一、深度学习经典检测方法
two-stage(两阶段):Faster-rcnn Mask-Rcnn系列
one-stage(单阶段):YOLO系列
1. one-stage

最核心的优势:速度非常快,适合做实时检测任务!
但是缺点也是有的,效果通常情况下不会太好!
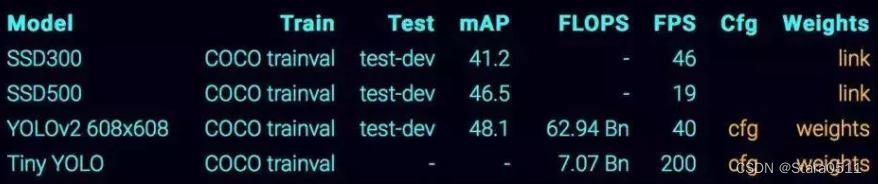
2. two-stage
速度通常较慢(5FPS),但是效果通常还是不错的!
非常实用的通用框架MaskRcnn
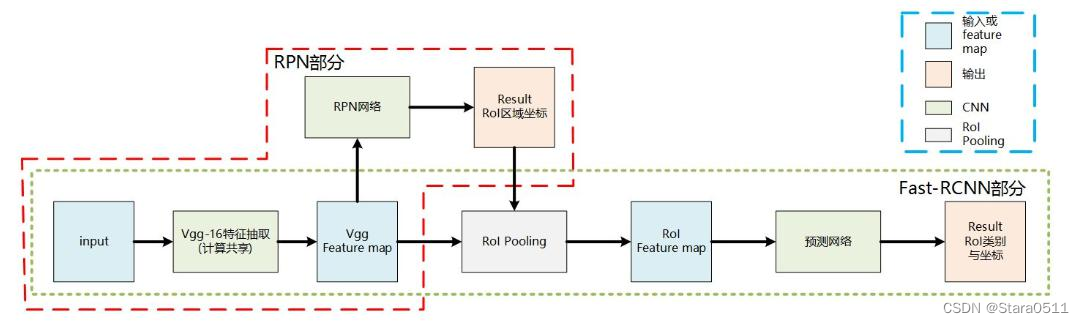
二、指标分析
1. IOU:交集(真实值和预测值)/并集
2. P-R图
精度和召回率计算



精度是指模型正确预测为正例的样本数量与所有被模型预测为正例的样本数量的比率。换句话说,精度衡量了模型的预测中有多少是真正的正例。
召回率是指模型正确预测为正例的样本数量与所有实际正例的样本数量的比率。召回率衡量了模型能够正确识别多少真正的正例。
3. map指标:综合衡量检测效果;
举个例子。设定第一张图的预测框叫pre1,第一张的真实框叫label1。第二张、第三张同理。

