1.简介
在人工智能领域,一款名为DeepSeek-R1的模型正以其卓越的性能和极具竞争力的成本迅速崭露头角,引发了全球范围内的广泛关注。这款模型不仅在多个基准测试中表现出色,还因其开源的特性,为全球开发者和研究人员提供了前所未有的便利。
与此同时,HuggingFace推出的Open-R1项目致力于完全复现DeepSeek-R1的开发流程,并将其开源,以便更多人能够参与到这一前沿技术的探索中。Open-R1是以Qwen2.5-1.5B为基础,以deepseek-R1的训练过程打造的开源模型。该项目通过提供详细的训练脚本、评估工具以及数据生成方法,极大地降低了进入门槛,使得无论是独立研究人员、初创公司,还是业余爱好者,都能轻松上手并进行创新。
github地址:GitHub - huggingface/open-r1: Fully open reproduction of DeepSeek-R1
往期内容:Deepseek-R1:纯强化学习实现接近OpenAI o1水平(论文解读)_deepseek r1 论文-CSDN博客
-
-
2.原理回顾
训练过程
DeepSeek-R1的训练过程采用了多阶段策略,结合了监督微调(SFT)和强化学习(RL),最主要的阶段包括以下两个:
第一阶段:冷启动数据微调(SFT)
-
目标:让模型具备基本的推理能力,防止在后续强化学习阶段出现语言混乱或无意义的输出。
-
方法:
-
收集高质量的推理数据,包括数学推理、代码生成、长链推理等任务。
-
使用监督微调(SFT),让模型在有限的数据集上学习基础推理逻辑。
-
通过人工筛选和数据优化,提高模型的可读性和表达能力。
-
第二阶段:推理任务强化学习(GRPO)
-
目标:增强模型的推理能力,使其能够更好地处理复杂任务。
-
方法:
-
使用群体相对策略优化(GRPO)算法进行强化学习,结合准确性和格式奖励,以增强推理能力。
-
通过奖励机制对模型生成的回答进行评分,调整模型策略以提高未来回答的质量。
-
-
组相对策略优化(GRPO)
其中组相对策略优化(GRPO)是DeepSeek-R1模型中采用的一种创新的强化学习算法,旨在优化大型语言模型(LLMs)在复杂任务中的表现,如数学推理和代码生成。Open-R1中最值得学习的就是GRPO的复现代码。
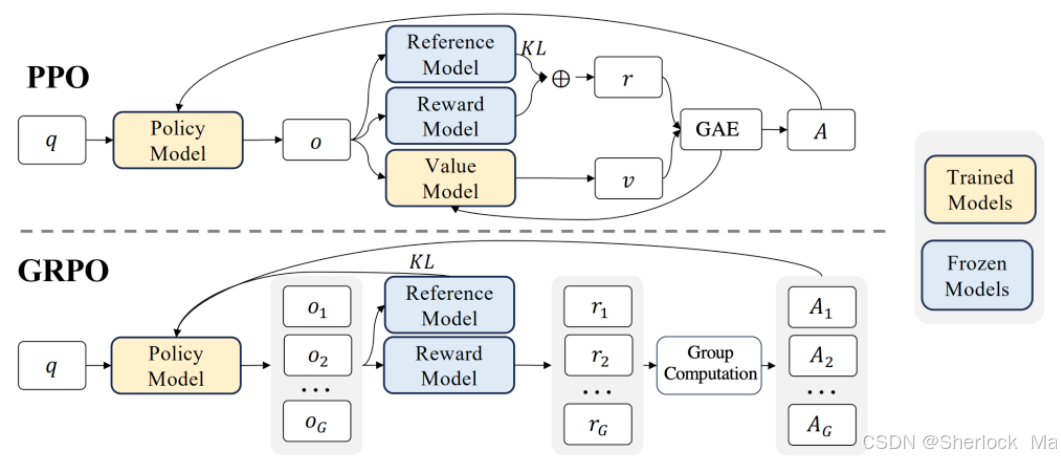
GRPO的核心思想是通过组内相对奖励来优化模型策略,而不是依赖传统的批评模型(critic model),从而简化了训练过程。在GRPO中,对于每个输入问题,模型会从当前策略中采样一组输出(例如16个候选解),然后根据这些输出的相对表现来计算奖励。具体来说,GRPO会计算组内奖励的均值和标准差,以此来归一化每个输出的优势函数。这种方法避免了传统PPO算法中需要额外训练价值模型的高成本。通过这种方式,GRPO能够更高效地调整策略模型的参数,以提高未来输出的质量。
GRPO的这种设计不仅降低了训练成本,还提高了计算效率,使得算法能够在单卡环境下完成训练。此外,GRPO直接将KL散度项集成到损失函数中,用于正则化策略模型,避免了在奖励信号中使用复杂的KL惩罚。这种直接的KL散度优化方式使得GRPO在优化过程中能够实现更精细的控制。
总的来说,GRPO通过组内相对奖励的机制,提供了一种更高效且简化的强化学习方法,特别适合于大型语言模型的优化。
-
-
3.环境配置
首先,本项目依赖于Python3.11和CUDA12.1,请确保虚拟环境的正确。
安装vllm==0.7.0并配置环境路径
pip install vllm>=0.7.0 --extra-index-url https://download.pytorch.org/whl/cu121
export LD_LIBRARY_PATH=$(python -c "import site; print(site.getsitepackages()[0] + '/nvidia/nvjitlink/lib')"):$LD_LIBRARY_PATH
安装其他依赖库(注意,一定是pytorch2.5.1)
pip install -e ".[dev]"注册huggingface和wandb
huggingface-cli login
wandb login在注册huggingface的时候显示以下界面
(open-r1) good@good:/media/good/4TB/mn/model/llm/open-r1-main$ huggingface-cli login
_| _| _| _| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _|_|_|_| _|_| _|_|_| _|_|_|_|
_| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_|_|_|_| _| _| _| _|_| _| _|_| _| _| _| _| _| _|_| _|_|_| _|_|_|_| _| _|_|_|
_| _| _| _| _| _| _| _| _| _| _|_| _| _| _| _| _| _| _|
_| _| _|_| _|_|_| _|_|_| _|_|_| _| _| _|_|_| _| _| _| _|_|_| _|_|_|_|
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Enter your token (input will not be visible):
你需要点击网页:https://huggingface.co/settings/tokens
然后点击Create New Token,全选其中所有可选项,保存后复制token,粘贴到命令行,注意命令行不显示token,然后回车。
出现下面的界面说明成功了
Token has not been saved to git credential helper.
Your token has been saved to /home/good/.cache/huggingface/token
Login successful.
The current active token is: `open-r1`
-
-
4.sft
数据集和权重
数据集地址:https://huggingface.co/datasets/bespokelabs/Bespoke-Stratos-17k
初始模型权重地址:https://huggingface.co/Qwen/Qwen2.5-1.5B-Instruct
- 下载完成后注意修改recipes/qwen/Qwen2.5-1.5B-Instruct/sft/config_full.yaml的model_name_or_path和dataset_name,以匹配模型和数据集的位置。
