GR00T N1.5 是 GR00T N1 的升级版本,具有更高的性能和新的功能。更多详细信息请参见GR00T N1.5
如果需要使用旧版本(N1),就检出(checkout)n1-release 发布分支
现阶段的主流方案,快慢双系统 VLA 架构:模仿人类认知的 System 1(快思考,动作生成)+ System 2(慢思考,推理决策)
-
System 2:预训练视觉-语言模型(VLM)理解场景与任务指令
-
System 1:基于扩散变换器(DiT),流匹配建模,实现高频(120Hz)运动控制
-
两系统 Transformer 深度耦合,端到端联合训练
🌐 Project Website:Isaac GR00T - Generalist Robot 00 Technology | NVIDIA Developer
🐾 Github:https://github.com/NVIDIA/Isaac-GR00T/tree/main
🤖 Model:https://huggingface.co/nvidia/GR00T-N1.5-3B
🤗 Dataset:https://huggingface.co/datasets/nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim
📄 Paper:NVIDIA Isaac GR00T N1: An Open Foundation Model for Humanoid Robots | Research

目录
2.1 Model and Data Improvements
6 Getting started with this repo
6.2.2 Inference with Python TensorRT (Optional)
1 NVIDIA Isaac GR00T
NVIDIA Isaac GR00T N1.5 是一个面向通用人形机器人推理与技能的开放基础模型。该跨具身(cross-embodiment)模型能够接收多模态输入,包括语言和图像,从而在各种环境中执行操控任务
GR00T N1.5 的训练基于大规模人形机器人数据集,这些数据包括:
-
真实采集数据(real captured data)
-
利用 NVIDIA Isaac GR00T Blueprint 组件生成的合成数据(examples of neural-generated trajectories)
-
互联网规模的视频数据(internet-scale video data)
该模型能够通过后续微调(post-training)适应特定的机器人形态(embodiments)、任务和环境


GR00T N1.5 的神经网络结构结合了视觉-语言基础模型(vision-language foundation model)和用于去噪连续动作的扩散 Transformer 头(diffusion transformer head)。架构示意图如下:
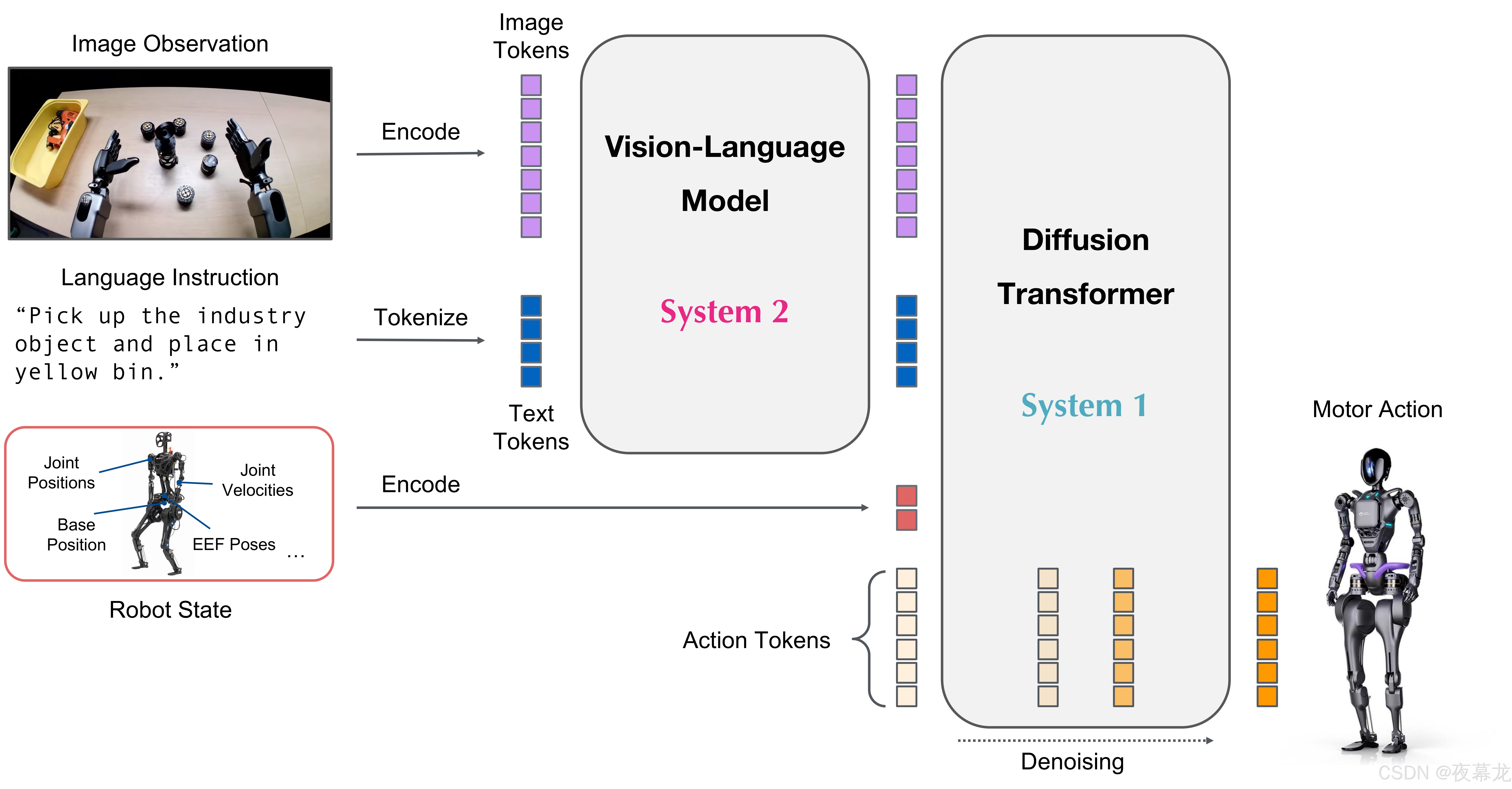
以下是 GR00T N1.5 的通用使用流程:
1. 假设用户已经收集好了机器人示范数据集,数据格式为(视频、状态、动作)三元组
2. 用户首先需要将示范数据转换为 LeRobot 兼容数据格式(详见 getting_started/LeRobot_compatible_data_schema.md),该格式与 Huggingface LeRobot 框架兼容
3. 此 repo 提供了不同机器人形态下的训练配置示例
4. 此 repo 还提供了便捷的脚本,可用于在用户数据上微调预训练的 GR00T N1.5 模型,并运行推理(inference)
