Firecrawl教程①:自动化抓取与数据转化,赋能AI应用
前言
- 在如今的技术生态中,如何快速、有效地获取并利用网站上的信息变得尤为重要。尤其是在人工智能(AI)和大语言模型(LLM)的应用不断扩展的背景下,能够将一个网站的内容转化为机器学习模型可以直接使用的格式,已成为一种新的需求。
- Firecrawl 是一个 API 服务,它支持将整个网站内容抓取下来并转化为多种格式,包括清晰的 Markdown、结构化数据、HTML 等,能够有效地绕过复杂的反爬虫机制,抓取并提取动态页面内容。
- 通过 Firecrawl,我们可以轻松地将网站转换为 LLM 可以处理的数据格式,为下一步的人工智能任务打下坚实的基础。
一、功能特点
1. 支持 LLM 就绪格式
Firecrawl 能够将抓取的网页转化为以下几种格式:
- Markdown:符合 LLM 训练的清洁文本格式,适用于大多数 AI 模型。
- HTML:原始的网页结构,可以方便地进行进一步处理。
- 结构化数据:通过 LLM 提取的结构化数据,便于进行分析和应用。
- 屏幕截图:提供可视化的网页截图,帮助分析和验证数据抓取的准确性。
2. 全面抓取网站
Firecrawl 不仅支持抓取单个网页,还能够抓取整个网站的所有可访问页面,并生成网站的完整内容,包括内部链接、元数据、标题等。通过 Firecrawl,我们无需提交站点地图,它会自动识别并抓取网站中的所有子页面。
3. 强大的操作支持
Firecrawl 提供了一套可以在抓取前后对页面进行操作的功能。例如,我们可以通过模拟用户点击、填写表单、滚动页面等操作,来抓取动态生成的内容。对于需要用户交互或页面加载的情况,Firecrawl 也能提供精准的数据抓取。
4. 灵活的定制选项
用户可以根据需求灵活配置 Firecrawl 的抓取参数。比如,我们可以设置抓取的最大深度、排除特定标签或路径、调整抓取的频率等,以确保抓取过程高效且符合我们的特定需求。
5. 支持多种编程语言 SDK
Firecrawl 提供了 Python、Node.js、Go 和 Rust 等语言的 SDK,便于开发者在不同环境中集成和使用。此外,还支持流行的低代码框架,如 Langchain、Dify、Flowise 等,简化了集成的复杂度。
二、如何开始使用 Firecrawl
接下来,我们将通过一些实操的例子来展示如何使用 Firecrawl API,快速抓取并获取网站数据。
第一步:获取 API 密钥
要使用 Firecrawl,我们首先需要注册并获取一个 API 密钥,访问 Firecrawl 官网(https://firecrawl.dev)进行注册。
第二步:安装 Firecrawl
然后,我们选择使用 Python 作为开发语言,通过以下命令安装:
pip install firecrawl-py
第三步:抓取网页
Scrape模式
将网页转换为 markdown,非常适合 LLM 应用程序。
- 支持代理、缓存、速率限制、js 阻止的内容。
- 支持处理动态网站、js 渲染的网站、PDF、图像。
- 支持输出干净的 markdown、结构化数据、屏幕截图或 html。
有关详细信息,请参阅 Scrape Endpoint API。
Firecrawl 安装成功后,执行以下代码,进行快速抓取网站内容:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key='your API key')
response = app.scrape_url(
url='https://firecrawl.dev',
params={
'formats': [ 'markdown', 'html']
},
)
print(response)
可以看到,我们已经获取到网站的 Markdown 、html 格式内容,可直接用于 LLM 任务或进一步的数据处理。

Crawl模式
递归搜索 URL 子域并收集内容。
Firecrawl 会彻底抓取网站,确保全面提取数据,同时绕过任何网络拦截机制。
其工作原理如下:
- URL 分析: 从指定的 URL 开始,通过查看站点地图识别链接,然后抓取网站。如果没有找到站点地图,它将按照链接抓取网站。
- 递归遍历: 递归地跟踪每个链接以发现所有子页面。
- 内容抓取: 收集每个访问过的页面的内容,同时处理任何复杂问题,如 JavaScript 渲染或速率限制。
- 结果编译: 将收集的数据转换为干净的标记或结构化输出,非常适合 LLM 处理或任何其他任务。
此方法可保证从任何起始 URL 进行详尽的抓取和数据收集。
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key='your API key')
crawl_result = app.crawl_url('https://momoyu.cc/',
params={
'limit': 10,
'scrapeOptions': {
'formats': [ 'markdown' ],
}
}
)
print(crawl_result)
执行结果如下:

Map模式
输入一个网站即可获取该网站的所有网址。
从单个 URL 转到整个网站地图的最简单方法。对于以下情况非常有用:
- 当你需要提示最终用户选择要抓取的链接时;
- 需要快速了解网站上的链接;
- 需要抓取与特定主题相关的网站页面(使用search参数);
- 只需抓取网站的特定页面。
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key="your API key")
map_result = app.map_url('https://firecrawl.dev')
print(map_result)
执行结果如下:

