参考:https://github.com/vesoft-inc/nebula-python/blob/master/example/GraphClientSimpleExample.py
文档:https://docs.nebula-graph.com.cn/3.4.1/3.ngql-guide/7.general-query-statements/2.match/#_4
pip install nebula3-python
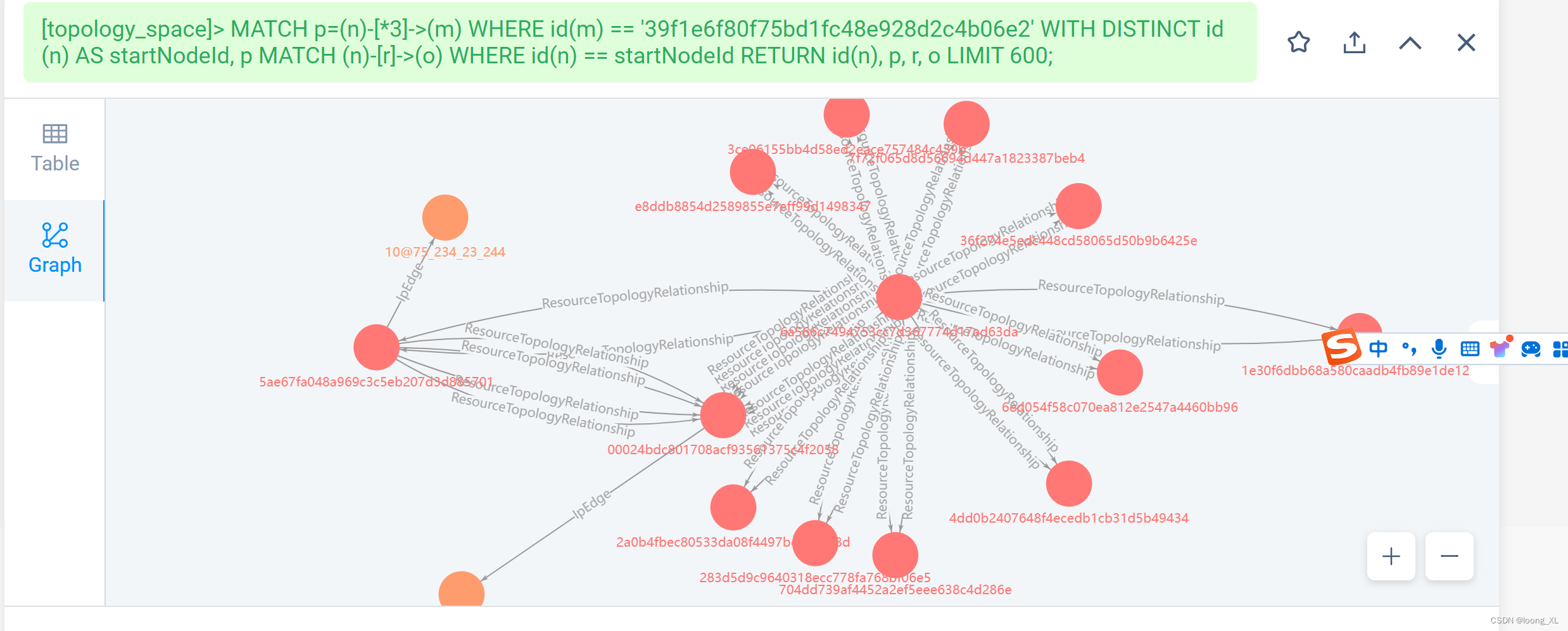
1)查询的节点,再把这头节点再查一度范围的节点

MATCH p=(n)-[*3]->(m) WHERE id(m) == '39f1e6f***d2c4b06e2' WITH DISTINCT id(n) AS startNodeId, p MATCH (n)-[r]->(o) WHERE id(n) == startNodeId RETURN id(n), p, r, o LIMIT 600;
2)通过属性查询节点信息;
MATCH (rt:ResourceTopology {
ip:"75.234.9.39"}) RETURN rt;
或
MATCH (rt:ResourceTopology ) WHERE rt.ResourceTopology.ip == "75.234.9.39" RETURN rt;