-
sft阶段代码位于src/open_r1/sft.py,使用以下代码运行
ACCELERATE_LOG_LEVEL=info accelerate launch --config_file recipes/accelerate_configs/zero3.yaml src/open_r1/sft.py --config recipes/qwen/Qwen2.5-1.5B-Instruct/sft/config_full.yaml或者在pycharm中仅仅设置参数:
--config recipes/qwen/Qwen2.5-1.5B-Instruct/sft/config_full.yaml3090Ti 24G显存能以batch-size=1的条件下运行,训练一轮大约6小时
-
代码解析
由于sft是大模型训练的常规过程,这里就简单介绍一下。
首先加载数据集和tokenizer
################
# Load datasets
################
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
################
# Load tokenizer
################
tokenizer = AutoTokenizer.from_pretrained(
model_args.model_name_or_path, trust_remote_code=model_args.trust_remote_code, use_fast=True
)
tokenizer.pad_token = tokenizer.eos_token配置模型参数
###################
# Model init kwargs
###################
logger.info("*** Initializing model kwargs ***")
torch_dtype = ( # 根据配置选择合适的 torch_dtype 类型
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
quantization_config = get_quantization_config(model_args) # 获取量化配置 quantization_config。
model_kwargs = dict( # 构建模型初始化参数字典 model_kwargs
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
device_map=get_kbit_device_map() if quantization_config is not None else None,
quantization_config=quantization_config,
)
training_args.model_init_kwargs = model_kwargs设置训练器
############################
# Initialize the SFT Trainer
############################
trainer = SFTTrainer(
model=model_args.model_name_or_path, # 指定模型路径
args=training_args, # 指定训练参数
train_dataset=dataset[script_args.dataset_train_split], # 指定训练数据集
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None, # 指定测试数据集
processing_class=tokenizer, # 指定tokenizer
peft_config=get_peft_config(model_args),
callbacks=get_callbacks(training_args, model_args),
)训练与保存
###############
# Training loop
###############
logger.info("*** Train ***")
checkpoint = None
if training_args.resume_from_checkpoint is not None: # 确定从哪个检查点恢复训练,优先使用 training_args.resume_from_checkpoint,其次使用 last_checkpoint。
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint) # 训练模型,并返回训练结果。
metrics = train_result.metrics
metrics["train_samples"] = len(dataset[script_args.dataset_train_split]) # 获取训练数据集的大小,并保存到 metrics 中。
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state() # 保存训练状态
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
trainer.save_model(training_args.output_dir) # 保存模型到指定路径。
logger.info(f"Model saved to {training_args.output_dir}")测试
##########
# Evaluate
##########
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate() # 调用 trainer.evaluate() 进行评估,并获取评估结果 metrics
metrics["eval_samples"] = len(dataset[script_args.dataset_test_split]) # 调用 trainer.evaluate() 进行评估,并获取评估结果 metrics
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)-
-
5.grpo
数据集和权重
数据集地址:https://huggingface.co/datasets/AI-MO/NuminaMath-TIR
