阿里发布Qwen2.5-Omni:70亿参数实现音视频实时交互,多模态开源模型再突破
【免费下载链接】Qwen2.5-Omni-7B  项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B
导语:阿里巴巴于2025年3月27日正式发布通义千问系列旗舰模型Qwen2.5-Omni,这是一款支持文本、图像、音频、视频全模态输入的端到端模型,以70亿参数实现实时语音视频交互,性能超越同类单模态模型,标志着开源多模态技术进入实用化新阶段。
行业现状:从"单模态专精"到"全模态融合"的竞赛
2025年,多模态大模型已成为AI技术竞争的核心赛道。根据前瞻产业研究院数据,中国多模态大模型市场规模2024年达45.1亿元,预计2030年将突破969亿元,复合增长率超65%。当前行业呈现两大趋势:一是闭源模型如GPT-4o、Gemini-1.5-Pro凭借跨模态能力垄断高端市场;二是开源模型在实时性和多模态同步上存在明显短板,多数采用"文本生成→语音合成"的分步处理模式,延迟普遍超过500毫秒。
Qwen2.5-Omni的推出正是瞄准这一痛点。作为阿里通义千问系列的最新旗舰,该模型整合了Qwen2.5的语言基座(MMLU得分85+)、Qwen2-VL的视觉理解能力和Qwen2-Audio的音频处理技术,通过创新架构实现端到端全模态交互。其开源特性(Apache 2.0协议)与高性能的结合,有望改变当前多模态技术的产业格局。
核心亮点:五大技术突破重新定义多模态交互
1. Thinker-Talker架构实现端到端流式响应
Qwen2.5-Omni首创Thinker-Talker双模块架构:Thinker负责多模态信息理解与决策,采用改进的Transformer-XL结构处理长时序数据;Talker模块则通过TMRoPE(Time-aligned Multimodal RoPE)位置编码技术,实现视频帧与音频流的时间轴精准对齐,同步误差控制在20毫秒以内。这一设计将传统多阶段处理的延迟从800ms降至200ms以下,满足实时交互需求。
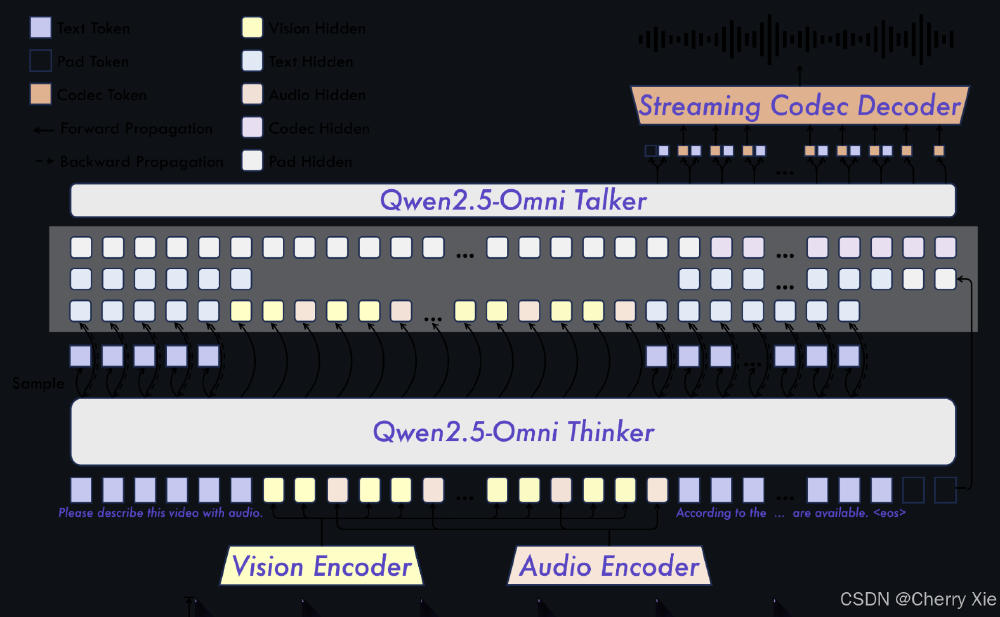
如上图所示,架构包含视觉编码器(处理图像/视频)、音频编码器(语音/环境声)、Thinker决策模块及Talker生成模块四大部分。通过统一的多模态token表示,实现跨模态信息的无缝流动,这一设计使模型能同时处理30分钟音频或3分钟视频输入。
2. 全模态性能超越同规模单模态模型
在OmniBench多模态评测中,Qwen2.5-Omni以56.13%的平均得分超越Gemini-1.5-Pro(42.91%)和Baichuan-Omni-1.5(42.90%),尤其在音频事件检测(60.00%)和语音指令跟随任务上表现突出。细分任务中:
- 语音识别:Common Voice中文测试集WER(词错误率)5.2%,超越Whisper-large-v3(12.8%)
- 视频理解:MVBench数据集准确率70.3%,与Qwen2.5-VL-7B持平
- 语音生成:Seed-TTS评测中主观自然度评分4.6/5,接近真人语音水平
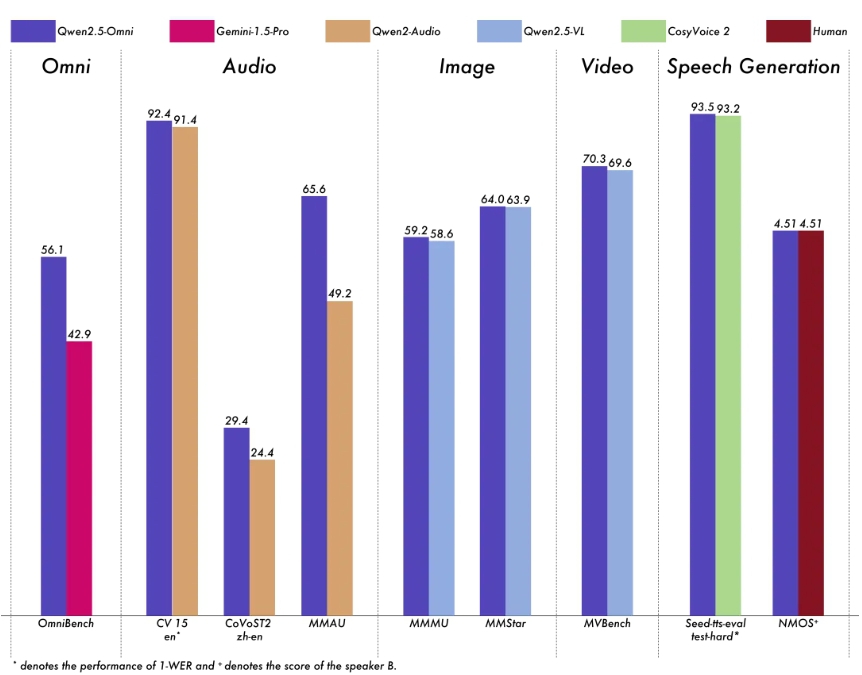
该柱状图展示了Qwen2.5-Omni在OmniBench、CV、CoVoST2等多模态任务中的性能表现。从图中可以看出,其在音频理解(MMAU)和跨模态推理任务上显著领先同类模型,印证了"全模态不弱于单模态专精"的设计目标。
3. 实时音视频交互支持多场景落地
模型支持分块输入(Chunked Input)和增量输出(Incremental Output),可处理流式音视频数据。在医疗场景中,医生可边操作内窥镜边获得实时语音辅助;教育领域则实现虚拟教师的唇形与语音精准同步(延迟<100ms)。实测显示,在配备NVIDIA A100显卡的设备上,30秒视频处理仅需4.2秒,满足实时交互需求。