或
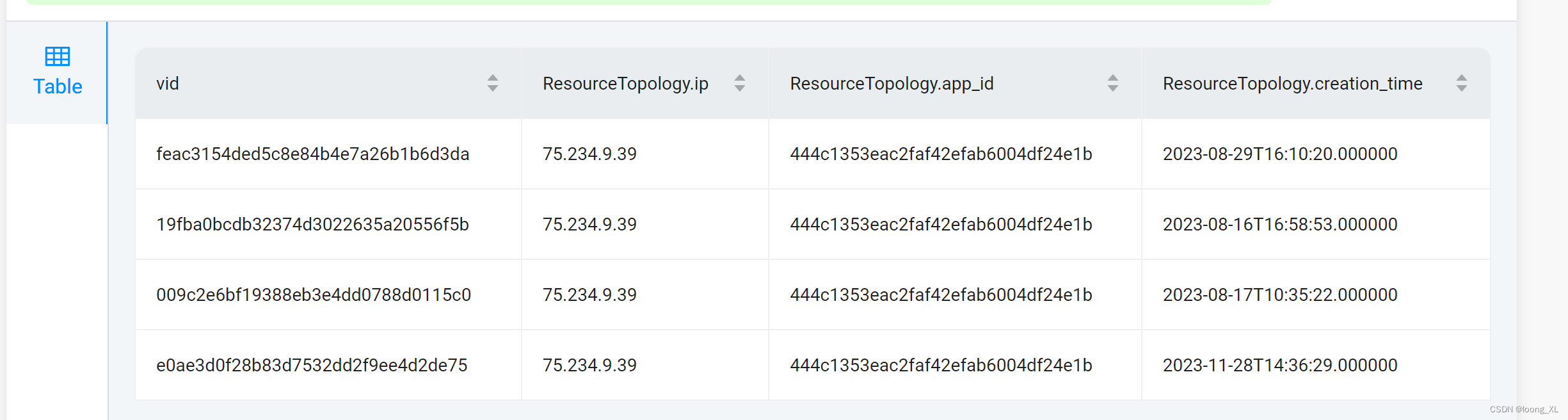
LOOKUP ON ResourceTopology WHERE ResourceTopology.ip =="75.234.9.39" YIELD id(vertex) as vid,ResourceTopology.ip,ResourceTopology.app_id,ResourceTopology.creation_time;
属性指定范围内查询:
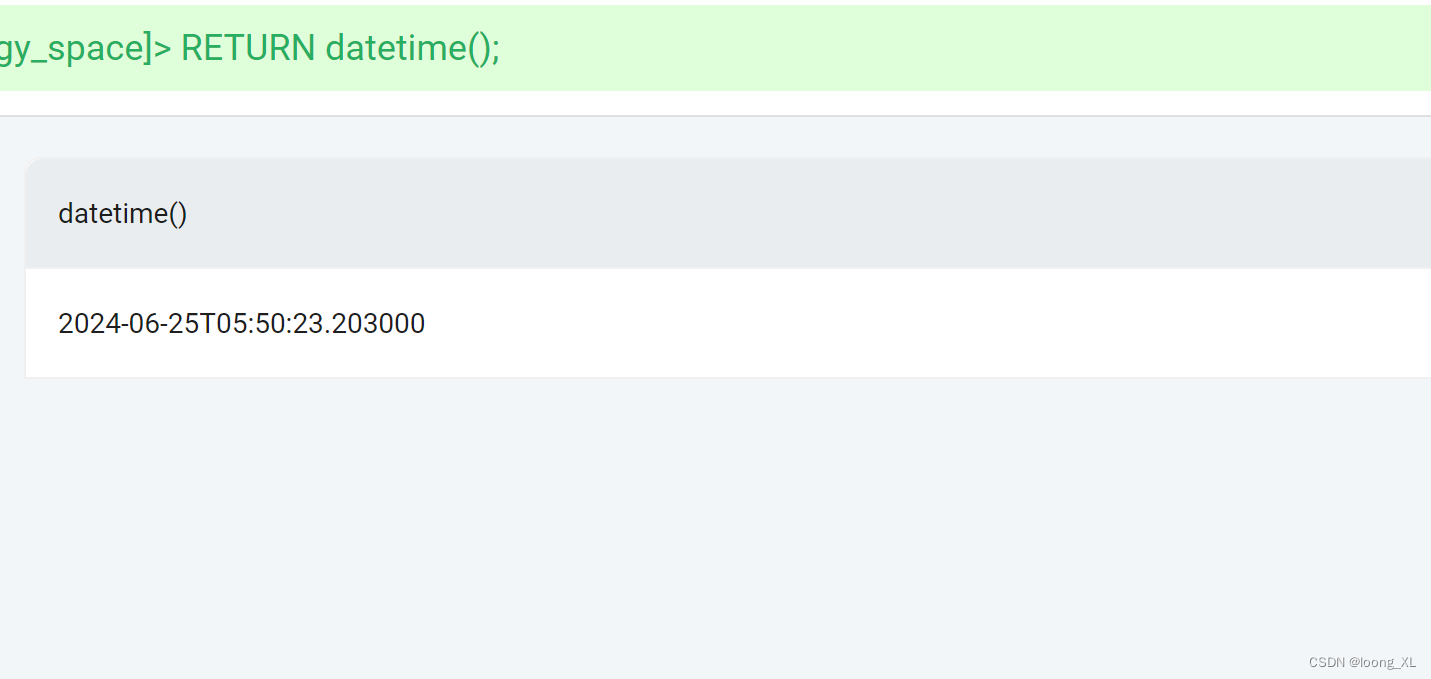
时间范围(参考:https://docs.nebula-graph.com.cn/3.4.1/3.ngql-guide/3.data-types/4.date-and-time/#datetime)
MATCH (rt:ResourceTopology) WHERE rt.ResourceTopology.creation_time >= datetime("2023-08-21T16:51:39.000000") AND rt.ResourceTopology.creation_time <= datetime("2023-10-21T17:21:39.000000") RETURN rt;

3)查询节点间最短路劲
