集成环境
| 描述 | 工具 | 版本 |
|---|---|---|
| 操作系统 | Windows | 11 (x64) |
| 显卡 | RTX 3070 | 576.02(驱动版本) |
| 构建工具 | CMake | 3.26.5 |
| 开发工具 | Visual Studio | 2022(17.14.15) |
准备工作
库版本与下载
| 库名称 | 版本 | 链接 |
|---|---|---|
| OpenCV | 4.12.0 | 下载 |
| OpenCV_contrib | 4.12.0 | 下载 |
| CUDA Toolkit | 12.4.1 | 下载 |
| cuDNN | 8.9.7 | 下载 |
| NASM | 2.16.3 | 下载 |
| ONNXRuntime (GPU) | 1.18.1-cuda12 | 下载 |
| Video Codec SDK | 12.2.72 | 下载 |
经过多版本交叉测试,以上是OpenCV 4.12.0 + VS2022目前可集成的最新/稳定的库版本
ONNXRuntiom为GPU版本,但也可以通过代码降级控制兼容CPU推理的
CUDA Toolkit安装
- 版本选择
CMD命令行执行nvidia-smi,查看的GPU最大支持的CUDA版本
这一步很重要,是上述各库版本选型的前提,如果主版本小于12,需升级下显卡驱动
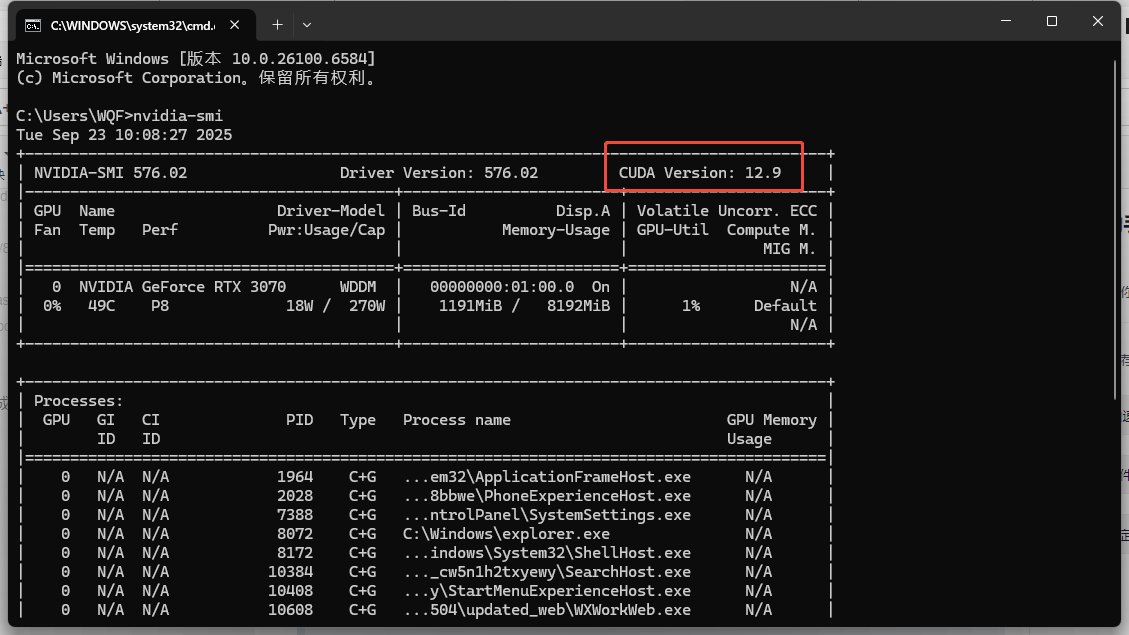
NVIDIA-SMI是NVIDIA显卡的系统管理接口,可以用于获取显卡硬件和驱动程序的信息,以及进行一些基本的管理和监控操作,显示的CUDA版本为最大支持的版本
经测试,OpenCV 4.12.0 需选择CUDA Toolkit版本需为12.4.1(12.9版本VS无法编译),相应的cuDNN版本需为8.9.7