初始模型权重地址:https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B/tree/main
- 下载完成后注意修改recipes/qwen/Qwen2.5-1.5B-Instruct/grpo/confg_full.yaml的model_name_or_path和dataset_name,以匹配模型和数据集的位置。
- 然后修改num_processes,如果你有8块GPU,需设置为7(因为vllm需要占用一块GPU),以此类推。(如果只有一块GPU,建议直接将use_vllm改为false,然后将num_processes改为1)
外部代码解析
在Open-r1中,整个GRPO的流程被封装在trl库中,用户可以直接调用,快速使用。我们先来看外部调用代码。
奖励函数
具体来说,奖励函数包括两个:准确率奖励(accuracy_reward)和格式奖励(format_reward)。准确率奖励意味着解题越准确,分数越高;格式奖励意味着输出的格式越标准,分数越高。
@dataclass
class GRPOScriptArguments(ScriptArguments):
"""
Script arguments for the GRPO training script.
Args:
reward_funcs (`list[str]`):
List of reward functions. Possible values: 'accuracy', 'format'.
"""
reward_funcs: list[str] = field( # 它包含一个列表类型的参数 reward_funcs,默认值为 ["accuracy", "format"],用于指定奖励函数的类型。
default_factory=lambda: ["accuracy", "format"],
metadata={"help": "List of reward functions. Possible values: 'accuracy', 'format'"},
)
def accuracy_reward(completions, solution, **kwargs):
"""Reward function that checks if the completion is the same as the ground truth.用于计算生成内容与标准答案的匹配度。"""
contents = [completion[0]["content"] for completion in completions]
rewards = []
for content, sol in zip(contents, solution): # 遍历每个完成项和对应的标准答案,解析标准答案。
gold_parsed = parse(sol, extraction_mode="first_match", extraction_config=[LatexExtractionConfig()])
if len(gold_parsed) != 0: # 如果标准答案可解析,则进一步解析生成内容并验证其正确性,返回匹配度分数(1或0)。
# We require the answer to be provided in correct latex (no malformed operators)
answer_parsed = parse(
content,
extraction_config=[
LatexExtractionConfig(
normalization_config=NormalizationConfig(
nits=False,
malformed_operators=False,
basic_latex=True,
equations=True,
boxed=True,
units=True,
),
# Ensures that boxed is tried first
boxed_match_priority=0,
try_extract_without_anchor=False,
)
],
extraction_mode="first_match",
)
# Reward 1 if the content is the same as the ground truth, 0 otherwise
reward = float(verify(answer_parsed, gold_parsed))
else: # 如果标准答案不可解析,则直接返回1并跳过该条目
# If the gold solution is not parseable, we reward 1 to skip this example
reward = 1.0
print("Failed to parse gold solution: ", sol)
rewards.append(reward)
return rewards
def format_reward(completions, **kwargs):
"""使用正则表达式匹配格式Reward function that checks if the completion has a specific format."""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]加载数据集、设置奖励函数、设置模型
# Load the dataset
dataset = load_dataset(script_args.dataset_name, name=script_args.dataset_config)
# Get reward functions
reward_funcs = [reward_funcs_registry[func] for func in script_args.reward_funcs]
torch_dtype = (
model_args.torch_dtype if model_args.torch_dtype in ["auto", None] else getattr(torch, model_args.torch_dtype)
)
model_kwargs = dict(
revision=model_args.model_revision,
trust_remote_code=model_args.trust_remote_code,
attn_implementation=model_args.attn_implementation,
torch_dtype=torch_dtype,
use_cache=False if training_args.gradient_checkpointing else True,