https://docs.nebula-graph.com.cn/3.4.1/3.ngql-guide/7.general-query-statements/2.match/#_4
e*…5 表示路径中边的数量最多为 5

MATCH p = shortestPath((a:AlarmTag{
ip:"75.234.23.167"})-[e*..5]-(b:ResourceTopology)) WHERE id(b) == "1a5a0a0b74416a3b624500853ca07a35" RETURN p;
或
MATCH p = shortestPath((a)-[e*..5]-(b:ResourceTopology)) WHERE id(a) == "39f1e6f80f75bd1fc48e928d2c4b06e3" AND id(b) == "1a5a0a0b74416a3b624500853ca07a35"RETURN p;

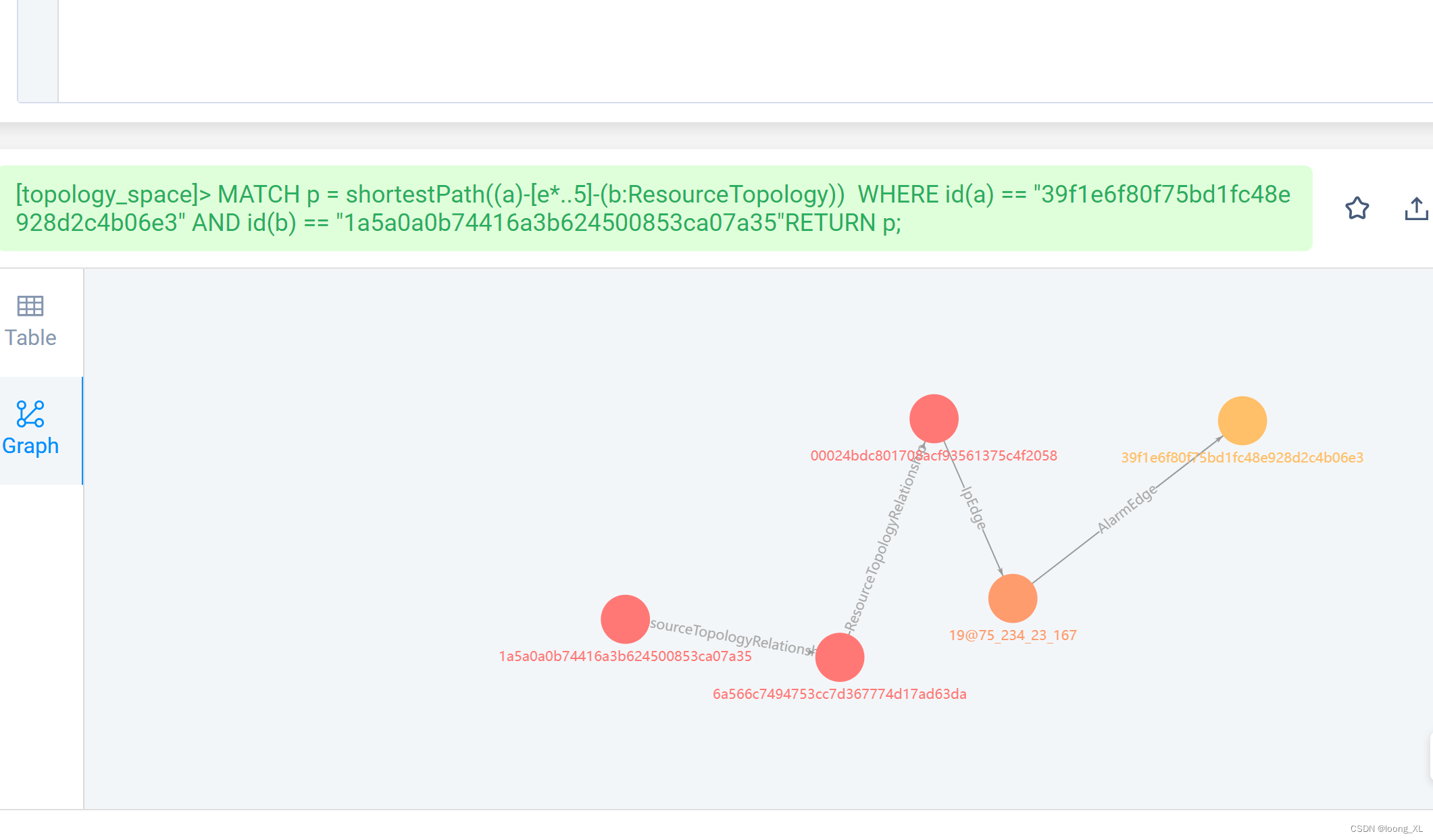
报错:Error found in optimization stage: IndexNotFound: No valid index found
nebula查询具体属性的话需要先对该属性创立索引,