5. 用户最终将 Gr00tPolicy 模块连接到机器人控制器(robot controller),以在目标硬件上执行动作
2 What's New in GR00T N1.5
GR00T N1.5 相较于 GR00T N1 实现了重大升级,无论是在模型结构还是数据方面都做出了改进,从而在多个层面带来了更优异的性能表现
2.1 Model and Data Improvements
1. Frozen VLM:VLM 在预训练和微调阶段都保持参数冻结,不参与梯度更新,这样可以保持其语言理解能力,同时提升整体泛化性能
2. Enhanced VLM Grounding:升级为 Eagle 2.5 基座模型,具备更强的视觉-物理对齐和空间理解能力。在 GR-1 机器人物理落地任务上,达到了 40.4 的 IoU(交并比),相比 Qwen2.5VL 的 35.5 提升明显
3. Simplified Adapter:通过精简的 MLP 连接视觉编码器和 LLM,并引入了层归一化(LayerNorm)
4. FLARE Integration:在流匹配损失(flow matching loss)之外,新增了 FLARE(Future Latent Representation Alignment,未来潜表示对齐)目标,使模型能更高效地从人类第一视角视频中学习到时序关联与预测能力
5. DreamGen Integration:引入通过 DreamGen 生成的合成神经轨迹,让模型不仅依赖遥操作采集数据,还能泛化到新颖行为和任务上
2.2 Performance Improvements
1. Language Following:在 GR-1 机器人操控任务上,GR00T N1.5 的语言指令执行准确率达到了 93.3%,远超 N1 版本的 46.6%
2. Data Efficiency:在低数据量场景(如零样本/小样本,0-shot/few-shot)下,N1.5 也能表现出更强的泛化和适应能力
3. Better Novel Object Generalization:能更好地识别和操作训练中未出现过的新物体
4. New Embodiment Heads:通过 EmbodimentTag.OXE_DROID 头支持基于末端执行器(EEF)空间的单臂机器人,通过 EmbodimentTag.AGIBOT_GENIE1 头支持带有夹爪的人形机器人, 突破了仅基于关节空间控制的限制,大幅拓展了与各类机器人硬件的兼容性
以上改进使 GR00T N1.5 在强语言理解能力、小样本快速适应、以及对新物体和新环境的泛化方面表现出色,特别适用于多变、开放、复杂的机器人智能应用场景。 更多模型细节与实验结果请参见官方 GR00T N1.5 tech blog
3 Target Audience
GR00T N1.5 主要面向人形机器人领域的研究人员和专业人士。此 repository 提供以下工具:
-
利用预训练基础模型进行机器人控制
-
在小型定制数据集上进行微调
-
用极少的数据将模型适配到具体的机器人任务
-
部署模型用于推理
重点在于通过微调实现对机器人行为的个性化定制
4 Prerequisites
- 已在 Ubuntu 20.04 和 22.04 系统、H100、L40、RTX 4090 和 A6000 等 GPU 上对微调进行了测试,Python 版本为 3.10,CUDA 版本为 12.4
- 在推理(inference)方面,已在 Ubuntu 20.04 和 22.04 系统、RTX 3090、RTX 4090 和 A6000 GPU 上进行测试
- 如果尚未安装 CUDA 12.4,请按照 here 的说明进行安装
- 如果尚未安装 tensorrt,请按照 here 的说明进行安装