- 安装CUDA Toolkit
双击cuda_12.4.1_551.78_windows.exe解压文件,默认的文件路径即可,安装完成后自动会删除
注意:安装前需确保vs2022已安装成功,且vs处于未打开状态
进入安装界面
点击"同意并继续"
选择"自定义",点击"下一步"
点击"Driver components",取消"Display Driver"和"HD Audio"的勾选
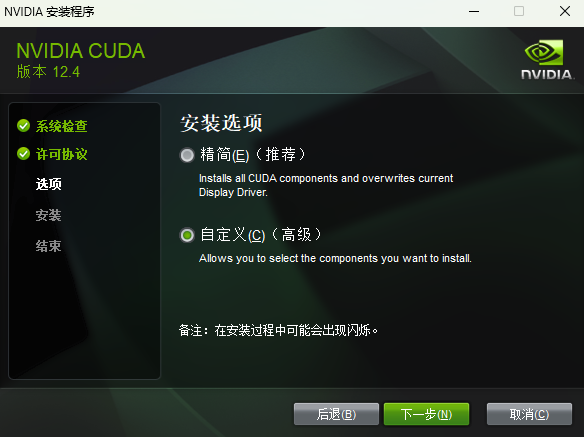
CUDA 安装包自带的显卡驱动版本可能与当前系统安装的显卡驱动版本存在差异,覆盖安装可能会导致蓝屏、卡顿或兼容性问题;HD Audio 是 NVIDIA 显卡的 HDMI/DP 接口音频输出驱动,与 CUDA 的 GPU 计算无关,所以不需要安装
不要修改安装路径,直接点击"下一步"
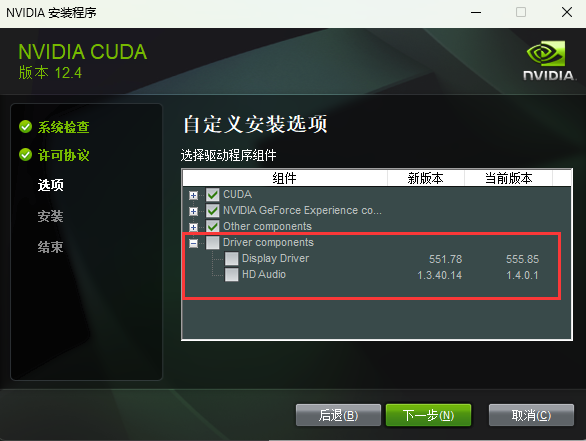
默认为
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4
这也是cuDNN、Video Codec SDK需要拷贝到的目标目录
3. 验证 CUDA 是否安装成功
打开CMD命令行,输入nvcc --version,获得以下信息即可表示成功
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2024 NVIDIA Corporation
Built on Thu_Mar_28_02:30:10_Pacific_Daylight_Time_2024
Cuda compilation tools, release 12.4, V12.4.131
