Hadoop、HDFS 和 Hive 三者的关系与协作指南
📊 核心关系图
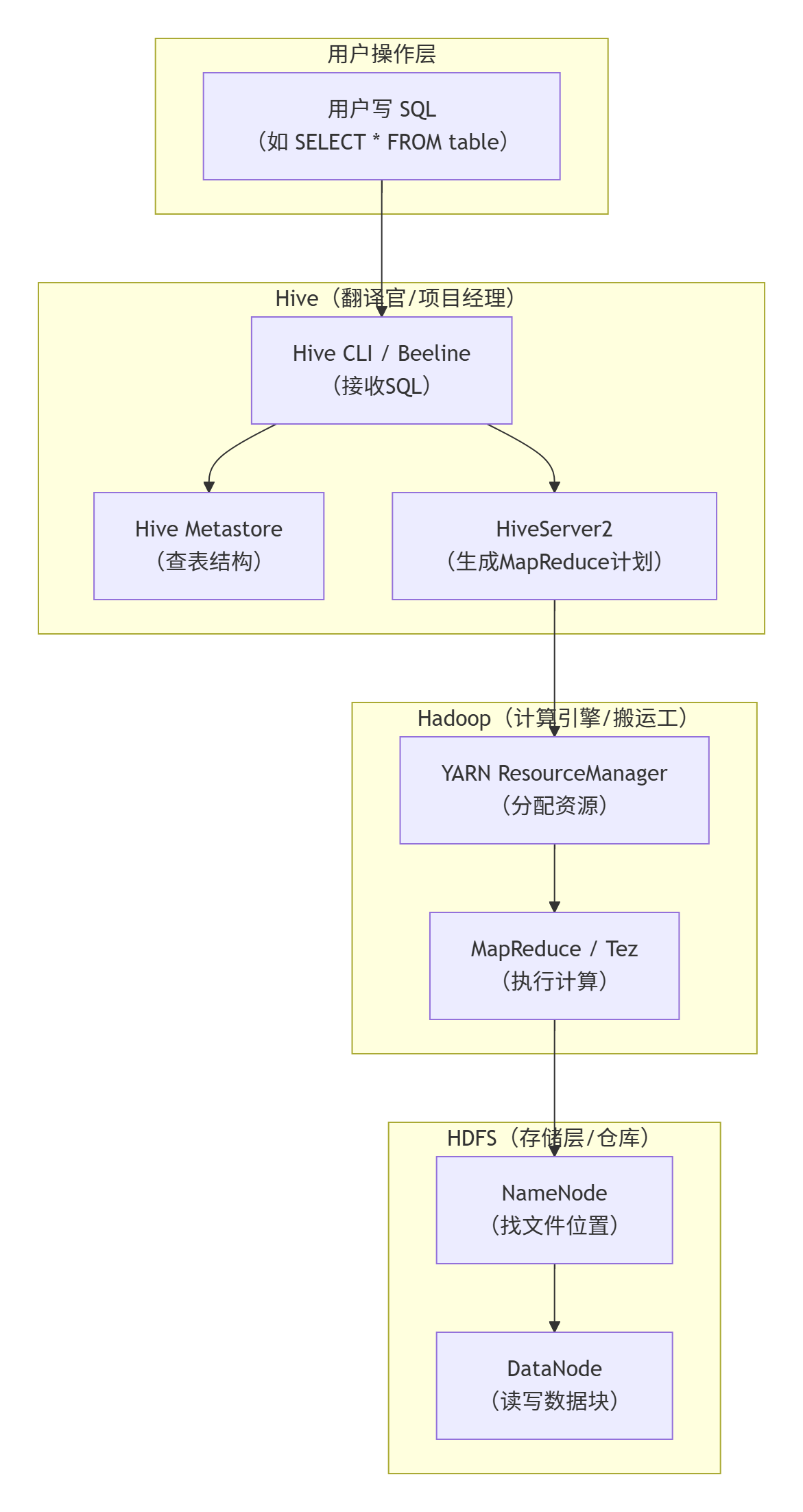
flowchart TD
subgraph User [用户操作层]
A[用户写 SQL<br>(如 SELECT * FROM table)]
end
subgraph Hive [Hive(翻译官/项目经理)]
B[Hive CLI / Beeline<br>(接收SQL)]
C[Hive Metastore<br>(查表结构)]
D[HiveServer2<br>(生成MapReduce计划)]
end
subgraph Hadoop [Hadoop(计算引擎/搬运工)]
E[YARN ResourceManager<br>(分配资源)]
F[MapReduce / Tez<br>(执行计算)]
end
subgraph HDFS [HDFS(存储层/仓库)]
G[NameNode<br>(找文件位置)]
H[DataNode<br>(读写数据块)]
end
A --> B
B --> C
B --> D
D --> E
E --> F
F --> G
G --> H🎯 三大组件核心角色
| 组件 |
角色比喻 |
核心职责 |
对应服务与端口 |
|---|---|---|---|
| HDFS |
硬盘/仓库 |
物理存储数据文件(如 .txt, .parquet) |
|
| Hadoop (MapReduce/YARN) |
工厂流水线/搬运工 |
分布式计算引擎 |
|
| Hive |
翻译官/项目经理 |
将 SQL 翻译成 MapReduce 代码 |
|
🚀 协作流程示例:SELECT count(*) FROM user
假设你的数据文件 user.txt存储在 HDFS 的 /user/hive/warehouse/user目录下。
| 步骤 |
执行组件 |
具体操作 |
|---|---|---|
| ① 用户下命令 |
用户 (Beeline) |
输入: |
| ② 查询元数据 |
Hive Metastore |
Hive 询问 Metastore(MySQL/Derby): |
| ③ 编译SQL |
HiveServer2 |
Hive 将 |
| ④ 分配资源 |
Hadoop YARN |
Hive 将 MR 程序提交给 YARN |
| ⑤ 读取数据 |
HDFS DataNode |
MapReduce 任务在数据所在节点执行 |
| ⑥ 执行计算 |
MapReduce |
执行计数逻辑,得到总行数结果 |
| ⑦ 写入结果 |
HDFS |
将最终结果(如 |
| ⑧ 返回结果 |
Beeline |
HiveServer2 读取结果文件,在 Beeline 窗口显示 |
🔧 服务启动顺序与依赖关系
⚠️ 重要:启动顺序绝对不能错!
