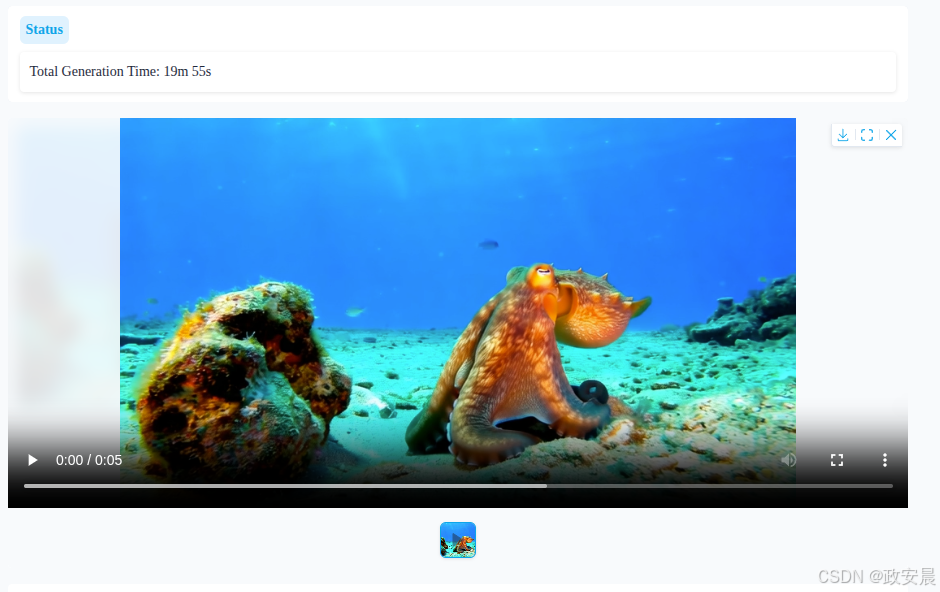
发现时间反而增加到了19分55秒。
现在看来,性能并没有因为这个注意力机制而显著提升,当然也和我的提示词及其相关配置有关,更重要的是显存大小,这个限制了一定瓶颈之后,其它机制上的提升也许会带来相反效果,这个细节咱们后续讨论,本篇主要是部署运行。
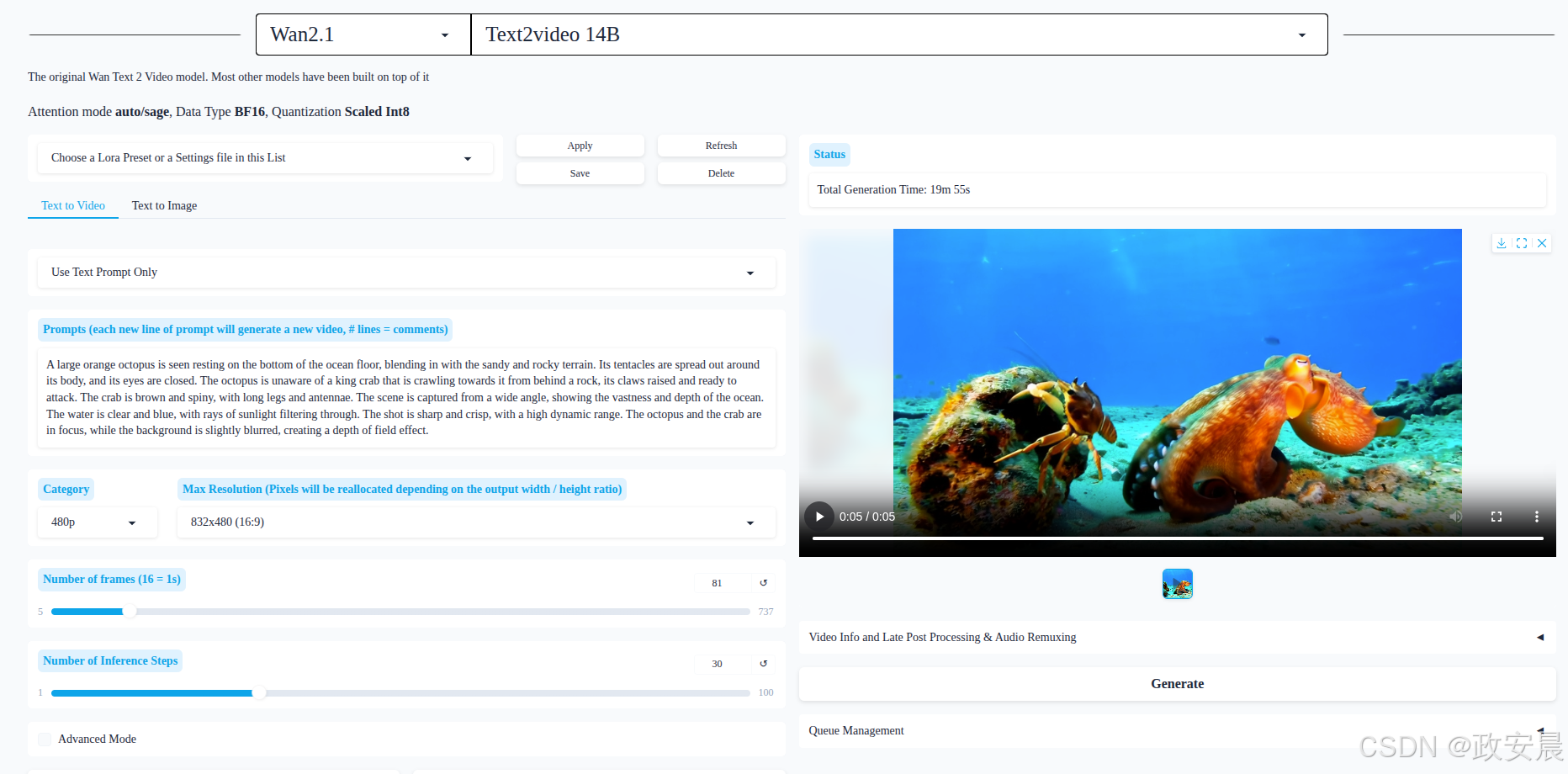
我再测试项目中的另外一个性能优化配置(基于方案二):