Build cuda_12.4.r12.4/compiler.34097967_0
系统环境变量本文安装时是环境变量自动配好的,如看不到以上结果,可以参考其他博文进行配置
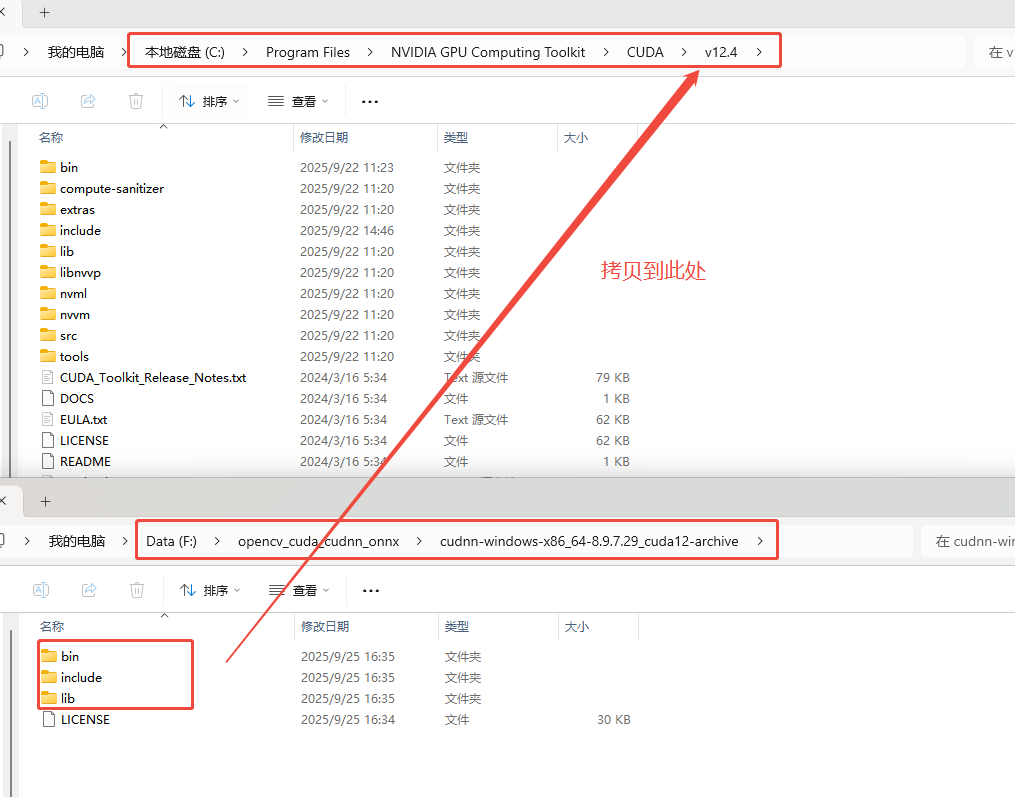
cuDNN配置
拷贝cudnn-windows-x86_64-8.9.7.29_cuda12-archive下的bin、include、lib到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4中
Video Codec SDK配置
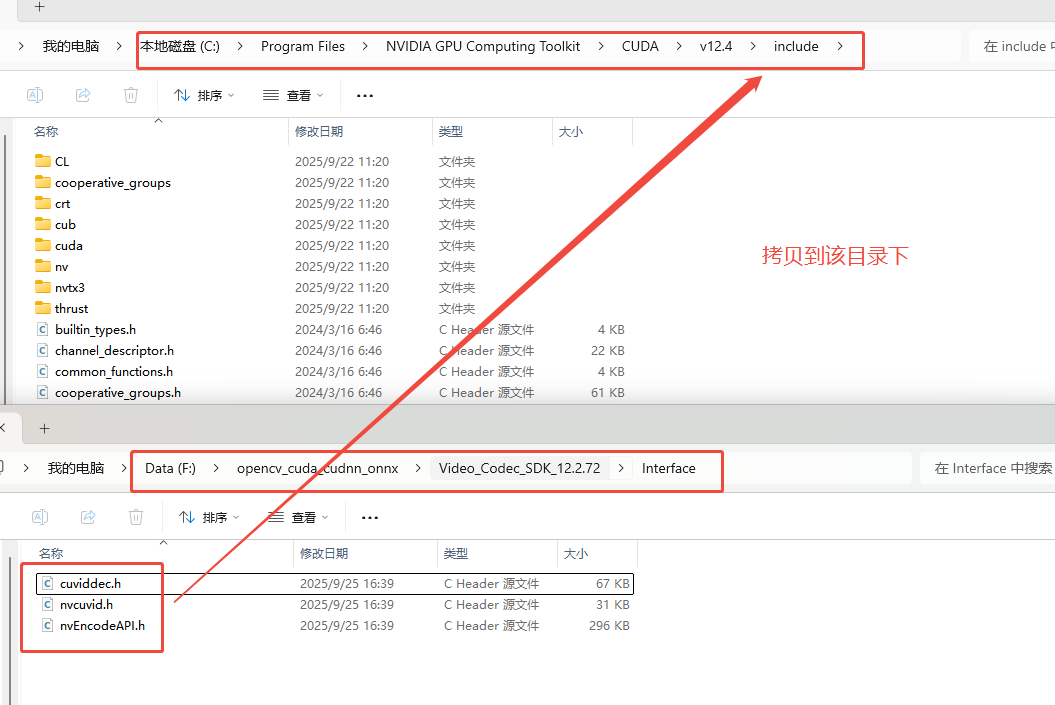
拷贝Video_Codec_SDK_12.2.72\Interface下的cuviddec.h、nvcuvid.h、nvEncodeAPI.h到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\include中
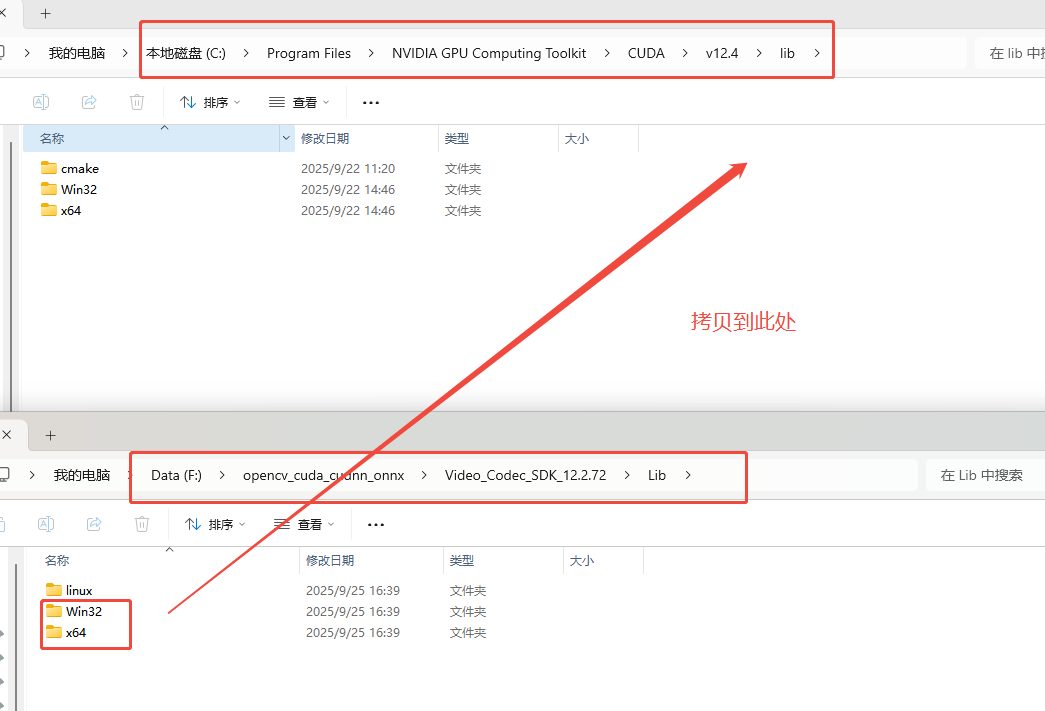
拷贝Video_Codec_SDK_12.2.72\Lib下的Win32、x64到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v12.4\lib中
解压文件
将opencv-4.12.0、opencv_contrib-4.12.0、onnxruntime-win-x64-gpu-cuda12-1.18.1分别解压到同一个目录下,编译好的文件超过10GB,如果你的C盘空间有限,不建议放在桌面
CMake配置
OpenCV
选择opencv4.12.0解压目录,按下图所示,设置构建目录,选择编译方式,点击Configure按钮