)
training_args.model_init_kwargs = model_kwargs设置trainer
#############################
# Initialize the GRPO trainer
#############################
trainer = GRPOTrainer(
model=model_args.model_name_or_path, # 指定模型路径
reward_funcs=reward_funcs, # 指定奖励函数
args=training_args,
train_dataset=dataset[script_args.dataset_train_split], # 指定训练集
eval_dataset=dataset[script_args.dataset_test_split] if training_args.eval_strategy != "no" else None,
peft_config=get_peft_config(model_args), # 指定PEFT配置
callbacks=get_callbacks(training_args, model_args), # 指定回调函数
)训练和保存
###############
# Training loop
###############
checkpoint = None
if training_args.resume_from_checkpoint is not None:
checkpoint = training_args.resume_from_checkpoint
elif last_checkpoint is not None:
checkpoint = last_checkpoint
train_result = trainer.train(resume_from_checkpoint=checkpoint) # 训练模型,并返回训练结果。
metrics = train_result.metrics
metrics["train_samples"] = len(dataset[script_args.dataset_train_split]) # 获取训练数据集的大小,并保存到 metrics 中。
trainer.log_metrics("train", metrics)
trainer.save_metrics("train", metrics)
trainer.save_state() # 保存训练状态
##################################
# Save model and create model card
##################################
logger.info("*** Save model ***")
trainer.save_model(training_args.output_dir) # 保存模型到指定路径。
logger.info(f"Model saved to {training_args.output_dir}")评估
##########
# Evaluate
##########
if training_args.do_eval:
logger.info("*** Evaluate ***")
metrics = trainer.evaluate()
metrics["eval_samples"] = len(dataset[script_args.dataset_test_split])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)GRPO代码解析
初始化,包括以下步骤
- 初始化主模型,也就是被训练的模型
- 初始化参考模型。参考模型不仅提供了一个稳定的基线,还用于计算奖励、防止过拟合、计算策略偏差以及生成对比样本。这些功能使得参考模型成为优化主模型性能的重要工具。
- 初始化处理类,即Tokenizer
- 处理奖励函数
- 奖励函数可以是一个列表,也可以是一个单独的对象。如果是一个单独的对象,则将其包装为一个列表。
- 如果奖励函数是一个字符串(表示模型的路径或名称),则加载一个预训练的序列分类模型。
num_labels=1表示这是一个回归任务(输出一个奖励值)。
- 设置奖励处理类。奖励处理类(Reward Processing Class) 是一个用于处理和准备奖励函数输入的组件。它的主要作用是确保输入数据的格式和内容符合奖励函数的要求,从而使得奖励函数能够正确地计算奖励值。
参考模型(Reference Model)的作用
在强化学习(Reinforcement Learning, RL)或类似的自然语言处理(NLP)任务中,参考模型(Reference Model) 是一个非常重要的概念。它通常用于以下几个方面:
1. 作为基线模型
参考模型通常是主模型的一个静态副本,用于提供一个固定的性能基线。在强化学习中,主模型(即策略网络)会不断更新以优化其行为,而参考模型则保持不变。通过比较主模型和参考模型的输出,可以评估主模型的改进是否有效。
2. 计算奖励(Rewards)
在强化学习中,奖励函数用于评估生成的文本或行为的质量。参考模型可以用来计算这些奖励。例如,通过比较主模型生成的文本和参考模型生成的文本,可以计算出奖励值,从而指导主模型的训练。
3. 防止过拟合
参考模型可以作为一个稳定的参考点,帮助防止主模型在训练过程中过拟合。通过定期与参考模型进行比较,可以确保主模型不会偏离初始的性能太远。
4. 计算策略偏差(Policy Deviation)
在某些强化学习任务中,参考模型可以用来计算策略偏差,即主模型的策略与初始策略之间的差异。这种偏差可以用来调整学习率或决定是否需要恢复到更稳定的策略。
5. 生成对比样本
参考模型可以生成对比样本,用于训练主模型。这些对比样本可以帮助主模型学习到更鲁棒的特征表示,从而提高其在实际任务中的表现。
总结
参考模型在强化学习和自然语言处理任务中扮演了重要的角色。它不仅提供了一个稳定的基线,还用于计算奖励、防止过拟合、计算策略偏差以及生成对比样本。这些功能使得参考模型成为优化主模型性能的重要工具。
代码如下:
# Models
# 1.Trained model 初始化主模型,也就是被训练的模型
model_init_kwargs = args.model_init_kwargs or {}
if isinstance(model, str):
model_id = model
torch_dtype = model_init_kwargs.get("torch_dtype") # 模型的权重数据类型
...