# 1️⃣ 第一层:HDFS(地基)
start-dfs.sh # 启动 NameNode + DataNode
# 验证:hdfs dfs -ls / # 能列出目录算成功
# 2️⃣ 第二层:Hadoop YARN(动力系统)
start-yarn.sh # 启动 ResourceManager + NodeManager
# 验证:jps # 看到 ResourceManager 进程
# 注:如果只用 Hive 查询,不跑复杂计算,这步可省略
# 3️⃣ 第三层:Hive Metastore(档案室)
hive --service metastore & # 启动 9083 端口
# 验证:netstat -tlnp | grep 9083
# 4️⃣ 第四层:HiveServer2(服务窗口)
hive --service hiveserver2 & # 启动 10000 端口
# 验证:等待30秒后
netstat -tlnp | grep 10000
beeline -u "jdbc:hive2://localhost:10000/default;auth=noSasl" -n root -e "select 1"⚠️ 常见问题与诊断
问题现象:无法连接 Hive
| 错误现象 |
断掉的环节 |
解决方案 |
|---|---|---|
|
|
HiveServer2 未启动 |
|
| 报错 |
Metastore 未启动 |
先启动 |
| 报错 |
HDFS 未就绪 |
|
| 报错 |
HDFS 权限不足 |
|
| 启动后立即崩溃,只有 |
Java 版本不兼容 |
Hadoop 2.x 需要 Java 8 |
| 报错 |
clusterID 不匹配 |
清理 DataNode 目录,重新同步 |
📁 Hive 可执行文件说明
| 文件 |
用途 |
启动命令示例 |
|---|---|---|
|
|
JDBC 客户端,连接 HiveServer2 |
|
|
|
旧的 Hive CLI(命令行接口) |
|
|
|
启动 HiveServer2 服务 |
|
|
|
Metastore 管理工具 |
|
|
|
Metastore 数据库初始化 |
|
🔍 诊断工具与命令
检查服务状态
# 查看所有相关服务
jps
netstat -tlnp | grep -E "8020|9000|9870|9083|10000"
# 检查 HDFS
hdfs dfsadmin -report
hdfs dfs -ls /
# 检查 Hive
beeline -u "jdbc:hive2://localhost:10000/default;auth=noSasl" -n root -e "show databases;"查看日志
# HDFS 日志
tail -f /opt/hadoop/hadoop-2.9.2/logs/hadoop-*-datanode-*.log
# Hive 日志
tail -f /opt/hive/logs/metastore.log
tail -f /opt/hive/logs/hiveserver2.log💡 最佳实践建议
-
启动顺序牢记:HDFS → YARN → Metastore → HiveServer2
-
验证每一步:启动后务必验证端口是否监听
-
权限管理:确保 HDFS 目录有适当权限
-
日志排查:遇到问题首先查看对应日志文件
-
环境一致:确保所有节点使用相同版本的 Java 和 Hadoop
-
资源配置:根据数据量调整
hadoop-env.sh中的内存配置
🎯 总结
-
HDFS 是底层存储,负责数据持久化
-
Hadoop 是计算引擎,负责数据处理
-
Hive 是查询接口,将 SQL 转换为 MapReduce
-
启动顺序决定系统稳定性,依赖关系必须严格遵守
-
问题诊断要沿着依赖链逐层排查
记住这个比喻:HDFS 是仓库(存数据),Hadoop 是搬运工(算数据),Hive 是翻译官(写 SQL 指挥搬运工)。三者各司其职,协同工作,构成完整的大数据处理平台。