目录
预训练Transformer模型:Sentence-BERT
文本语义相似度匹配
-
文本语义相似度匹配是自然语言处理(NLP)领域的核心任务,其目标是量化两段文本在语义层面的相似程度。
-
与简单的字面匹配不同,语义相似度关注的是文本背后所表达的概念一致性和语义关联性。
-
例如,"我喜欢吃苹果"和"苹果是我爱吃的水果"虽然字面重叠度低,但语义高度相似;而"苹果手机很贵"和"这个苹果很甜"虽然都有"苹果"一词,但语义截然不同。

计算方法

传统方法:基于字符串的方法
- 这类方法将文本视为字符序列,严格依赖于字面匹配。
- 编辑距离: 计算将一个字符串转换为另一个字符串所需的最少单字符编辑(插入、删除、替换)次数。距离越小,越相似。

- Jaccard相似系数: 将文本视为词的集合,计算两个集合的交集与并集的比值。
- Ø相似度 = (A ∩ B) / (A ∪ B)

传统方法:基于词袋模型
-
这类方法将文本表示为向量,然后计算向量间的距离或相似度。
-
TF-IDF + 余弦相似度:
-
TF-IDF: 将每篇文本表示成一个高维向量,向量的每个维度代表一个词,权重由TF(词频)和IDF(逆文档频率)共同决定。TF-IDF可以评估一个词对于一份文档的重要程度。
-
余弦相似度: 计算两个TF-IDF向量在空间中的夹角余弦值。值越接近1,表示两个向量方向越一致,文本越相似。相似度 = (A · B) / (||A|| * ||B||)

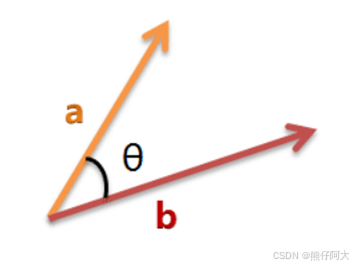
TF-IDF 把每篇文档变成一个“关键词重要性向量”,余弦相似度计算两个向量的“夹角”——夹角越小,方向越一致,文本越相似!