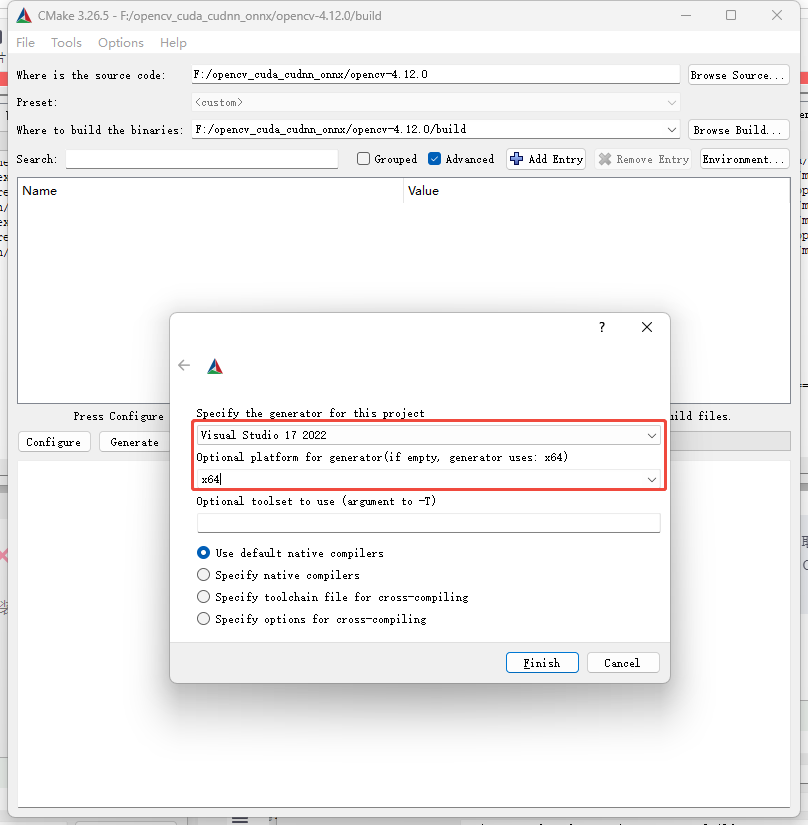
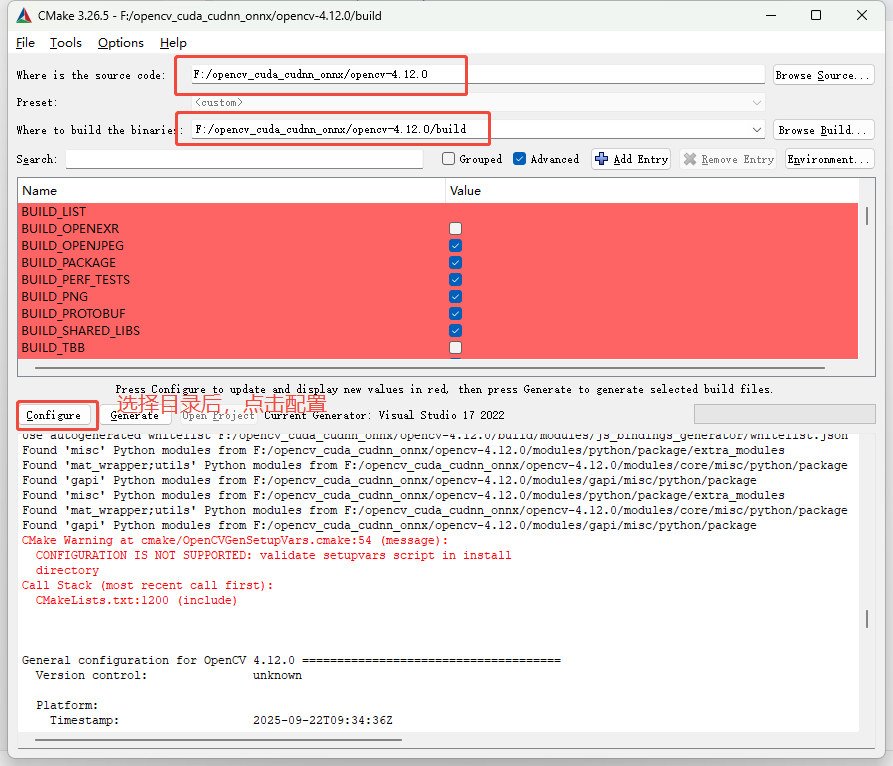
首次配置出现如图警告完全可以忽略,也可以搜索
OPENCV_GENERATE_SETUPVARS取消勾选❌,再次点击configure按钮。
它的主要作用是生成一个用于设置 OpenCV 环境变量的文件。当这个选项开启时,CMake 会在安装 OpenCV 时生成一个名为 opencv_generated_setupvars.cmake 的文件
OpenCV_contrib
搜索OPENCV_EXTRA_MODULES_PATH选择扩展库下的modules目录
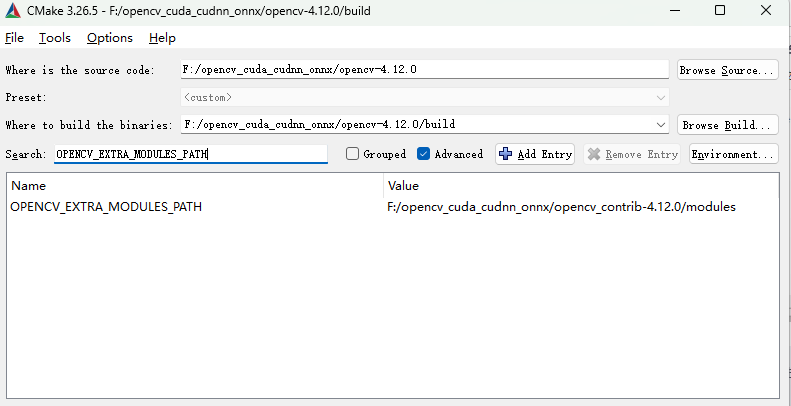
搜索OPENCV_ENABLE_NONFREE勾选✅
启用包含非自由(non-free)算法的模块,允许编译和使用受专利保护的非自由算法(如 SIFT、SURF)。它是一个编译时的开关,主要用于科研或学习目的。在商业项目中使用时需谨慎,建议优先选择无专利风险的替代算法。
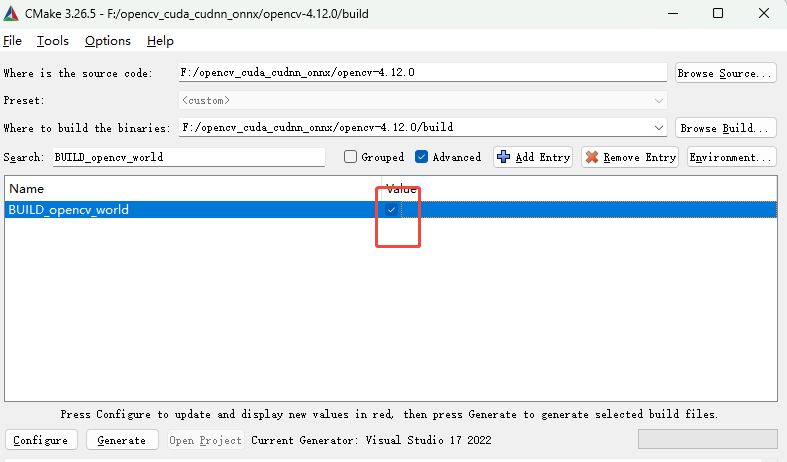
搜索BUILD_opencv_world勾选✅
如果你不打算构建成一个文件可跳过这个步骤
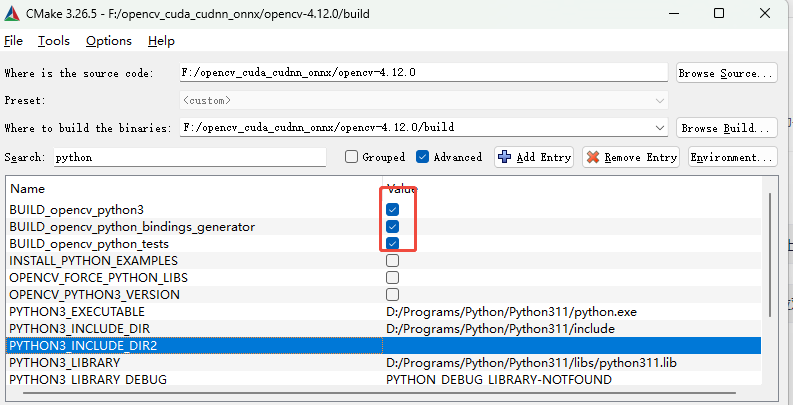
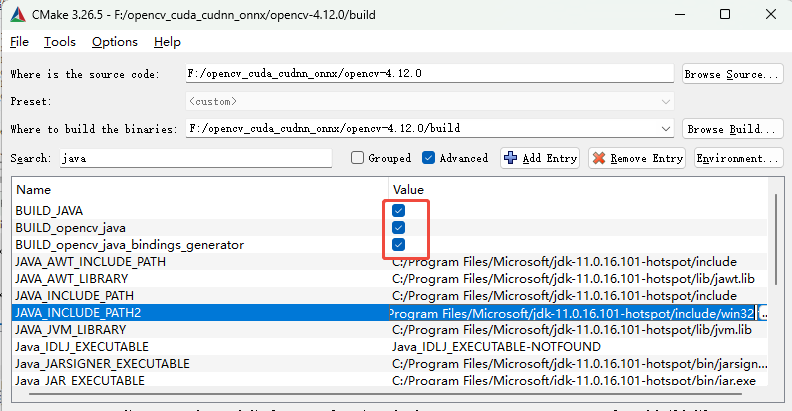
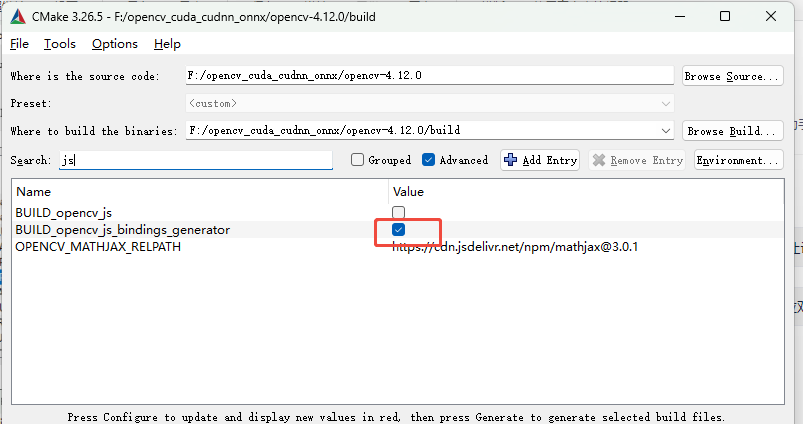
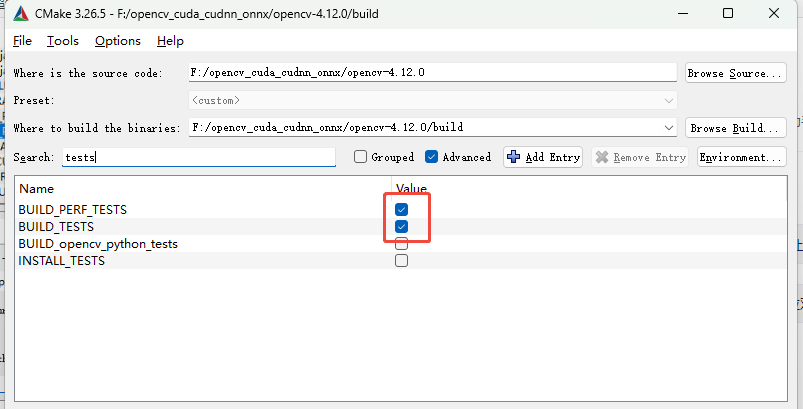
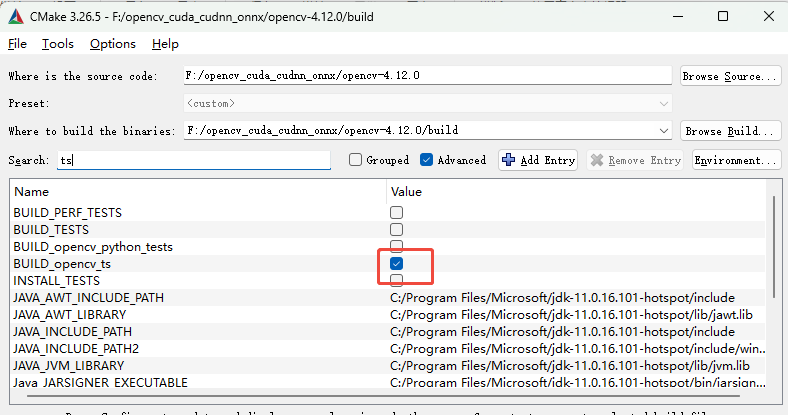