1)给AlarmTag类型节点的ip创建索引 CREATE TAG INDEX IF NOT EXISTS ip_index_1 ON AlarmTag(ip(20));
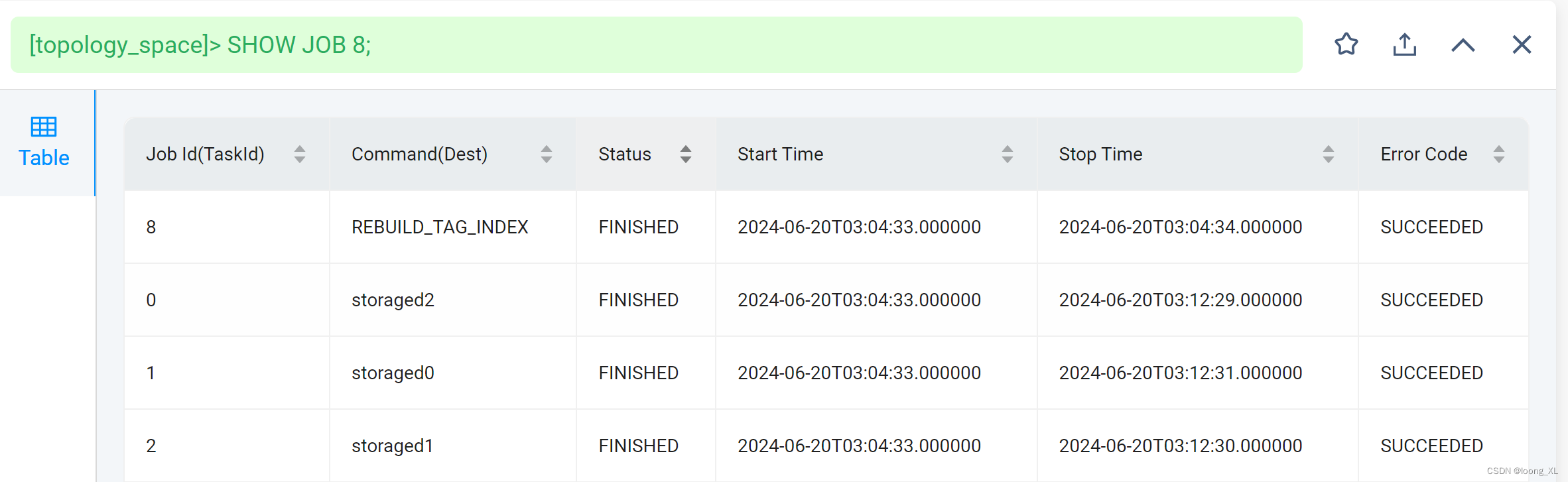
2)加载生效 REBUILD TAG INDEX ip_index_1;
3)SHOW JOB 8;查看结果
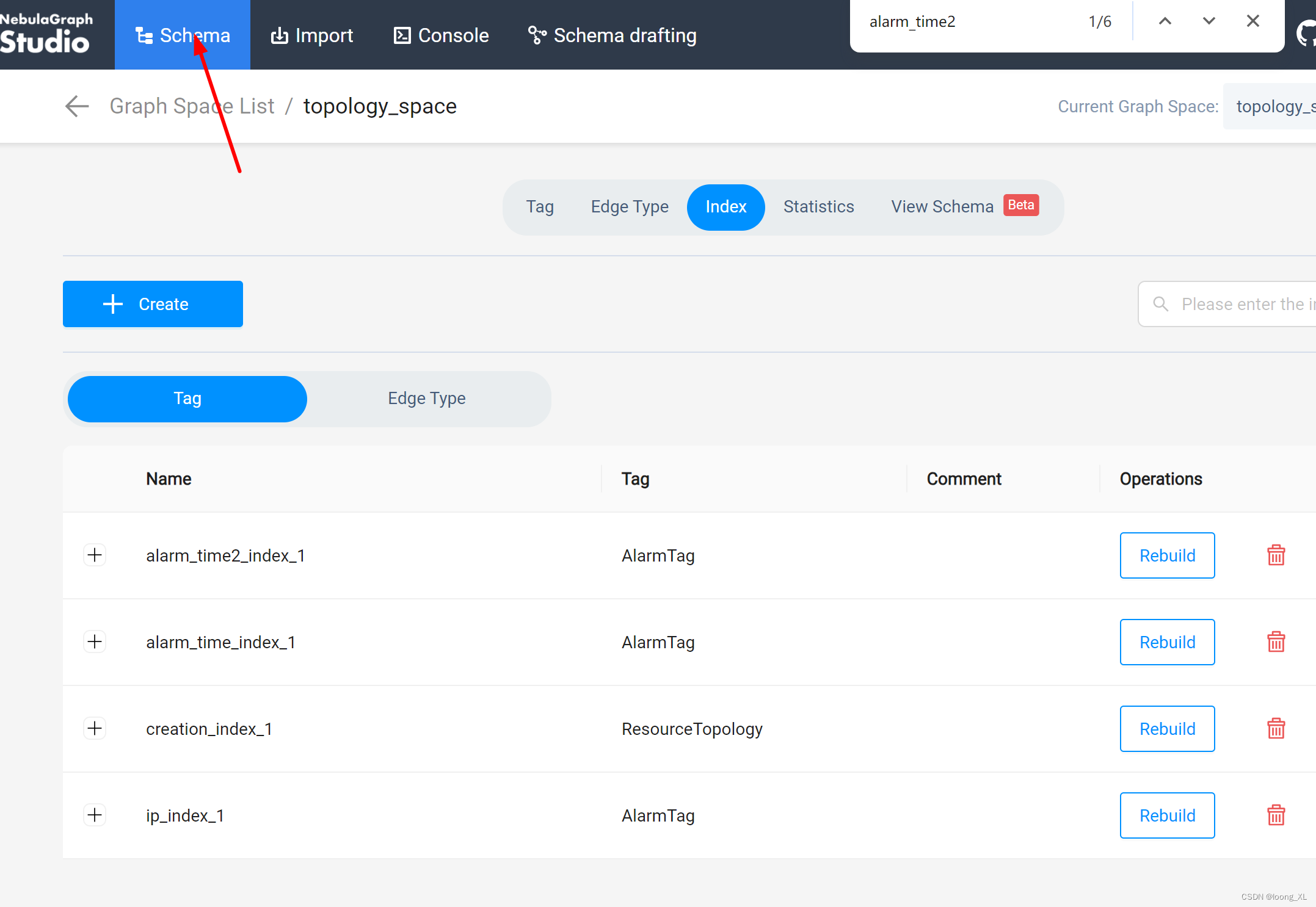
构建的索引可以在页面schema里查看:
或者creation_time不带括号,数字一般不需要括号,字符串需要:

CREATE TAG INDEX IF NOT EXISTS creation_index_1 ON ResourceTopology(creation_time);
REBUILD TAG INDEX creation_index_1;
MATCH (rt:ResourceTopology) WHERE rt.ResourceTopology.creation_time >= datetime("2023-10-16T14:51:39.000000") AND rt.ResourceTopology.creation_time <= datetime("2023-10-16T17:21:39.000000") RETURN rt;