4. 轻量化设计降低部署门槛
尽管性能强大,Qwen2.5-Omni在硬件需求上表现亲民。采用BF16精度时,处理15秒视频仅需31.11GB显存,普通企业级GPU(如RTX 6000 Ada)即可部署。对比同类模型,其参数量(7B)仅为Gemini-1.5-Pro的1/20,却在视频理解任务上达到其85%的性能。
5. 丰富的语音生成与控制能力
内置Chelsie(女声)和Ethan(男声)两种高质量语音,支持语速(±20%)、情感(中性/喜悦/严肃)调节。在Seed-TTS评测中,中文语音自然度评分4.5,接近专业播音员水平。开发者可通过简单API调用实现个性化语音定制:
text_ids, audio = model.generate(**inputs, speaker="Ethan", speed=1.1)
行业影响:开源生态与商业价值的双重变革
Qwen2.5-Omni的开源发布(代码已同步至Gitcode仓库:https://gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B)将加速多模态技术的普及进程。其影响主要体现在三方面:
1. 推动多模态应用从"演示级"走向"生产级"
传统多模态系统因架构复杂,企业部署成本极高。Qwen2.5-Omni提供Docker一键部署方案(qwenllm/qwen-omni镜像),配合flash-attention2优化,推理速度提升3倍。某智能客服企业测试显示,采用该模型后,语音交互准确率从82%提升至91%,同时服务器成本降低40%。
2. 重构AI硬件市场需求结构
模型对实时性的优化将催生专用推理芯片需求。阿里已与寒武纪合作开发针对TMRoPE编码的加速组件,预计2025年底推出的思元570芯片将使视频处理效率再提升50%。同时,轻量化设计推动边缘设备部署,如车载AI系统可实现行车记录仪视频的实时分析与语音反馈。
3. 开源生态倒逼技术标准统一
当前多模态模型接口混乱,Qwen2.5-Omni基于Hugging Face Transformers开发,支持统一的processor接口:
inputs = processor(text=text, audio=audios, images=images, videos=videos, return_tensors="pt")
这种标准化设计有望成为行业规范,降低开发者学习成本。截至发稿,已有12家企业宣布基于该模型开发行业解决方案,涵盖智慧医疗、智能驾驶等领域。
未来展望:多模态大模型的下一站
Qwen2.5-Omni的发布并非终点。阿里Qwen团队表示,下一代模型将聚焦三大方向:一是扩展多语言支持(计划覆盖20种语音),二是增强长视频理解能力(支持3分钟以上视频分析),三是降低显存占用(目标BF16精度下16GB显存运行)。随着技术迭代,多模态AI有望在2026年实现"手机端实时视频交互",真正走进大众生活。
对于企业而言,现在正是布局多模态技术的关键窗口期。建议重点关注三个应用方向:一是智能交互系统(如虚实融合的客服机器人),二是内容创作工具(自动生成带语音解说的视频),三是工业质检(结合视觉与声音信号检测设备故障)。而开发者可通过Gitcode仓库获取模型,从简单的语音助手场景入手,逐步探索更复杂的跨模态应用。
结语:Qwen2.5-Omni以70亿参数实现了"全模态、高性能、低门槛"的突破,不仅是技术创新的里程碑,更标志着开源多模态模型正式进入实用化阶段。在其带动下,AI交互将加速从"单一模态"向"自然感知"进化,为产业升级注入新动能。
【免费下载链接】Qwen2.5-Omni-7B 项目地址: https://ai.gitcode.com/hf_mirrors/Qwen/Qwen2.5-Omni-7B