深度学习方法:Word2Vec
-
“词的意思,由它周围的词决定。”
-
Word2Vec包含两个模型,即跳元模型和连续词袋模型。它们的训练依赖于条件概率,条件概率可以被看作使用语料库中一些词来预测另一些单词。由于是不带标签的数据,因此跳元模型和连续词袋都是自监督模型。因此,Word2Vec的计算效果一定程度上取决于语料库的完整的全面,特定场景使用时可能需要对语料库进行补充和完善。计算方法是把每个词变成一个稠密向量(比如 100 维),语义相近的词,向量也相近!
-
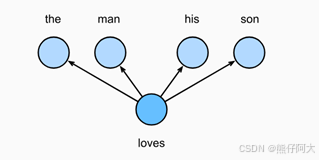
跳元模型假设一个词可以用来在文本中生成其周围的单词。例如:{“the”,“man”,“loves”,“his”,“son”}中心词为“loves”,跳元模型考虑生成上下文词“the”,“man”,“his”,“son”的条件概率。
-
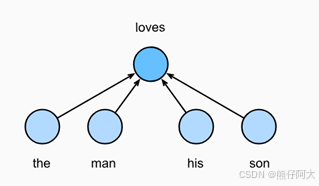
连续词袋模型类似于跳元模型,区别在于,连续词袋模型假设中心词是基于其在文本序列中的周围上下文词生成的,即基于上下文词“the”,“man”,“him”,“son” 生成中心词“loves”的条件概率。
-
局限性:
-
如果一个词没在训练数据中出现过,模型不认识它,词向量为0向量,相似度计算无效。
-
一词多义问题:比如“苹果”(可能是水果的苹果,也可能是苹果公司),Word2Vec 只给一个向量,可能混淆。
-
预训练Transformer模型:BERT
-
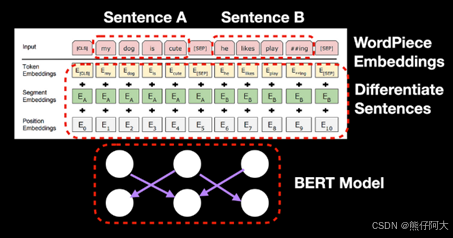
BERT 同时利用左侧和右侧的上下文来表示一个词。例如,在句子 “榴莲味道很浓” 中,“味道”的含义依赖于整个句子的上下文,BERT 完全基于 Transformer 的编码器部分,利用自注意力机制(Self-Attention)建模词与词之间的依赖关系。
-
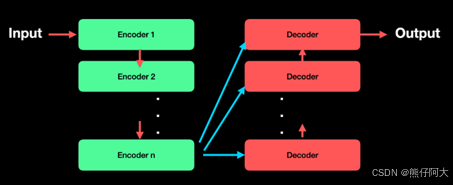
理解BERT:传统的基于Transformer模型架构设计的模型其结构包含编码器( Encoder )和解码器(Decoder),并各自多层堆叠,每层包含多头子注意力和前馈网络等,其输入、输出均为具体的内容; BERT是一个具体的预训练模型,其基于Transformer的编码器进行构建,输出内容为编码器的结果,即通过模型编码后的向量,其本质是对输入文本做预测。例如:两个相似的文本,预测的结果理论上也是相似的。表现到向量上,方向也会是相同或接近的。
-
相较于传统方式和深度学习方式,嵌入式模型可以理解上下文关系,在文本的语义层面上的表示更具优势。
-
模型下载:
-
BERT相关理论和案例代码资料:
-
https://arxiv.org/pdf/1810.04805
https://arxiv.org/pdf/1810.04805
-
https://www.runoob.com/nlp/bert-encoder.html
-
https://developer.aliyun.com/article/1683966
预训练Transformer模型:Sentence-BERT
-
Sentence-BERT 是基于 BERT / RoBERTa 的孪生网络,与BERT类似,都是基于 Transformer 的语言模型,但在设计目标、结构和应用场景上存在差异 。
-
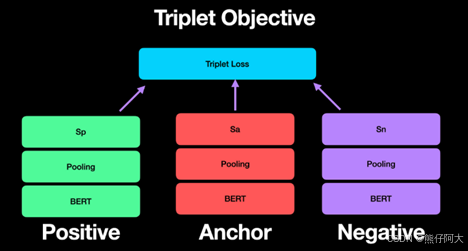
Sentence-BERT生成的是句子级嵌入,即句向量,它可以直接得出语义相近的句子在向量空间中距离更近。 结构上Sentence-BERT使用三元组目标结构,用于学习两个输入之间的相似性或距离关系,同时在BERT基础上,使用监督学习微调,目标函数直接针对句子嵌入的相似度,因此,在句子级别的语义匹配任务中相较BERT更具优势。
特性
原始 BERT
Sentence-BERT
句向量质量
需手动池化
专为句向量优化
相似度计算
需微调或后处理
开箱即用,直接余弦相似度
速度
较慢
快(可批量编码)
-
相关资料:
-
https://arxiv.org/abs/1908.10084
-
常用模型:
-
all-MiniLM系列(轻量,速度快,效果好)
-
all-distilroberta-v1(基于 RoBERTa,速度快于 BERT)
-
paraphrase-multilingual-MiniLM-L12-v2(工业常用)
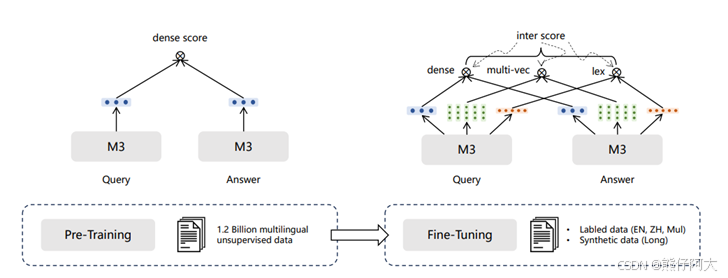
预训练Transformer模型:BGE-M3
-
BGE-M3 与 Sentence-BERT类似,都是基于BERT,用于生成句子嵌入的模型,但它们功能性、训练方式等方面存在显著差异,同时。 BGE-M3的模型参数更大、训练数据更丰富、支持文本输入更长。
-
BGE-M3 模型亮点(“三多”):
-
多语言:训练集包含100+种以上语言。
-
多功能:支持稠密检索(使用高维、稀疏的向量(通常是词袋模型或其变体)表示查询和文档)、稀疏检索(将查询和文档编码为低维、稠密的连续向量(通常为 768 维或更高))与多向量检索(用多个向量(如每个词、每个句子或每个段落一个向量)来更精细地表示内容)。
-
多粒度: BGE-M3可以处理最大长度为8192 的输入文本,支持“句子”、“段落”、“篇章”、“文档”等不同粒度的输入文本。
-
模型训练阶段主要包括预训练和微调,同时采用了大量无监督对比学习,微调阶段引入三种不同的匹配路径(稠密、稀疏和多向量),从而综合考虑了文本的语义(dense)、局部细节(multi-vec)以及词法线索(lex)。
-
相较Sentence-BERT, BGE-M3在基础参数、训练策略、适应的文本类型、输入文本长度等方面都更具优势。
-
BGE-M3相关资料:
-
https://arxiv.org/abs/2402.03216
-
https://bge-model.com/bge/bge_m3.html
测试案例
测试目标:确定current_alarm匹配alarm_case_library的最佳计算方案。(面对大量案例需要检索是大模型效率及计算资源消耗问题,本次测试暂不包含大模型方法,一般该类任务大模型以外方法可以完成处理)
测试方式:基于current_alarm,从alarm_case_library匹配到最相似的或对相似性进行排序。
测试数据:构建多个模拟的测试数据(如下图)。
评估角度:①主体(X设备)是否匹配;②内容(温度xxx、压力xxx)是否匹配;③语义是否相关(温度上升/下降)。

结果对比
分别采用传统方法(TF-IDF + 余弦相似度(结果A)) 、预训练模型方法(bge-m3模型+bge-reranker-v2-m3重排序模型(结果B))结果的相似度排名前5进行对比说明;词向量模型涉及文本语料库庞大,资源消耗量巨大且严重依赖词库,不考虑。


-
A结果可以明显观察到,其更偏向于每个文本特有词汇,致使排名靠前的案例均为“反应釜”相关案例,第3个案例中温度并未偏高,对于异常报警所反映的“温度异常升高”现象显然存在偏差,但总体基本都属于相似案例;
-
B结果中相较A结果,保持了“反应釜”的主语检索,同时,相似度排名靠前的案例均涉及“温度骤升”、“温度持续升高”等字样,相较于A结果,存在更深层次的相关性。