- 请确保系统中已安装以下依赖项:ffmpeg、libsm6、libxext6
5 Installation Guide
Clone the repo:
git clone https://github.com/NVIDIA/Isaac-GR00T
cd Isaac-GR00T创建新的 conda 环境并安装依赖。推荐使用 Python 3.10:
Note:请确保 CUDA 版本为 12.4。否则,配置 flash-attn 模块时可能会遇到问题
conda create -n gr00t python=3.10
conda activate gr00t
pip install --upgrade setuptools
pip install -e .[base]
pip install --no-build-isolation flash-attn==2.7.1.post4 6 Getting started with this repo
在 ./getting_started 文件夹中提供了易于使用的 Jupyter notebooks 和详细的文档
实用脚本可在 ./scripts 文件夹中找到
此外,在 HuggingFace 上还提供了针对 SO-101 机器人的完整微调教程
6.1 Data Format & Loading
为了加载和处理数据,使用 Huggingface LeRobot data,但采用了更细致的模态和标注方案(称之为“LeRobot 兼容数据格式”)
LeRobot 数据集示例存放在:./demo_data/robot_sim.PickNPlace(附带额外的 modality.json 文件)
关于数据集格式的详细说明,请参见 getting_started/LeRobot_compatible_data_schema.md
通过 EmbodimentTag 系统支持多种具身类型
只要数据整理为此格式,就可以通过 LeRobotSingleDataset 类加载数据
from gr00t.data.dataset import LeRobotSingleDataset
from gr00t.data.embodiment_tags import EmbodimentTag
from gr00t.data.dataset import ModalityConfig
from gr00t.experiment.data_config import DATA_CONFIG_MAP
# get the data config
data_config = DATA_CONFIG_MAP["fourier_gr1_arms_only"]
# get the modality configs and transforms
modality_config = data_config.modality_config()
transforms = data_config.transform()
# This is a LeRobotSingleDataset object that loads the data from the given dataset path.
dataset = LeRobotSingleDataset(
dataset_path="demo_data/robot_sim.PickNPlace",
modality_configs=modality_config,
transforms=None, # we can choose to not apply any transforms
embodiment_tag=EmbodimentTag.GR1, # the embodiment to use
)