# May require CUDA kernel compilation on Windows
pip install flash-attn==2.7.2.post1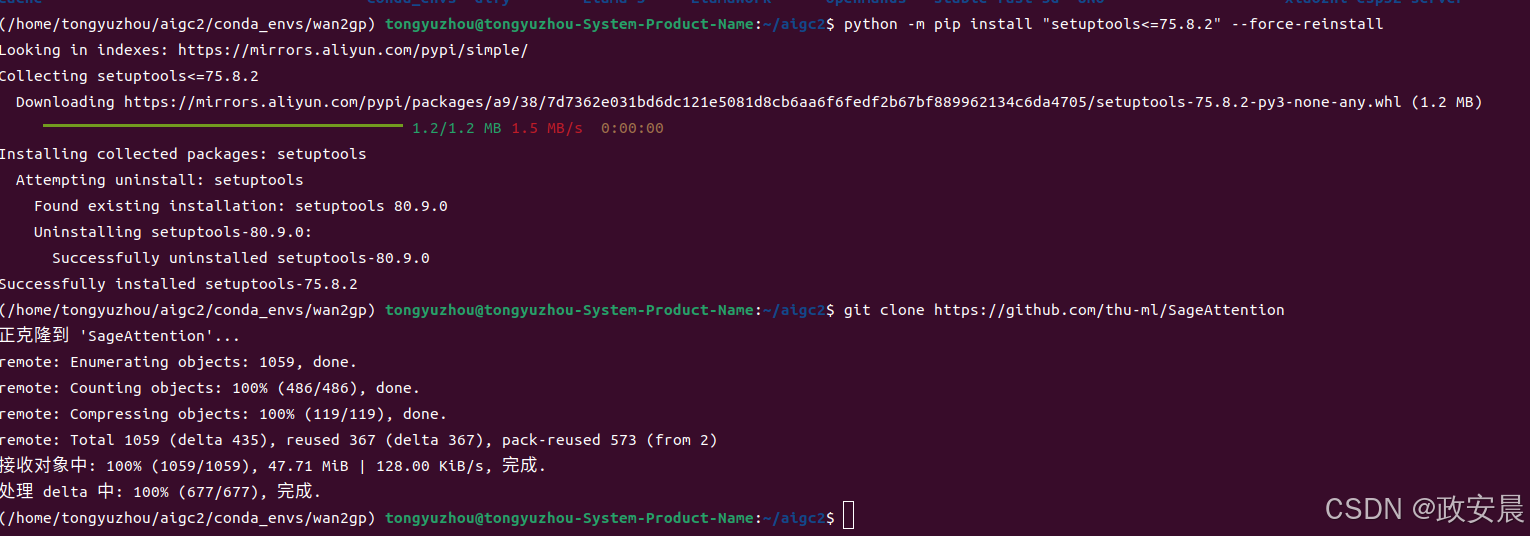
发现这个方案不仅在Windows下要重新编译kernel,Linux也是一样,因为本篇仅为部署使用展示,后续专门针对这些优化问题再为各位小伙伴们汇报。嘻嘻。
至此,我们完整演示了从部署到使用再到优化的WanGP视频生成框架工具的使用,祝大家玩得愉快,谢谢!