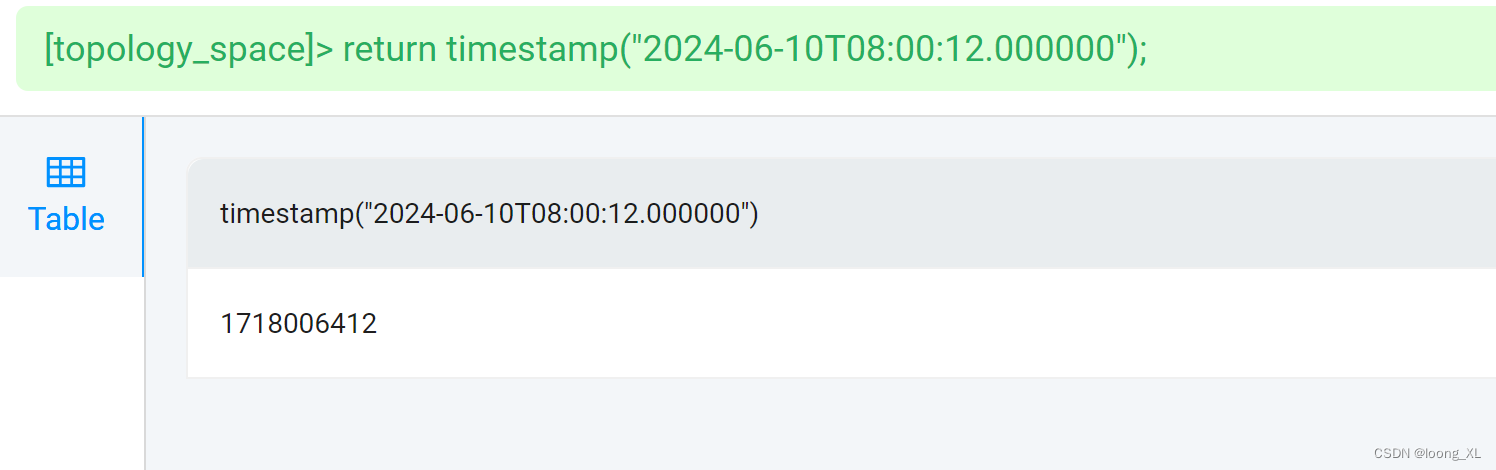
这里timestamp NebulaGraph只有10位,保存表里不止10位这里*1000
MATCH (rt:AlarmTag ) WHERE rt.AlarmTag.alarm_time <= timestamp("2024-06-15T06:18:43")*1000 RETURN rt;

代码:
from nebula3.gclient.net import ConnectionPool
from nebula3.Config import Config
config = Config() # 定义一个配置
config.max_connection_pool_size = 10 # 设置最大连接数
connection_pool = ConnectionPool() # 初始化连接池
# 如果给定的服务器是ok的,返回true,否则返回false
ok = connection_pool.init([('192.1**', 9669)], config)
# 方式1:connection pool自己控制连接释放
# 从连接池中获取一个session
session = connection_pool.get_session('root', 'n')
session.execute('USE topology_space') # 选择space