# This is an example of how to access the data.
dataset[5]- getting_started/0_load_dataset.ipynb 是一个交互式教程,介绍如何加载数据并处理成 GR00T N1.5 可用格式
- scripts/load_dataset.py 是与上述笔记本内容相同的可执行脚本,可以运行脚本来加载数据集
运行脚本来加载数据集:
python scripts/load_dataset.py --dataset-path ./demo_data/robot_sim.PickNPlace6.2 Inference
GR00T N1.5 model 托管在 Huggingface 上
跨具身数据集示例见 demo_data/robot_sim.PickNPlace
6.2.1 Inference with PyTorch
from gr00t.model.policy import Gr00tPolicy
from gr00t.data.embodiment_tags import EmbodimentTag
# 1. Load the modality config and transforms, or use above
modality_config = ComposedModalityConfig(...)
transforms = ComposedModalityTransform(...)
# 2. Load the dataset
dataset = LeRobotSingleDataset(.....<Same as above>....)
# 3. Load pre-trained model
policy = Gr00tPolicy(
model_path="nvidia/GR00T-N1.5-3B",
modality_config=modality_config,
modality_transform=transforms,
embodiment_tag=EmbodimentTag.GR1,
device="cuda"
)
# 4. Run inference
action_chunk = policy.get_action(dataset[0])getting_started/1_gr00t_inference.ipynb 是一个搭建推理流程的交互式 Jupyter notebook 教程
用户也可以使用脚本运行推理服务。推理服务可在 server 模式或 client 模式下运行:
python scripts/inference_service.py --model-path nvidia/GR00T-N1.5-3B --server在另一个终端下,运行 client 模式以向服务端发送请求:
python scripts/inference_service.py --client6.2.2 Inference with Python TensorRT (Optional)
如需用 ONNX 和 TensorRT 进行推理,请参考 deployment_scripts/README.md
6.3 Fine-Tuning
用户可以运行下方微调脚本,在示例数据集上对模型进行微调。相关教程请参见 getting_started/2_finetuning.ipynb
然后运行微调脚本:
# first run --help to see the available arguments
python scripts/gr00t_finetune.py --help
# then run the script
python scripts/gr00t_finetune.py --dataset-path ./demo_data/robot_sim.PickNPlace --num-gpus 1注意:如果你用 4090 显卡进行微调,运行 gr00t_finetune.py 时需加上 --no-tune_diffusion_model 参数以避免 CUDA 内存溢出
也可以从 huggingface sim data release here 下载示例数据集:
huggingface-cli download nvidia/PhysicalAI-Robotics-GR00T-X-Embodiment-Sim \
--repo-type dataset \
--include "gr1_arms_only.CanSort/**" \
--local-dir $HOME/gr00t_dataset推荐的微调配置是将 batch size 调至最大,训练 20k steps
硬件性能注意事项
- 微调性能:使用 1 块 H100 节点或 L40 节点获得最佳微调效果。其他硬件(如 A6000、RTX 4090)同样支持,但收敛速度可能略慢。具体 batch size 取决于硬件和你调整的模型部分
- LoRA 微调:我们用 2 块 A6000 或 2 块 RTX 4090 进行 LoRA 微调。用户可以尝试不同配置以获得良好效果
- 推理性能:在实时推理场景下,大多数现代 GPU 在处理单条样本时速度差异很小。基准测试显示 L40 和 RTX 4090 在推理速度上几乎无差异
如需新具身类型的微调,请参考 getting_started/3_0_new_embodiment_finetuning.md notebook
Choosing the Right Embodiment Head

GR00T N1.5 提供了三种针对不同机器人配置优化的预训练具身头:
- EmbodimentTag.GR1:为使用绝对关节空间控制的人形机器人(具备灵巧手)设计