依次搜索python、java、js、tests、ts取消勾选❌
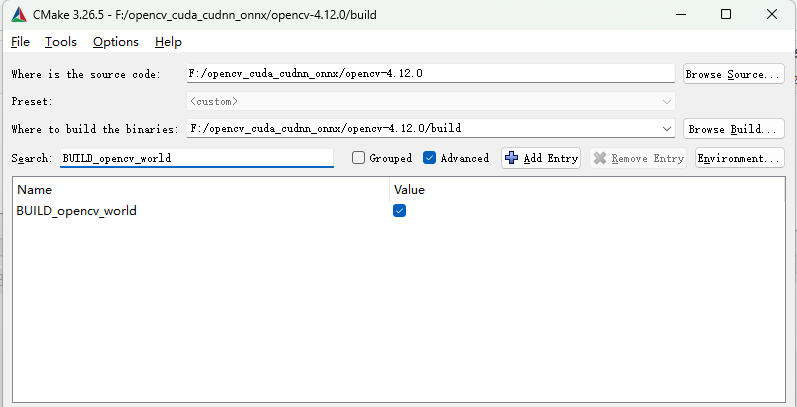
如果你需要相关语言或测试用例可不取消,本示例是只考虑C++语言
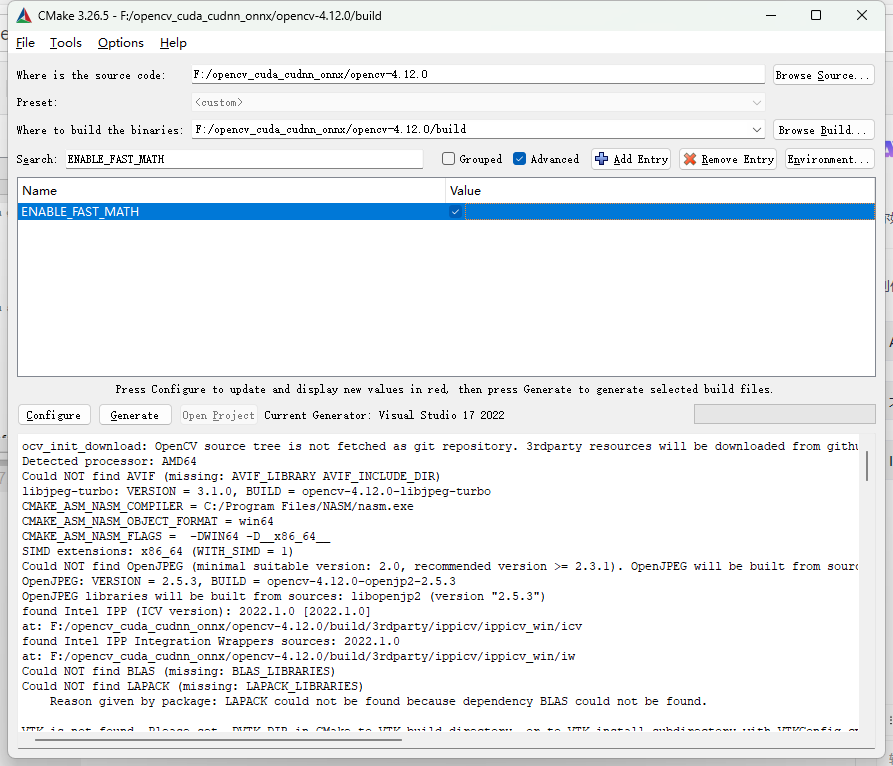
搜索ENABLE_FAST_MATH勾选✅
开启可让 OpenCV 跑得更快,但算得“不太准”;是否开启,取决于你对“速度”和“精度”的权衡
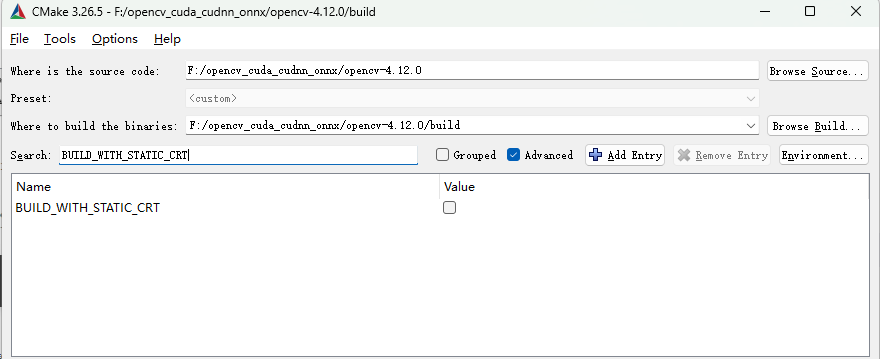
搜索BUILD_WITH_STATIC_CRT取消勾选❌
编译时不启用静态编译
点击Configure按钮
CUDA Toolkit
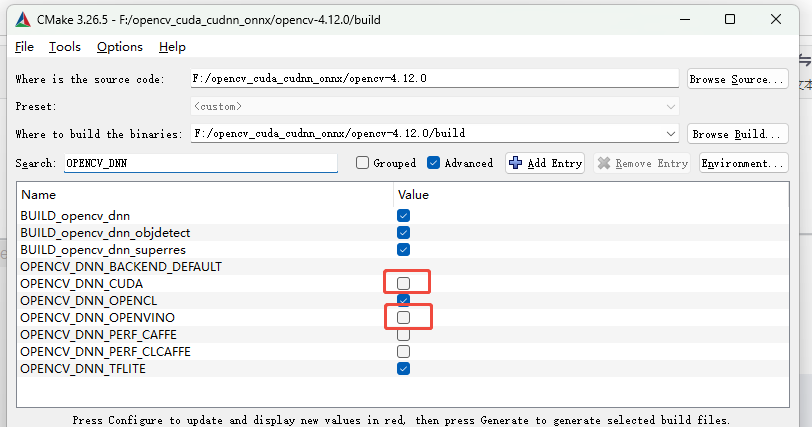
搜索OPENCV_DNN,勾选✅OPENCV_DNN_CUDA,勾选✅OPENCV_DNN_OPENVINO
CPU\GPU两种硬件加速模块
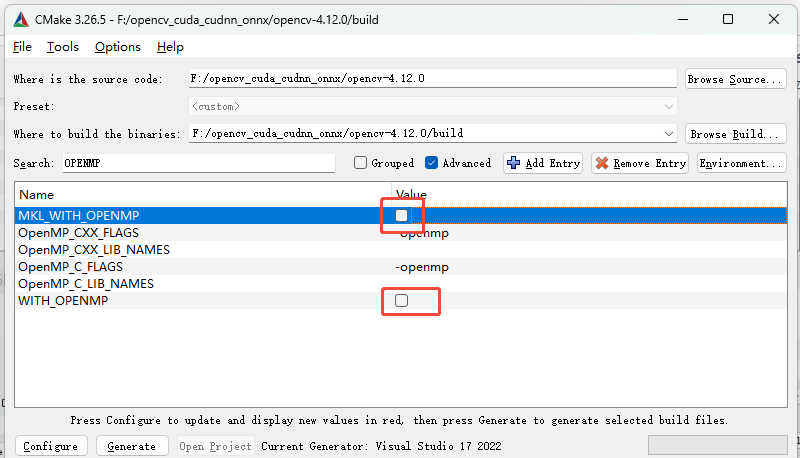
搜索OPENMP,勾选✅WITH_OPENMP、勾选✅MKL_WITHOPENMP
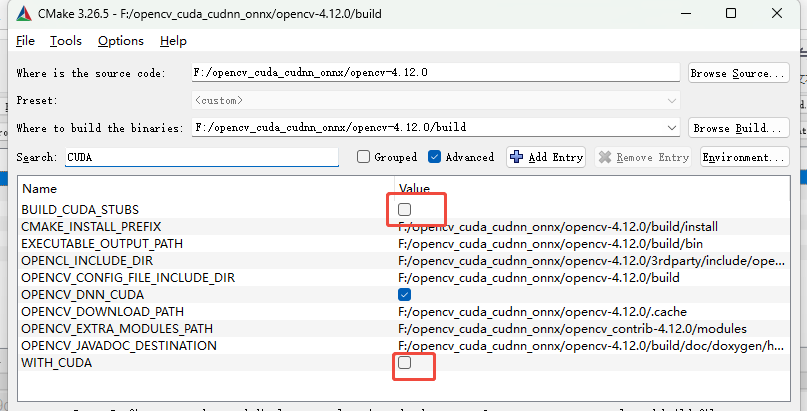
搜索CUDA,勾选✅BUILD CUDA STUBS、勾选✅WITH CUDA
点击Configure按钮
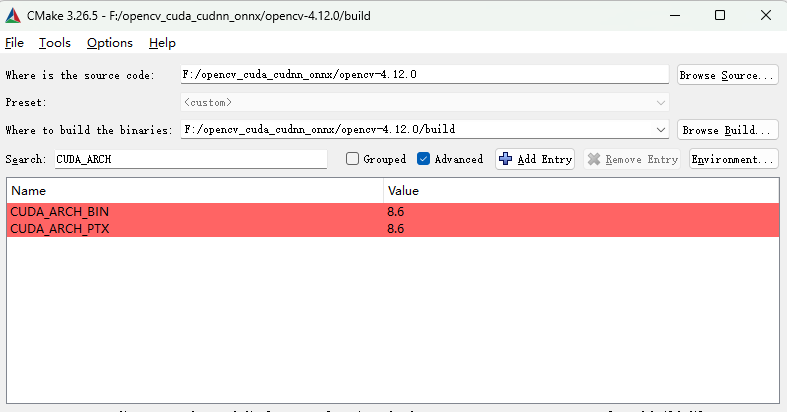
等待配置完毕,搜索CUDA_ARCH,同时修改CUDA_ARCH_PTX、勾选✅CUDA_ARCH_BIN为8.6
CUDA_ARCH_PTX 是 CUDA 编译过程中用于指定目标 GPU 架构的参数。它决定了生成的 PTX(Parallel Thread Execution)代码的架构版本。PTX 是一种中间表示形式,可以在运行时由 CUDA 驱动程序编译为特定 GPU 架构的机器代码。