# results = session.execute(
# "MATCH p=(a)-[*3]->(b) where id(a) == '04d690ad942998ea7ed2b74decd7fe9c' RETURN p limit 105;"
# )
results = session.execute("MATCH p=(n)-[*3]->(m) WHERE id(n) == '693a18da69f5d3d4e3caa4cf09610d29' RETURN p LIMIT 600;")
results.column_values(“p”)
results.row_values(14)[0]
results.as_data_frame()
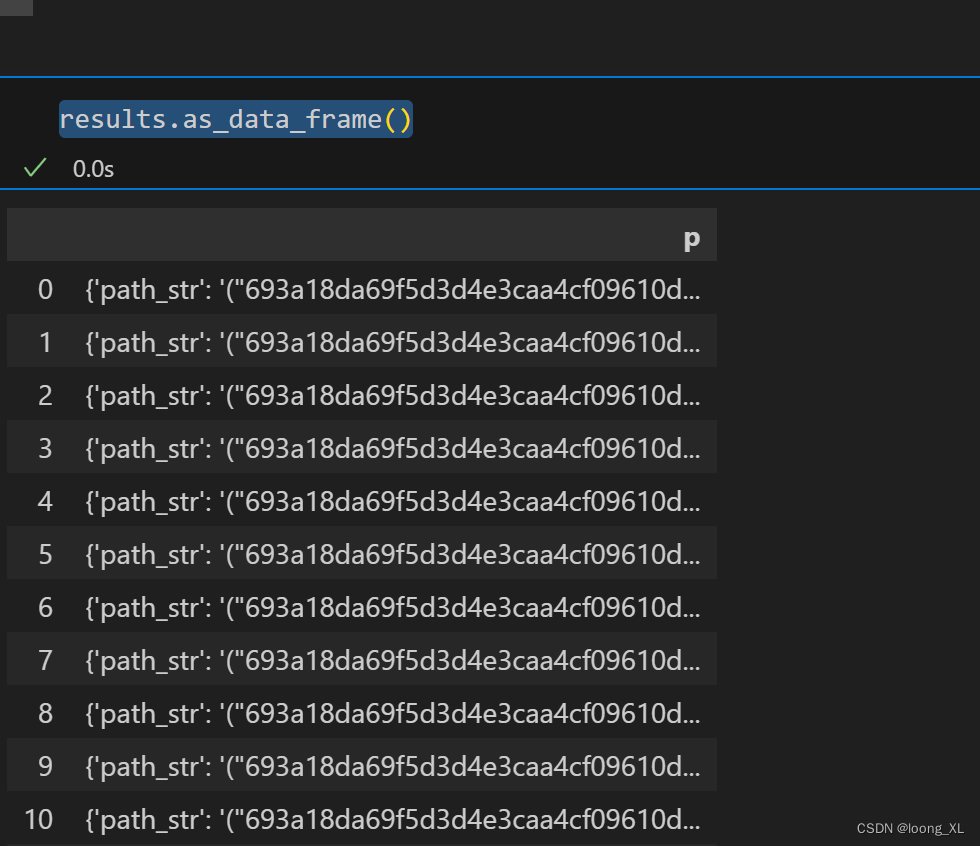
查询结果为json:
results1 = session.execute_json("MATCH p=(n)-[*3]->(m) WHERE id(n) == '693a18da69f5d3d4e3caa4cf09610d29' RETURN p LIMIT 600;")
import json
print(len(json.loads(results1)["results"][0]["data"]))