model_init_kwargs["use_cache"] = (
False if args.gradient_checkpointing else model_init_kwargs.get("use_cache")
)
model = AutoModelForCausalLM.from_pretrained(model, **model_init_kwargs)
# 2.Reference model 初始化参考模型 它不仅提供了一个稳定的基线,还用于计算奖励、防止过拟合、计算策略偏差以及生成对比样本。这些功能使得参考模型成为优化主模型性能的重要工具。
if is_deepspeed_zero3_enabled(): # 是否启用了 DeepSpeed 的 ZeRO-3 优化。如果启用,会加载一个参考模型。
self.ref_model = AutoModelForCausalLM.from_pretrained(model_id, **model_init_kwargs)
elif peft_config is None:
# If PEFT configuration is not provided, create a reference model based on the initial model.
self.ref_model = create_reference_model(model) # 创建模型的静态参考副本,并将其设置为评估模式。
else:
# If PEFT is used, the reference model is not needed since the adapter can be disabled
# to revert to the initial model.
self.ref_model = None
# 3.Processing class 初始化处理类,即Tokenizer
if processing_class is None:
processing_class = AutoTokenizer.from_pretrained(model.config._name_or_path, padding_side="left")
# 4.Reward functions 奖励函数
if not isinstance(reward_funcs, list): # 奖励函数可以是一个列表,也可以是一个单独的对象。如果是一个单独的对象,则将其包装为一个列表。
reward_funcs = [reward_funcs]
for i, reward_func in enumerate(reward_funcs): # 如果奖励函数是一个字符串(表示模型的路径或名称),则加载一个预训练的序列分类模型。num_labels=1 表示这是一个回归任务(输出一个奖励值)。
if isinstance(reward_func, str):
reward_funcs[i] = AutoModelForSequenceClassification.from_pretrained(
reward_func, num_labels=1, **model_init_kwargs
)
self.reward_funcs = reward_funcs
# 5.Reward processing class奖励处理类
if reward_processing_classes is None: # 如果未提供奖励处理类,则为每个奖励函数创建一个默认的分词器。
reward_processing_classes = [None] * len(reward_funcs)
elif not isinstance(reward_processing_classes, list):
reward_processing_classes = [reward_processing_classes]
else:
if len(reward_processing_classes) != len(reward_funcs):
raise ValueError("The number of reward processing classes must match the number of reward functions.")
for i, (reward_processing_class, reward_func) in enumerate(zip(reward_processing_classes, reward_funcs)):
if isinstance(reward_func, PreTrainedModel):
if reward_processing_class is None:
reward_processing_class = AutoTokenizer.from_pretrained(reward_func.config._name_or_path) # 加载与奖励函数模型匹配的分词器。
if reward_processing_class.pad_token_id is None:
reward_processing_class.pad_token = reward_processing_class.eos_token
# The reward model computes the reward for the latest non-padded token in the input sequence.
# So it's important to set the pad token ID to the padding token ID of the processing class.
reward_func.config.pad_token_id = reward_processing_class.pad_token_id # 将奖励函数模型的填充标记 ID 设置为分词器的填充标记 ID,确保奖励计算时能够正确处理填充标记
reward_processing_classes[i] = reward_processing_class
self.reward_processing_classes = reward_processing_classes # 将奖励处理类列表存储为类的属性。-
训练
中间的其他过程并不重要,我们直接跳过,来看训练代码。
下面的代码定义了 Trainer 类中的 training_step 方法,用于在一个批次的输入上执行训练步骤。主要过程如下:
- 启动模型的训练
- 将输入转换为token ID,并生成对应的掩码
- 调用compute_loss计算损失
- 清理缓存并计算平均损失
class Trainer:
def training_step(
self, model: nn.Module, inputs: Dict[str, Union[torch.Tensor, Any]], num_items_in_batch=None
) -> torch.Tensor:
model.train()
if hasattr(self.optimizer, "train") and callable(self.optimizer.train):
self.optimizer.train()
inputs = self._prepare_inputs(inputs) # tokenize并生成掩码
...