CUDA_ARCH_BIN这个值代表了显卡的计算能力,是编译过程中重要的参数,显卡型号对应的至可参考NVIDIA显卡对应opencv的CUDA_ARCH_BIN算力值
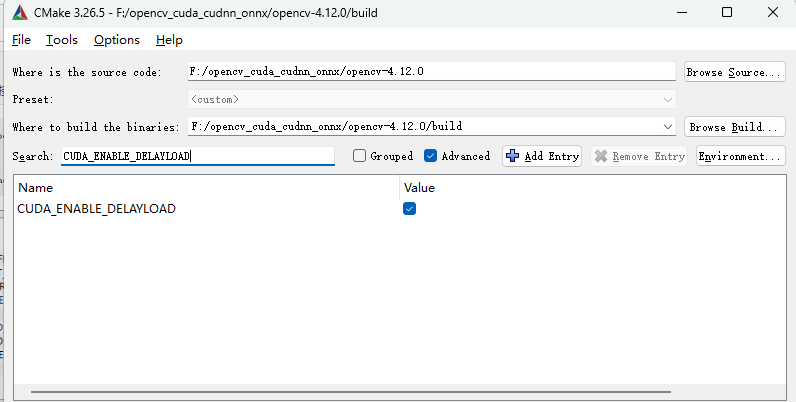
搜索CUDA_ENABLE_DELAYLOAD勾选✅
启用 CUDA 延迟加载(Delay-Load)机制
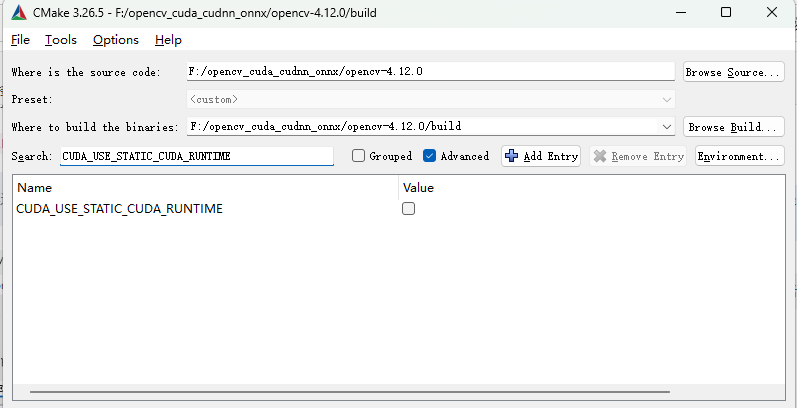
搜索CUDA_USE_STATIC_CUDA_RUNTIME取消勾选❌
编译时不启用静态编译
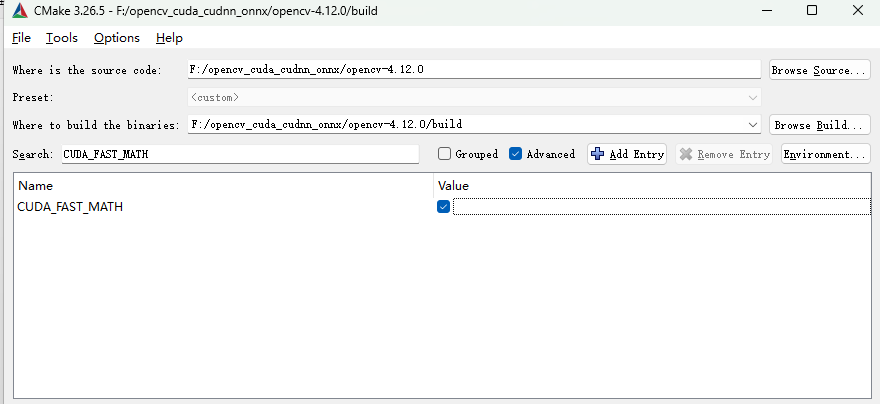
搜索CUDA_FAST_MATH勾选✅
通过牺牲一定的精度来显著提升计算性能,编译选项后CUDA 会将标准数学函数替换为其快速版本,需结合实际情况选择
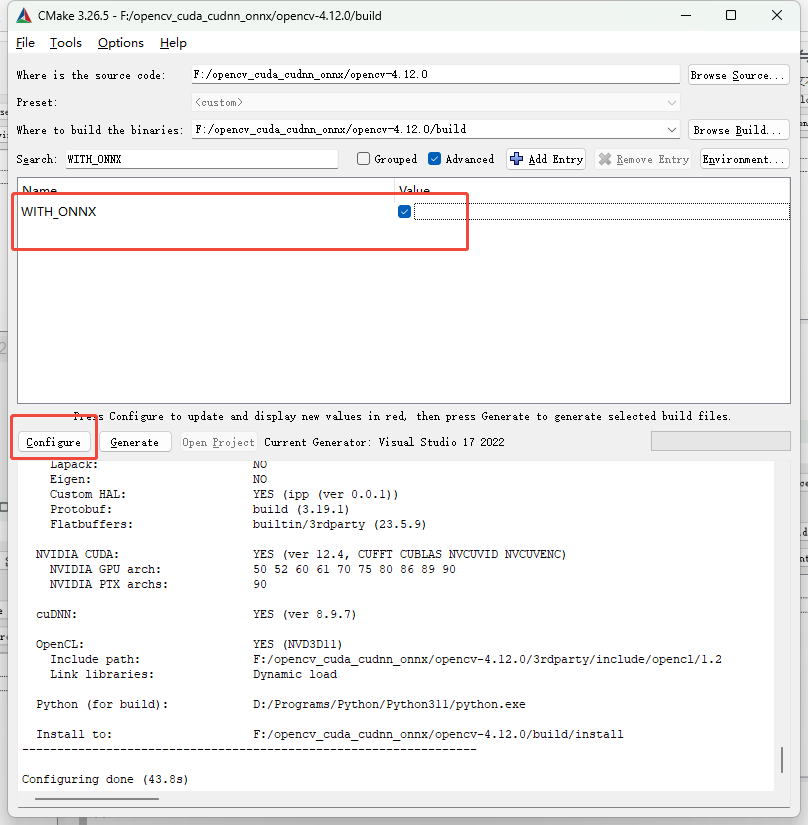
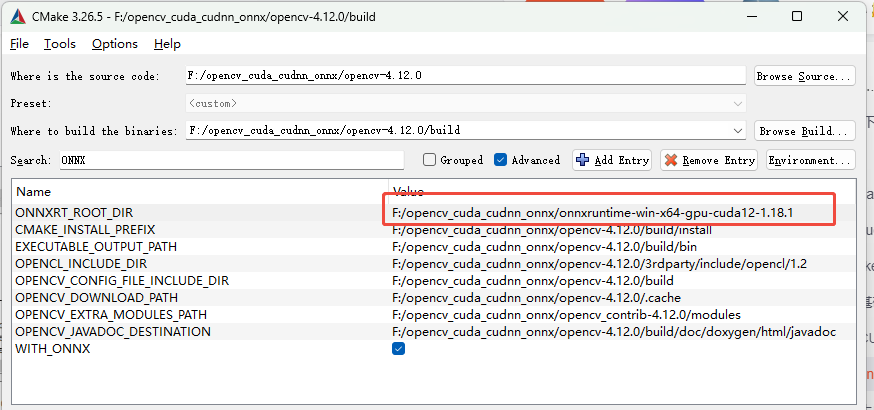
ONNXRuntime
搜索WITH_ONNX勾选✅,点击Configure按钮
选择ONNXRT_ROOT_DIR解压路径,再次点击Configure按钮
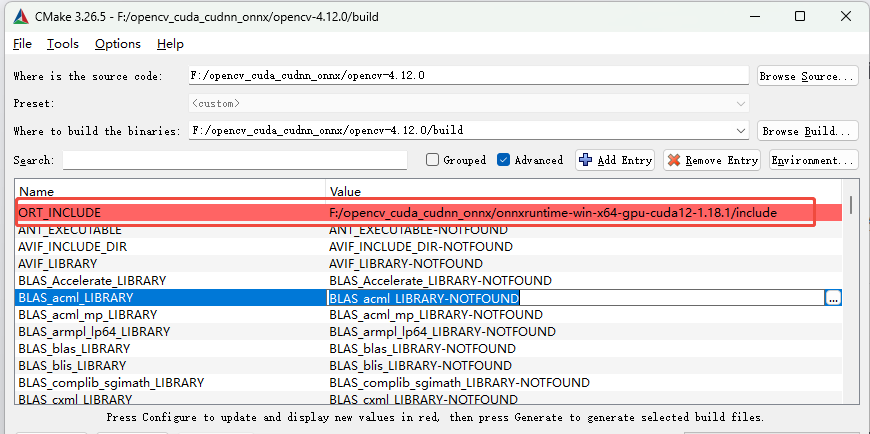
选择ORT_INCLUDE到include目录,再次点击Configure按钮
配置好后还有红色的选项,再次点击Configure按钮
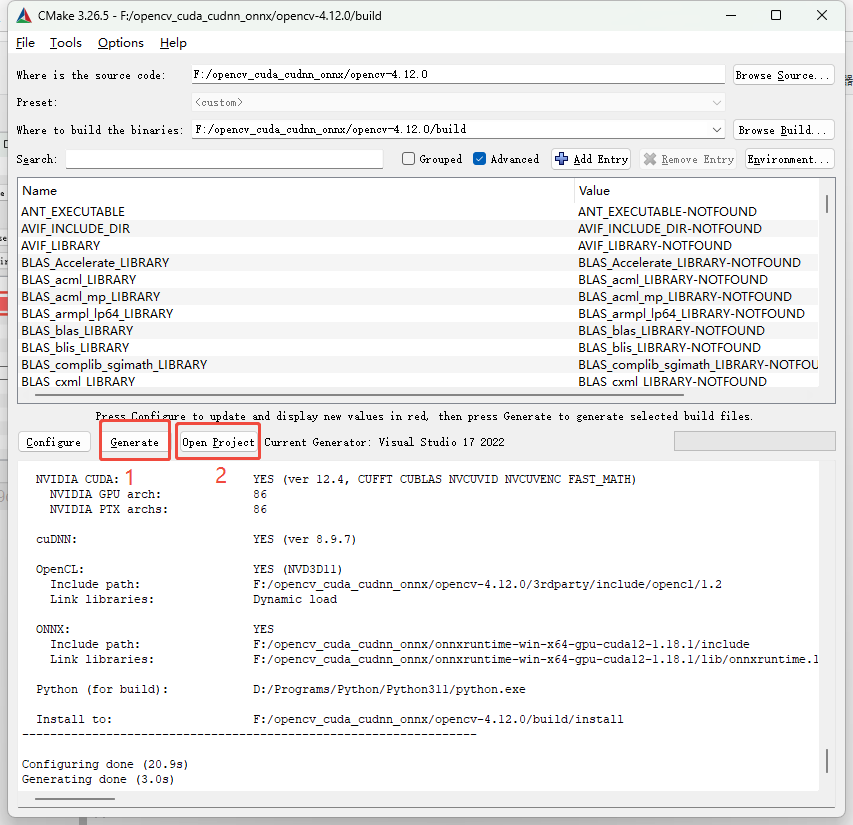
生成
如下图所示先后点击Generate、Open Project,打开VS2022