- EmbodimentTag.OXE_DROID:为采用增量末端执行器(EEF)控制的单臂机器人优化
- EmbodimentTag.AGIBOT_GENIE1:为带有夹爪、使用绝对关节空间控制的人形机器人设计
- EmbodimentTag.NEW_EMBODIMENT:(未预训练)用于在新机器人形态上进行微调的新具身头
请选择最符合你的机器人配置的具身头,以获得最佳微调性能。关于观测空间和动作空间的详细信息,请参见 EmbodimentTag
6.4 Evaluation
为了对模型进行离线评估,此 repo 提供了一个脚本,可以在数据集上评估模型并绘制结果。快速体验:
python scripts/eval_policy.py --plot --model_path nvidia/GR00T-N1.5-3B或者可以将新训练的模型以客户端-服务端模式运行
运行新训练的模型:
python scripts/inference_service.py --server \
--model-path <MODEL_PATH> \
--embodiment-tag new_embodiment
--data-config <DATA_CONFIG>运行离线评估脚本:
python scripts/eval_policy.py --plot \
--dataset-path <DATASET_PATH> \
--embodiment-tag new_embodiment \
--data-config <DATA_CONFIG>将看到真实动作(Ground Truth)与预测动作(Predicted actions)的对比图,以及动作的未归一化 MSE。这可以帮助你判断策略在数据集上的表现是否良好
7 Jetson Deployment
关于如何在 Jetson 上部署 GR00T N1.5 的详细指南,请参见 deployment_scripts/README.md
下面是 PyTorch 和 TensorRT 在 Orin 上端到端性能的对比

通过 trtexec 在 batch_size=1 测量的模型延迟
| Model Name | Orin benchmark perf (ms) | Precision |
|---|---|---|
| Action_Head - process_backbone_output | 5.17 | FP16 |
| Action_Head - state_encoder | 0.05 | FP16 |
| Action_Head - action_encoder | 0.20 | FP16 |
| Action_Head - DiT | 7.77 | FP16 |
| Action_Head - action_decoder | 0.04 | FP16 |
| VLM - ViT | 11.96 | FP16 |
| VLM - LLM | 17.25 | FP16 |
Note:模块延迟 in pipeline(e.g., DiT Block)会比上表中的模型延迟略长,因为模块延迟不仅包含表中的模型延迟,还包括从 PyTorch 到 TensorRT 以及从 TensorRT 回传到 PyTorch 的数据传输开销
8 FAQ
是否支持 CUDA ARM Linux ?
- 是的,请访问 jetson-containers
我有自己的数据,下一步如何微调?
- 此 repo 假设你的数据已经按照 LeRobot 格式组织好
什么是 Modality Config?Embodiment Tag?Transform Config?
- Embodiment Tag:定义所用的机器人形态,所有未预训练的具身标签都视为 new_embodiment
- Modality Config:定义数据集所用的模态(如视频、状态、动作)
- Transform Config:定义数据加载过程中应用的数据变换
- 更多信息见 getting_started/4_deeper_understanding.md
Gr00tPolicy 的推理速度是多少?
以下为单卡 H100 GPU 的基准结果。在消费级 GPU(如 RTX 4090)上推理单样本会略慢:
| 模块 | 推理速度 |
|---|---|
| VLM Backbone | 23.18 ms |
| Action Head(4次扩散步) | 4 x 6.18 ms = 24.7 ms |
| 完整模型 | 47.88 ms |
我们观察到,推理时采用 4 步去噪已足够
如何用多个数据集训练?
- 可通过为 dataset_path 参数提供数据集路径列表来实现多数据集训练
python scripts/gr00t_finetune.py --dataset-path <DATASET1> <DATASET2> --num-gpus 1默认情况下,gr00t_finetune.py 对所有数据集赋予相同权重,balance_dataset_weights 和 balance_trajectory_weights 均为 True。 更多信息请参见 gr00t/data/dataset.py 中的 LeRobotMixtureDataset 类定义。用户也可以直接使用 LeRobotMixtureDataset 类,配合不同的具身、变换和采样权重进行多数据集训练
支持 LoRA 微调吗?
支持。可以通过在微调脚本中添加 --lora_rank 64 --lora_alpha 128 启用 LoRA 微调。但推荐使用全模型微调以获得更好的性能
9 Contributing
更多详情请参见 ONTRIBUTING.md