json.loads(results1)["results"][0]["data"][0]
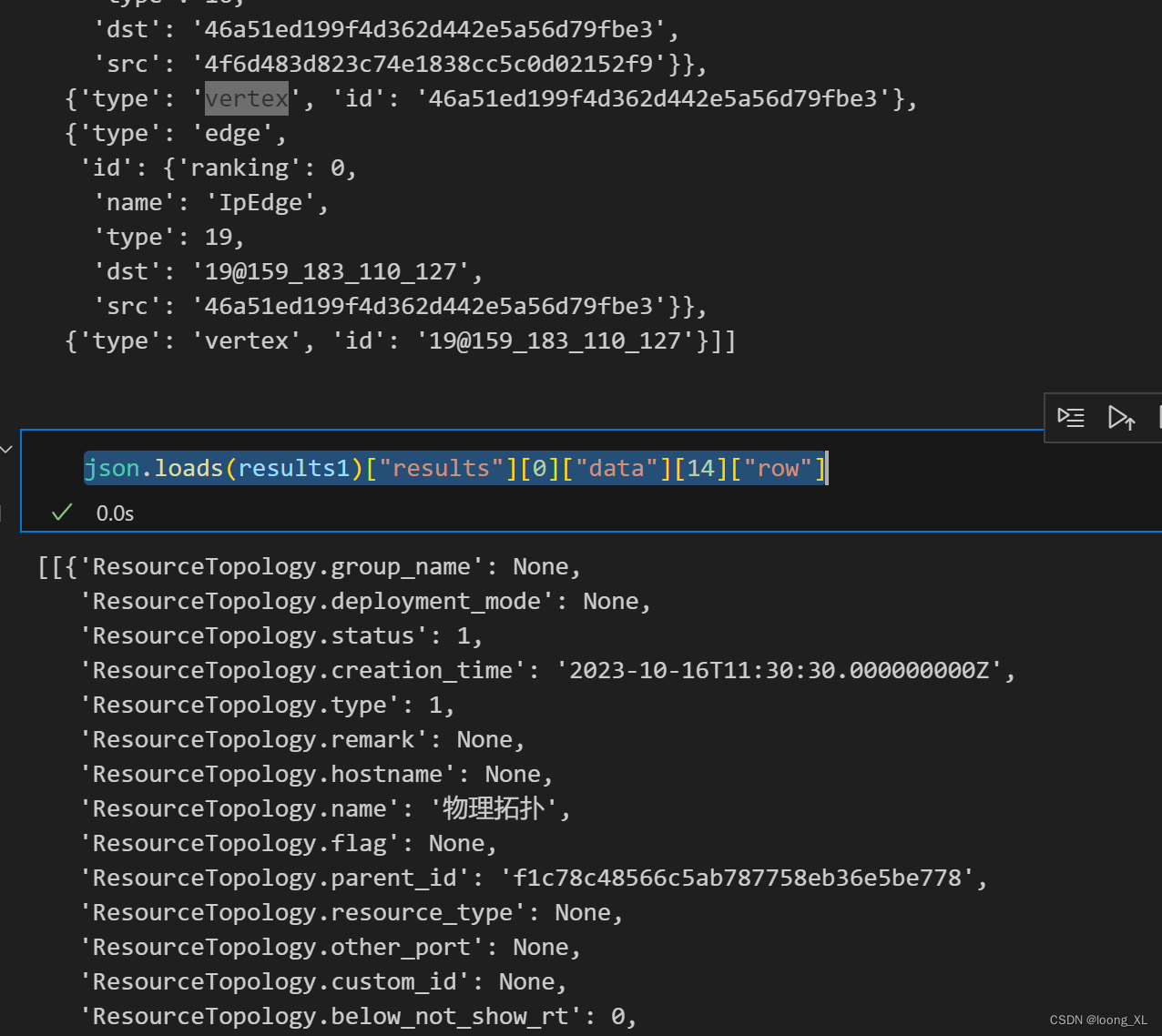
json.loads(results1)["results"][0]["data"][14]
这个查询结果来自一个图数据库,表示了一个包含顶点和边的图形结构。在这个结果中,meta 和 row 是两个主要的部分。
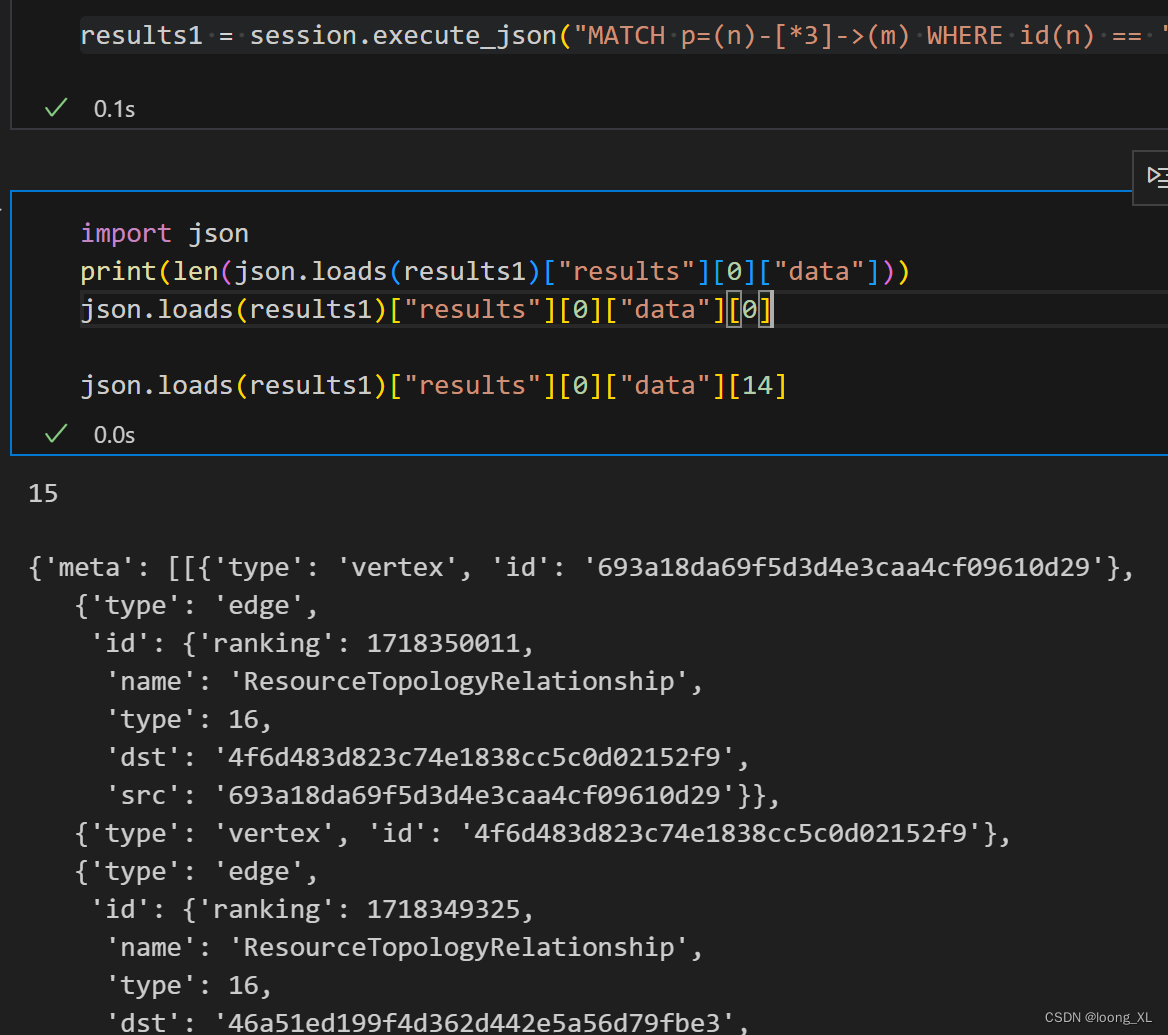
meta部分:它描述了图形中的顶点和边的信息。每个元素(顶点或边)都有一个type属性来表示它是顶点还是边,以及一个id属性来唯一标识它。对于边,还有额外的属性,如ranking、name、type、dst(目标顶点ID)和src(源顶点ID)。
在这个例子中,meta 包含了以下顶点和边:
- 顶点1(ID:693a18da69f5d3d4e3caa4cf09610d29)
- 边1(ID:由排名、名称、类型、目标顶点和源顶点组成)
- 顶点2(ID:4f6d483d823c74e1838cc5c0d02152f9)
- 边2(ID:由排名、名称、类型、目标顶点和源顶点组成)
- 顶点3(ID:46a51ed199f4d362d442e5a56d79fbe3)
- 边3(ID:由排名、名称、类型、目标顶点和源顶点组成)
- 顶点4(ID:19@159_183_110_127)
row部分:它包含了与meta中描述的顶点和边相关联的数据属性。这些属性以字典的形式存储,其中键是属性名,值是属性值。
在这个例子中,row 包含了以下数据:
- 与顶点1相关的属性(如 ResourceTopology.name、ResourceTopology.status 等)
- 与边1相关的属性(如 relationship_type、app_id 等)
- 与顶点2相关的属性(如 ResourceTopology.hostname、ResourceTopology.ip 等)
- 与边2相关的属性(如 line_type、source_port 等)
- 与顶点3相关的属性(如 ResourceTopology.hostname、ResourceTopology.ip 等)
- 与边3相关的属性(为空)
- 与顶点4相关的属性(如 Ip.app_id、Ip.ip 等)
总之,这个查询结果展示了一个包含多个顶点和边的图形结构,以及这些顶点和边所关联的数据属性。这种结构可以用于表示复杂的网络关系、资源拓扑等场景。
json.loads(results1)["results"][0]["data"][14]["meta"]
json.loads(results1)["results"][0]["data"][14]["row"]