with self.compute_loss_context_manager():
loss = self.compute_loss(model, inputs, num_items_in_batch=num_items_in_batch) # 计算损失
del inputs
if ( # 清理缓存
self.args.torch_empty_cache_steps is not None
and self.state.global_step % self.args.torch_empty_cache_steps == 0
):
if is_torch_xpu_available():
torch.xpu.empty_cache()
elif is_torch_mlu_available():
torch.mlu.empty_cache()
elif is_torch_musa_available():
torch.musa.empty_cache()
elif is_torch_npu_available():
torch.npu.empty_cache()
elif is_torch_mps_available(min_version="2.0"):
torch.mps.empty_cache()
else:
torch.cuda.empty_cache()
kwargs = {}
if self.args.n_gpu > 1: # 计算损失
loss = loss.mean() # mean() to average on multi-gpu parallel training
if self.use_apex:
with amp.scale_loss(loss, self.optimizer) as scaled_loss:
scaled_loss.backward()
else:
# Finally we need to normalize the loss for reporting
if not self.model_accepts_loss_kwargs and self.compute_loss_func is None:
loss = loss / self.args.gradient_accumulation_steps其中_prepare_inputs()函数用于对文本并进行预处理,并生成优势值(advantages)
这段代码是GRPOTrainer类中的_prepare_inputs方法,主要功能如下:
- 准备输入:从输入字典中提取提示文本并进行预处理。
- 生成补全:根据配置选择使用vLLM或常规生成方式生成补全文本。
- 处理补全文本:对生成的补全文本进行填充、拼接和掩码处理。
- 计算奖励:通过多个奖励函数计算生成文本的奖励,并归一化为优势值(advantages)。
-
计算每个生成的完成结果的总奖励。
-
计算每个组的平均奖励和标准差。
-
将平均奖励和标准差扩展到与原始奖励值相同的维度。
-
计算每个生成的完成结果的奖励与其所在组的平均奖励的差值。
-
将差值除以标准差(加上一个小常数),得到最终的优势值。
-
- 记录指标:将奖励和优势值记录到训练指标中。
解释
分组奖励:将生成的完成结果按组划分,每组包含多个生成结果。每个组的平均奖励和标准差用于衡量该组的整体表现。
优势值:衡量每个生成的完成结果相对于其所在组的平均表现的优势。如果一个生成结果的奖励高于其所在组的平均奖励,则其优势值为正;否则为负。通过标准化(除以标准差),优势值可以更好地反映每个生成结果的相对表现。计算公式:
其中:
Rewards 是每个生成的完成结果的总奖励。
Mean Grouped Rewards 是每个组的平均奖励。
Std Grouped Rewards 是每个组的奖励标准差。
ϵ 是一个小常数(如
1e-4),用于防止除以零的错误。
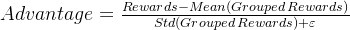
class GRPOTrainer(Trainer):
def _prepare_inputs(self, inputs: dict[str, Union[torch.Tensor, Any]]) -> dict[str, Union[torch.Tensor, Any]]:
# 1.从输入数据中提取提示文本,并对其进行预处理
device = self.accelerator.device
prompts = [x["prompt"] for x in inputs]
prompts_text = [maybe_apply_chat_template(example, self.processing_class)["prompt"] for example in inputs]
prompt_inputs = self.processing_class(
prompts_text, return_tensors="pt", padding=True, padding_side="left", add_special_tokens=False
)
prompt_inputs = super()._prepare_inputs(prompt_inputs)
prompt_ids, prompt_mask = prompt_inputs["input_ids"], prompt_inputs["attention_mask"]
if self.max_prompt_length is not None:
prompt_ids = prompt_ids[:, -self.max_prompt_length :]
prompt_mask = prompt_mask[:, -self.max_prompt_length :]
# 2.生成文本并分离生成的提示和完成部分 Generate completions using either vLLM or regular generation
if self.args.use_vllm:
...