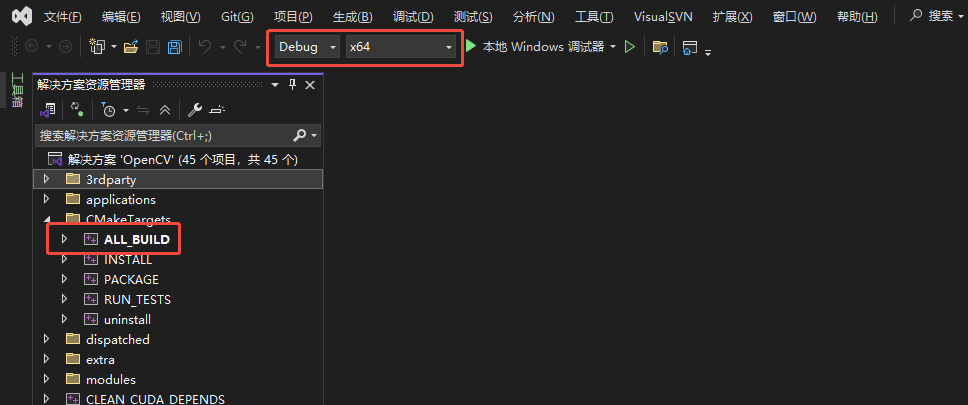
编译
解决方案资源管理器中选择CMakeTargets>ALL_BUILD>右键点击生成
Debug和Release模式都是一样的操作
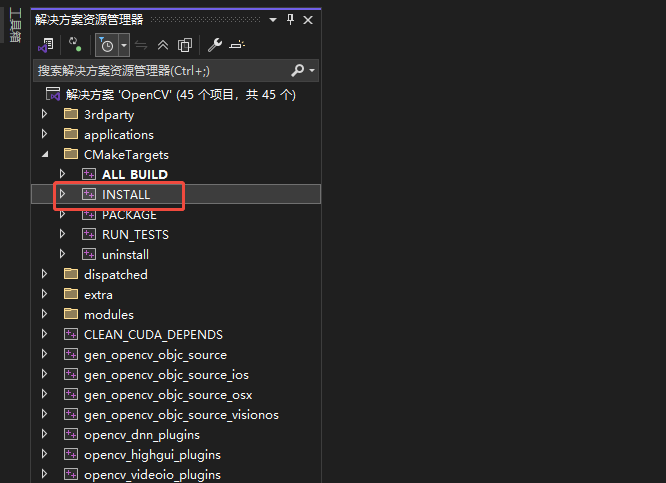
安装
解决方案资源管理器中选择CMakeTargets>INSTALL>右键点击生成
Debug和Release模式都是一样的操作
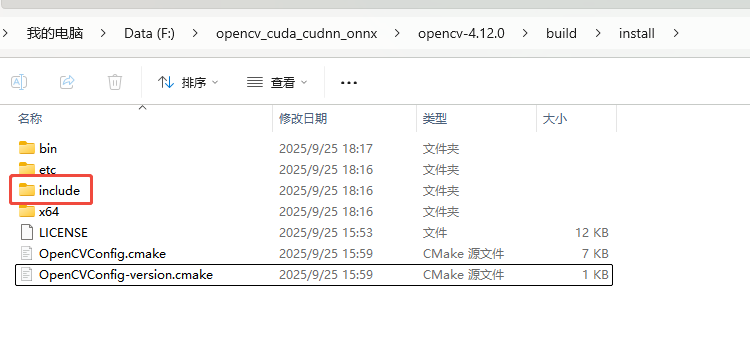
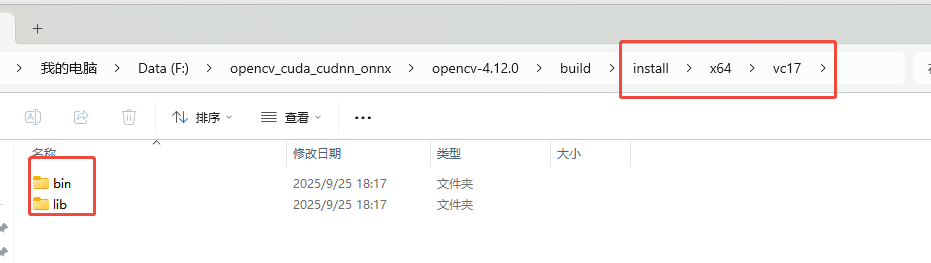
最后生成的库在目录opencv-4.12.0\build\install目录中
获取onnx模型
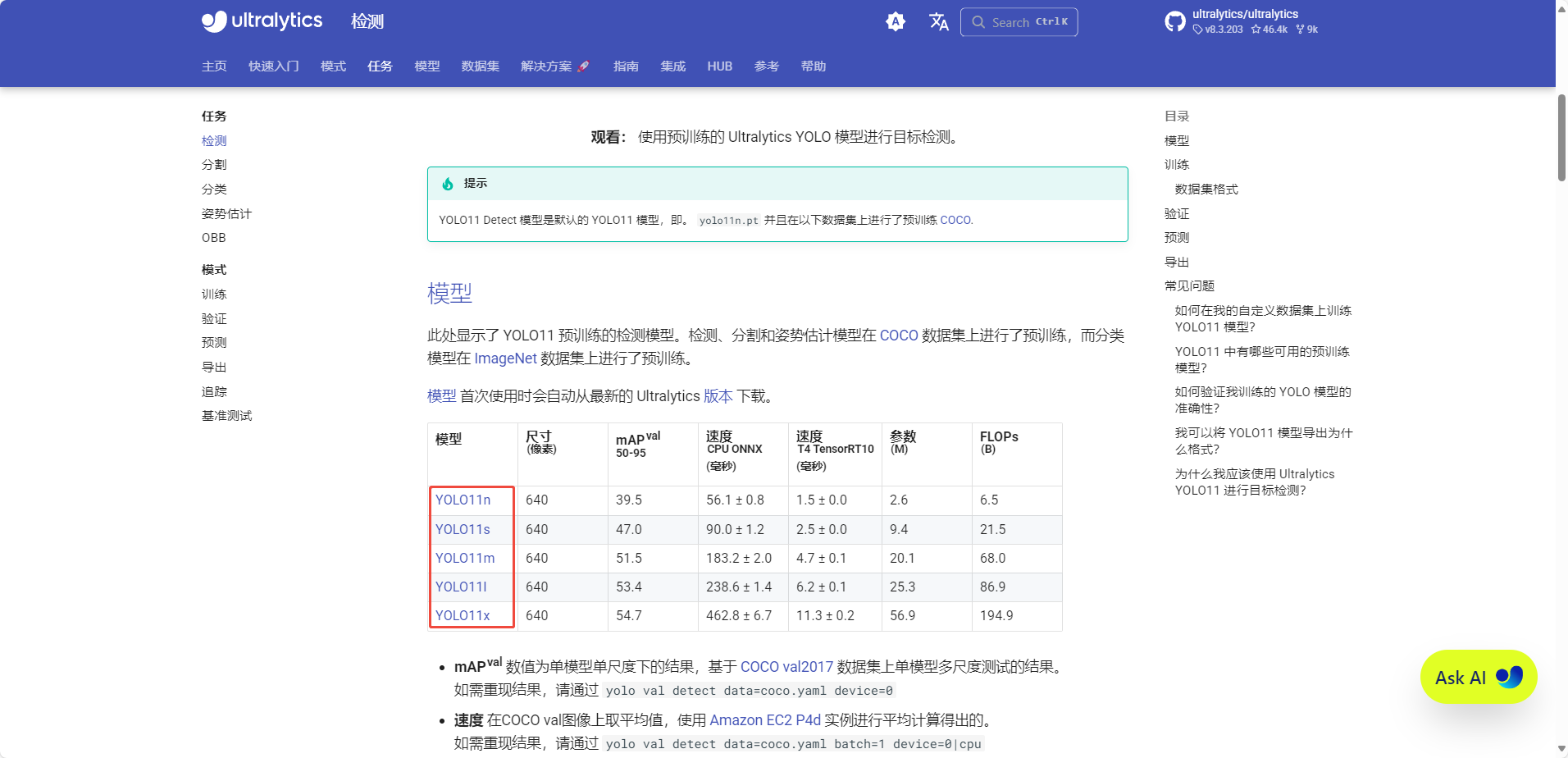
模型下载
用yolo11官方提供的模型进行测试,下载链接https://docs.ultralytics.com/zh/tasks/segment/#models
模型转换
可通过如下Python脚本将模型转换为onnx格式,推进使用yolo11s识别效果较好且GPU利用率适中
from ultralytics import YOLO
# 加载模型
model = YOLO('yolo11s.pt') # 确保模型文件在当前目录
# 关键修改:添加 device='cpu'
model.export(
format='onnx',
imgsz=640,
batch=1,
dynamic=False,
simplify=True,
opset=13,
device='cpu' # 重要!指定使用 CPU
)
print("✅ yolo11s 已成功导出为 ONNX 格式!")