第四步:使用操作与页面交互
Firecrawl 允许我们在抓取过程中自定义操作,例如等待页面加载、点击元素、输入文本等。
官方示例如下:
scrape_result = app.scrape_url('firecrawl.dev',
params={
'formats': ['markdown', 'html'],
'actions': [
{
"type": "wait", "milliseconds": 2000}, # 等待页面加载
{
"type": "click", "selector": "textarea[title=\"Search\"]"}, # 点击搜索框
{
"type": "wait", "milliseconds": 2000}, # 等待输入框准备
{
"type": "write", "text": "firecrawl"}, # 输入查询内容
{
"type": "wait", "milliseconds": 2000}, # 等待文本输入
{
"type": "press", "key": "ENTER"}, # 按下回车键
{
"type": "wait", "milliseconds": 3000}, # 等待搜索结果加载
{
"type": "click", "selector": "h3"}, # 点击搜索结果
{
"type": "wait", "milliseconds": 3000}, # 等待页面加载
{
"type": "scrape"}, # 抓取页面
{
"type": "screenshot"} # 截图
]
}
)
print(scrape_result)
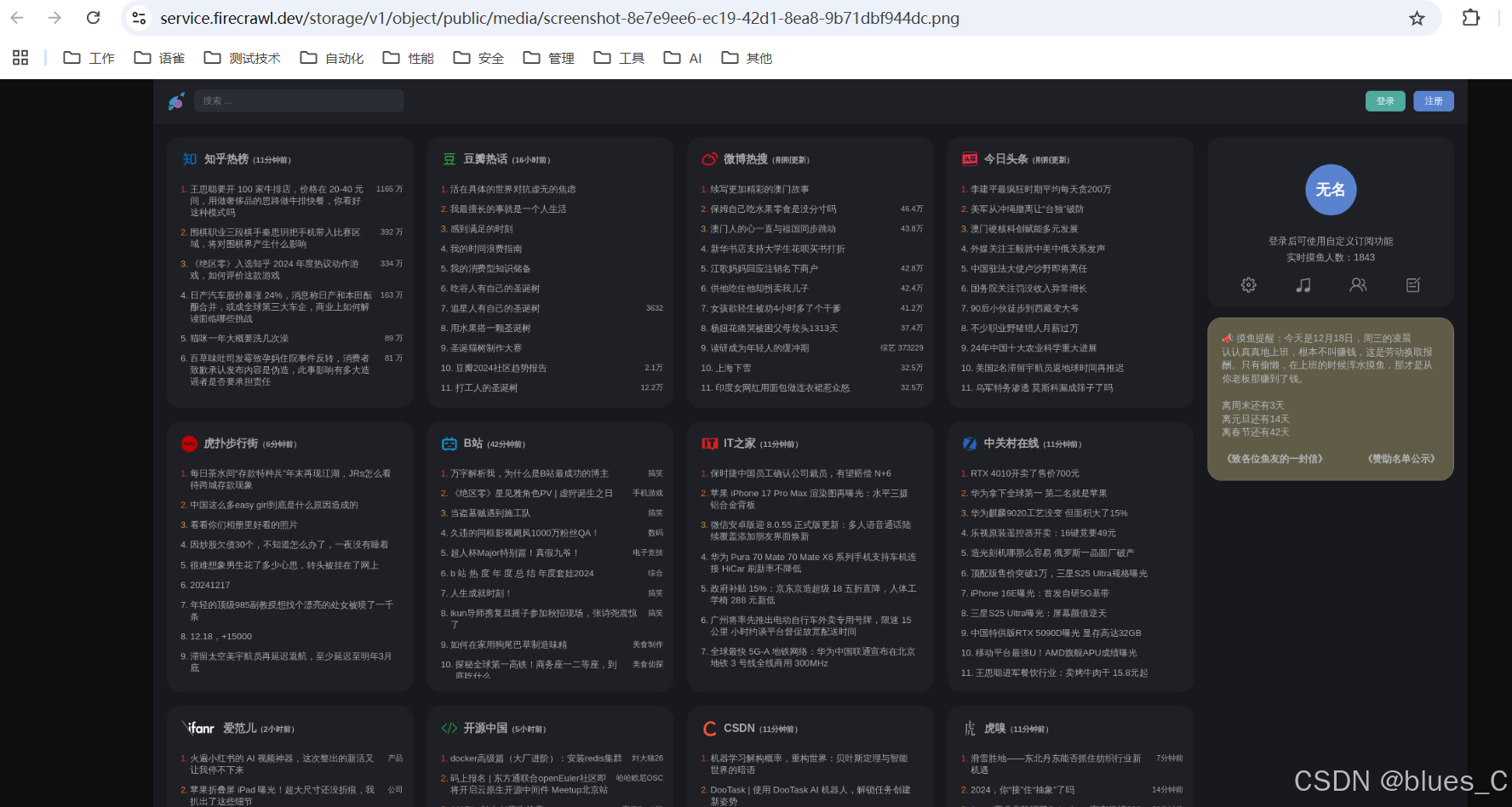
我们选取其中的 {“type”: “screenshot”}来实操一下:
from firecrawl import FirecrawlApp
app = FirecrawlApp(api_key='your API key')
response = app.scrape_url(
url='https://momoyu.cc/',
params={
'formats': [ 'markdown'],
'actions': [
{
"type": "screenshot"}
]
},
)
print(response["actions"]["screenshots"])
运行输出结果如下:
点击链接:

总结
Firecrawl 是一个强大且易于使用的工具,通过灵活的 API、丰富的 SDK 和强大的定制化选项,能够帮助您快速抓取网站数据并将其转化为适合大语言模型(LLM)使用的数据格式。无论是抓取静态页面、动态内容,还是与页面进行交互,Firecrawl 都能提供高效且可靠的解决方案。