else:
# Regular generation path
with unwrap_model_for_generation(self.model, self.accelerator) as unwrapped_model:
prompt_completion_ids = unwrapped_model.generate( # 使用 unwrap_model_for_generation 解包模型进行文本生成,得到完整的提示加完成的 ID 序列。
prompt_ids, attention_mask=prompt_mask, generation_config=self.generation_config
)
# Compute prompt length and extract completion ids
prompt_length = prompt_ids.size(1)
prompt_ids = prompt_completion_ids[:, :prompt_length]
completion_ids = prompt_completion_ids[:, prompt_length:]
prompt_mask = prompt_mask.repeat_interleave(self.num_generations, dim=0)
# 3.处理序列中的EOS标记,生成掩码 Mask everything after the first EOS token
is_eos = completion_ids == self.processing_class.eos_token_id # 找到每个序列中的EOS标记位置
eos_idx = torch.full((is_eos.size(0),), is_eos.size(1), dtype=torch.long, device=device)
eos_idx[is_eos.any(dim=1)] = is_eos.int().argmax(dim=1)[is_eos.any(dim=1)] # 更新 eos_idx 中有EOS标记的行,记录第一个EOS标记的位置。
sequence_indices = torch.arange(is_eos.size(1), device=device).expand(is_eos.size(0), -1) # 生成序列索引矩阵 sequence_indices
completion_mask = (sequence_indices <= eos_idx.unsqueeze(1)).int() # 创建掩码 completion_mask,标记所有在第一个EOS标记之前的位置。
# Concatenate prompt_mask with completion_mask for logit computation
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1) # (B*G, P+C)
logits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokens
# 4.计算参考模型的对数概率
with torch.inference_mode():
if self.ref_model is not None:
ref_per_token_logps = self._get_per_token_logps( # 计算参考模型 ref_model 在给定的输入 prompt_completion_ids 上每个 token 的对数概率。
self.ref_model, prompt_completion_ids, attention_mask, logits_to_keep
)
else:
...
# 5.解码生成的完成结果,并根据输入是否为对话格式进行处理。 Decode the generated completions
completions = self.processing_class.batch_decode(completion_ids, skip_special_tokens=True) # 使用 batch_decode 方法将 completion_ids 解码为文本,跳过特殊标记
if is_conversational(inputs[0]): # 如果输入是对话格式,则将每个完成结果封装为包含角色和内容的字典列表。
completions = [[{"role": "assistant", "content": completion}] for completion in completions]
# 6.计算奖励 Compute the rewards
prompts = [prompt for prompt in prompts for _ in range(self.num_generations)] # repeat prompts
rewards_per_func = torch.zeros(len(prompts), len(self.reward_funcs), device=device) # 初始化一个二维张量 rewards_per_func,用于存储每个奖励函数的奖励值。
for i, (reward_func, reward_processing_class) in enumerate(
zip(self.reward_funcs, self.reward_processing_classes)
):
if isinstance(reward_func, nn.Module): # Module instead of PretrainedModel for compat with compiled models
...
else:
# Repeat all input columns (but "prompt" and "completion") to match the number of generations
reward_kwargs = {key: [] for key in inputs[0].keys() if key not in ["prompt", "completion"]}
for key in reward_kwargs:
for example in inputs:
# Repeat each value in the column for `num_generations` times
reward_kwargs[key].extend([example[key]] * self.num_generations)
output_reward_func = reward_func(prompts=prompts, completions=completions, **reward_kwargs) # 调用奖励函数计算奖励
rewards_per_func[:, i] = torch.tensor(output_reward_func, dtype=torch.float32, device=device)
# 7.计算所有奖励函数的总和 Sum the rewards from all reward functions
rewards = rewards_per_func.sum(dim=1) # 计算所有奖励函数的总和,得到一个形状为 (B,) 的张量 rewards。
# 8.计算每组奖励的平均值和方差 Compute grouped-wise rewards
mean_grouped_rewards = rewards.view(-1, self.num_generations).mean(dim=1) # 计算每个分组的奖励均值 mean_grouped_rewards
std_grouped_rewards = rewards.view(-1, self.num_generations).std(dim=1) # 计算每个分组的奖励标准差 std_grouped_rewards
# 9.计算advantages Normalize the rewards to compute the advantages
mean_grouped_rewards = mean_grouped_rewards.repeat_interleave(self.num_generations, dim=0) # 将平均奖励和标准差重复扩展以匹配奖励的维度
std_grouped_rewards = std_grouped_rewards.repeat_interleave(self.num_generations, dim=0)