(1)根据IOU计算TP,FP
首先我们计算每张图的pre和label的IOU,根据IOU是否大于0.5来判断该pre是属于TP还是属于FP。显而易见,pre1是TP,pre2是FP,pre3是TP。
(2)置信度排序
根据每个pre的置信度进行从高到低排序,这里pre1、pre2、pre3置信度刚好就是从高到低。
(3)在不同置信度阈值下获得Precision和Recall
- 首先,设置阈值为0.9,无视所有小于0.9的pre。那么检测器检出的所有框pre即TP+FP=1,并且pre1是TP,那么Precision=1/1。因为所有的label=3,所以Recall=1/3。这样就得到一组P、R值。
- 然后,设置阈值为0.8,无视所有小于0.8的pre。那么检测器检出的所有框pre即TP+FP=2,因为pre1是TP,pre2是FP,那么Precision=1/2=0.5。因为所有的label=3,所以Recall=1/3=0.33。这样就又得到一组P、R值。
- 再然后,设置阈值为0.7,无视所有小于0.7的pre。那么检测器检出的所有框pre即TP+FP=3,因为pre1是TP,pre2是FP,pre3是TP,那么Precision=2/3=0.67。因为所有的label=3,所以Recall=2/3=0.67。这样就又得到一组P、R值。
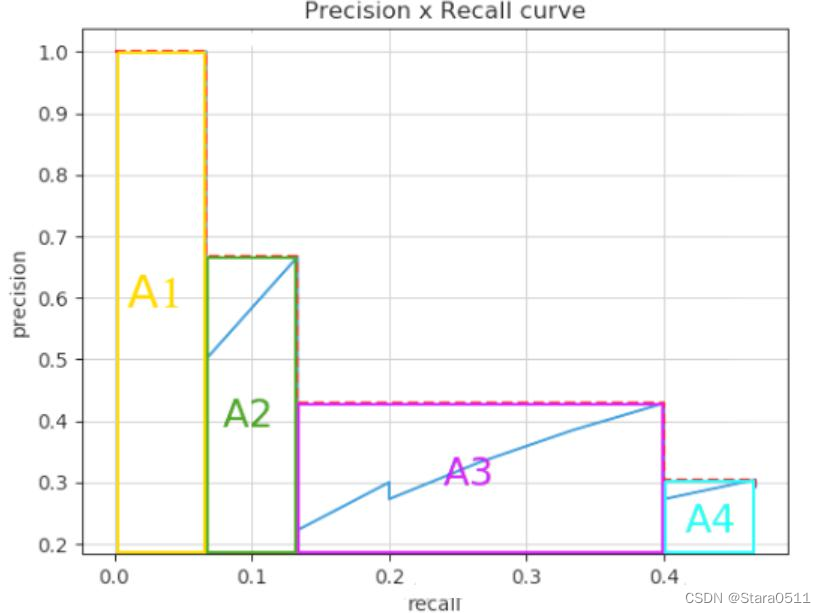
(4)绘制PR曲线并计算AP值
根据上面3组PR值绘制PR曲线如下。然后每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是AP值。
(5)计算mAP
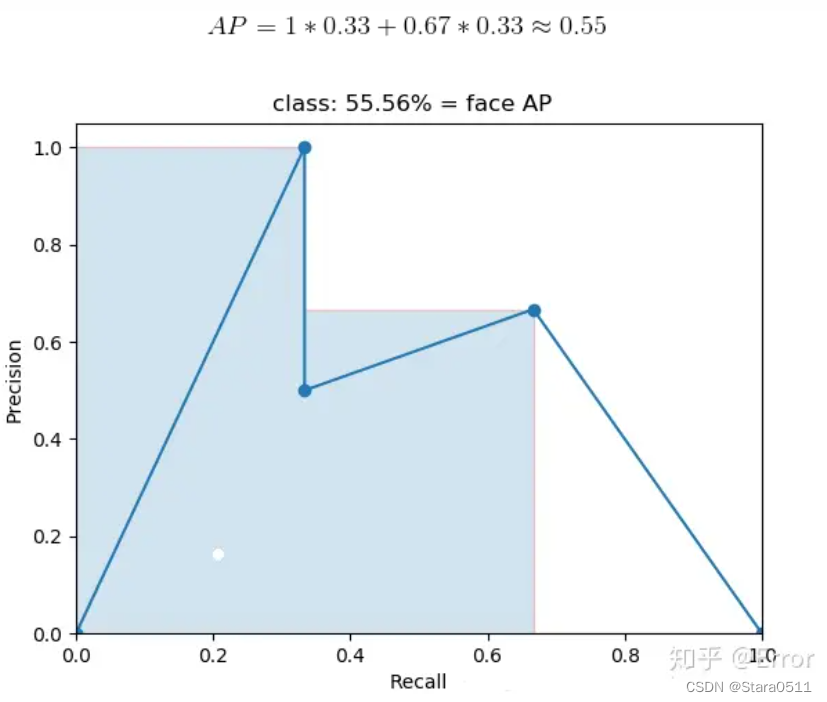
AP衡量的是对一个类检测好坏,mAP就是对多个类的检测好坏。就是简单粗暴的把所有类的AP值取平均就好了。比如有两类,类A的AP值是0.5,类B的AP值是0.2,那么mAP=(0.5+0.2)/2=0.35
mAP值越大表明,该目标检测模型在给定的数据集上的检测效果越好。