device是指转换模型采用GPU或CPU,本示例用的是CPU,速度也挺快的
导出后的.onnx模型文件是一个通用的、与设备无关的中间表示(IR)
你在后续使用推理时,可以自由选择是在CPU还是GPU上运行
模型推理
模型推理类
代码是基于yolo仓库提供的示例修改的,添加了简单的GPU降级处理,虽然该示例是针对yolov8和yolov5的,但测试下来yolov11的模型也适用
// h文件
// Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
#ifndef INFERENCE_H
#define INFERENCE_H
// Cpp native
#include <fstream>
#include <vector>
#include <string>
#include <random>
// OpenCV / DNN / Inference
#include <opencv2/imgproc.hpp>
#include <opencv2/opencv.hpp>
#include <opencv2/dnn.hpp>
struct Detection
{
int class_id{
0};
std::string className{
};
float confidence{
0.0};
cv::Scalar color{
};
cv::Rect box{
};
};
class Inference
{
public:
Inference(const std::string &onnxModelPath, const cv::Size &modelInputShape = {
640, 640}, const bool &runWithCuda = true);
std::vector<Detection> runInference(const cv::Mat &input);
private:
void loadOnnxNetwork();
cv::Mat formatToSquare(const cv::Mat &source, int *pad_x, int *pad_y, float *scale);
bool infer_on_gpu(cv::Mat& blob, std::vector<cv::Mat>& outputs);
bool infer_on_cpu(cv::Mat& blob, std::vector<cv::Mat>& outputs);
std::string modelPath{
};
std::string classesPath{
};
bool cudaEnabled{
};
std::vector<std::string> classes{
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"};
cv::Size2f modelShape{
};
float modelConfidenceThreshold {
0.25f};
float modelScoreThreshold {
0.45f};
float modelNMSThreshold {
0.50f};
bool letterBoxForSquare = true;
cv::dnn::Net net;
};
#endif // INFERENCE_H
//cpp文件
// Ultralytics 🚀 AGPL-3.0 License - https://ultralytics.com/license
#include "pch.h"
#include "inference.h"
Inference::Inference(const std::string& onnxModelPath, const cv::Size& modelInputShape, const bool& runWithCuda)
{
modelPath = onnxModelPath;
modelShape = modelInputShape;
cudaEnabled = runWithCuda;
loadOnnxNetwork();
}
std::vector<Detection> Inference::runInference(const cv::Mat& input)
{
cv::Mat modelInput = input;
int pad_x, pad_y;
float scale;
if (letterBoxForSquare && modelShape.width == modelShape.height)
modelInput = formatToSquare(modelInput, &pad_x, &pad_y, &scale);
cv::Mat blob;
cv::dnn::blobFromImage(modelInput, blob, 1.0 / 255.0, modelShape, cv::Scalar(), true, false);
std::vector<cv::Mat> outputs;
//如果GPU不可用则自动降级为CPU推理
if (!infer_on_gpu(blob, outputs))
infer_on_cpu(blob, outputs);
int rows = outputs[0].size[1];
int dimensions = outputs[0].size[2];
bool yolov8 = false;
// yolov5 has an output of shape (batchSize, 25200, 85) (Num classes + box[x,y,w,h] + confidence[c])
// yolov8 has an output of shape (batchSize, 84, 8400) (Num classes + box[x,y,w,h])
if (dimensions > rows) // Check if the shape[2] is more than shape[1] (yolov8)
{
yolov8 = true;
rows = outputs[0].size[2];
dimensions = outputs[0].size[1];
outputs[0] = outputs[0].reshape(1, dimensions);
cv::transpose(outputs[0], outputs[0]);
}
float* data = (float*)outputs[0].data;
std::vector<int> class_ids;
std::vector<float> confidences;
std::vector<cv::Rect> boxes;
for (int i = 0; i < rows; ++i)
{
if (yolov8)
{
float* classes_scores = data + 4;
cv::Mat scores(1, static_cast<int>(classes.size()), CV_32FC1, classes_scores);
cv::Point class_id;
double maxClassScore;
minMaxLoc(scores, 0, &maxClassScore, 0, &class_id);
if (maxClassScore > modelScoreThreshold)
{
confidences.push_back(static_cast<float> (maxClassScore));
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w - pad_x) / scale);
int top = int((y - 0.5 * h - pad_y) / scale);
int width = int(w / scale);
int height = int(h / scale);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
else // yolov5
{
float confidence = data[4];
if (confidence >= modelConfidenceThreshold)
{
float* classes_scores = data + 5;
cv::Mat scores(1, static_cast<int> (classes.size()), CV_32FC1, classes_scores);
cv::Point class_id;
double max_class_score;
minMaxLoc(scores, 0, &max_class_score, 0, &class_id);
if (max_class_score > modelScoreThreshold)
{
confidences.push_back(confidence);
class_ids.push_back(class_id.x);
float x = data[0];
float y = data[1];
float w = data[2];
float h = data[3];
int left = int((x - 0.5 * w - pad_x) / scale);
int top = int((y - 0.5 * h - pad_y) / scale);
int width = int(w / scale);
int height = int(h / scale);
boxes.push_back(cv::Rect(left, top, width, height));
}
}
}
data += dimensions;
}
std::vector<int> nms_result;
cv::dnn::NMSBoxes(boxes, confidences, modelScoreThreshold, modelNMSThreshold, nms_result);
std::vector<Detection> detections{
};
for (unsigned long i = 0; i < nms_result.size(); ++i)
{
int idx = nms_result[i];
Detection result;
result.class_id = class_ids[idx];
result.confidence = confidences[idx];
std::random_device rd;
std::mt19937 gen(rd());
std::uniform_int_distribution<int> dis(100, 255);
result.color = cv::Scalar(dis(gen),
dis(gen),
dis(gen));
result.className = classes[result.class_id];
result.box = boxes[idx];
detections.push_back(result);
}
return detections;
}
void Inference::loadOnnxNetwork()
{
// 重置当前 CUDA 设备
cv::cuda::resetDevice();
// 加载模型
net = cv::dnn::readNetFromONNX(modelPath);
if (cudaEnabled)
{
std::cout << "\nRunning on CUDA" << std::endl;
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
else
{
std::cout << "\nRunning on CPU" << std::endl;
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
}
}
cv::Mat Inference::formatToSquare(const cv::Mat& source, int* pad_x, int* pad_y, float* scale)
{
int col = source.cols;
int row = source.rows;
int m_inputWidth = static_cast<int> (modelShape.width);
int m_inputHeight = static_cast<int> (modelShape.height);
*scale = std::min(m_inputWidth / (float)col, m_inputHeight / (float)row);
int resized_w = static_cast<int> (col * *scale);
int resized_h = static_cast<int> (row * *scale);
*pad_x = (m_inputWidth - resized_w) / 2;
*pad_y = (m_inputHeight - resized_h) / 2;
cv::Mat resized;
cv::resize(source, resized, cv::Size(resized_w, resized_h));
cv::Mat result = cv::Mat::zeros(m_inputHeight, m_inputWidth, source.type());
resized.copyTo(result(cv::Rect(*pad_x, *pad_y, resized_w, resized_h)));
resized.release();
return result;
}
bool Inference::infer_on_gpu(cv::Mat& blob, std::vector<cv::Mat>& outputs)
{
try {
net.setPreferableBackend(cv::dnn::DNN_BACKEND_CUDA);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
net.setInput(blob);
net.forward(outputs, net.getUnconnectedOutLayersNames());
return true;
}
catch (...) {
return false;
}
}
bool Inference::infer_on_cpu(cv::Mat& blob, std::vector<cv::Mat>& outputs)
{
net.setPreferableBackend(cv::dnn::DNN_BACKEND_OPENCV);
net.setPreferableTarget(cv::dnn::DNN_TARGET_CUDA);
net.setInput(blob);
net.forward(outputs, net.getUnconnectedOutLayersNames());
return true;
}