advantages = (rewards - mean_grouped_rewards) / (std_grouped_rewards + 1e-4) # 计算每个奖励与扩展后的平均奖励的差值, 将差值除以扩展后的标准差加一个小常数,防止除零错误。
# 10. Log the metrics 记录每个奖励函数的平均奖励值
reward_per_func = self.accelerator.gather_for_metrics(rewards_per_func).mean(0)
for i, reward_func in enumerate(self.reward_funcs):
if isinstance(reward_func, nn.Module): # Module instead of PretrainedModel for compat with compiled models
reward_func_name = reward_func.config._name_or_path.split("/")[-1]
else:
reward_func_name = reward_func.__name__
self._metrics[f"rewards/{reward_func_name}"].append(reward_per_func[i].item())
self._metrics["reward"].append(self.accelerator.gather_for_metrics(rewards).mean().item())
self._metrics["reward_std"].append(self.accelerator.gather_for_metrics(std_grouped_rewards).mean().item())接下来我们来看compute_loss(),注意,这个是GRPOTrainer覆写的函数,不是Trainer的函数,具体步骤如下:
- 分别用于表示提示部分、完整部分的ID及其对应的掩码。
- 调用self._get_per_token_logps(),使用模型计算每个输入 token 的对数概率。
- 计算KL散度(通过参考模型和主模型的对数概率的差异计算KL散度)并应用
- 记录信息。
class GRPOTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False, num_items_in_batch=None):
prompt_ids, prompt_mask = inputs["prompt_ids"], inputs["prompt_mask"] # 分别用于表示提示部分的ID及其对应的掩码。
completion_ids, completion_mask = inputs["completion_ids"], inputs["completion_mask"] # 分别用于表示完成部分的ID及其对应的掩码。
input_ids = torch.cat([prompt_ids, completion_ids], dim=1)
attention_mask = torch.cat([prompt_mask, completion_mask], dim=1)
logits_to_keep = completion_ids.size(1) # we only need to compute the logits for the completion tokens
per_token_logps = self._get_per_token_logps(model, input_ids, attention_mask, logits_to_keep) # 计算每个输入 token 的对数概率。
# 计算KL散度 Compute the KL divergence between the model and the reference model
ref_per_token_logps = inputs["ref_per_token_logps"] # 从输入中获取参考模型的每令牌对数概率
per_token_kl = torch.exp(ref_per_token_logps - per_token_logps) - (ref_per_token_logps - per_token_logps) - 1 # 计算每令牌的KL散度
# x - x.detach() allows for preserving gradients from x
advantages = inputs["advantages"]
per_token_loss = torch.exp(per_token_logps - per_token_logps.detach()) * advantages.unsqueeze(1) # 计算优势值加权的每token损失。
per_token_loss = -(per_token_loss - self.beta * per_token_kl) # 应用KL散度惩罚项调整每token损失。
loss = ((per_token_loss * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean() # 使用完成掩码对损失进行加权平均,最后求均值。
# Log the metrics
## 计算并记录完成长度
completion_length = self.accelerator.gather_for_metrics(completion_mask.sum(1)).float().mean().item() # 使用 gather_for_metrics 汇总所有进程的 completion_mask 并按行求和
self._metrics["completion_length"].append(completion_length)
## 计算每个样本的平均KL散度,并将结果收集到metrics中
mean_kl = ((per_token_kl * completion_mask).sum(dim=1) / completion_mask.sum(dim=1)).mean()
self._metrics["kl"].append(self.accelerator.gather_for_metrics(mean_kl).mean().item())
return loss
def _get_per_token_logps(self, model, input_ids, attention_mask, logits_to_keep): # 计算每个输入 token 的对数概率。
# We add 1 to `logits_to_keep` because the last logits of the sequence is later excluded
logits = model(
input_ids=input_ids, attention_mask=attention_mask, logits_to_keep=logits_to_keep + 1
).logits # (B, L, V) 调用模型获取 logits,增加 logits_to_keep 以排除最后一个 logit。
logits = logits[:, :-1, :] # (B, L-1, V), 排除最后一个 logit,因为它对应于下一个 token 的预测。
# Compute the log probabilities for the input tokens. Use a loop to reduce memory peak.
per_token_logps = []
for logits_row, input_ids_row in zip(logits, input_ids[:, -logits_to_keep:]): # 使用循环逐行计算每个 token 的对数概率,并减少内存峰值。
log_probs = logits_row.log_softmax(dim=-1)
token_log_prob = torch.gather(log_probs, dim=1, index=input_ids_row.unsqueeze(1)).squeeze(1)
per_token_logps.append(token_log_prob)
return torch.stack(per_token_logps) # 返回堆叠后的对数概率张量。公式解读
代码中的KL散度公式可以展开为:
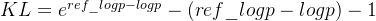
其中:
-
ref_logp 是参考模型的对数概率。
-
logp 是当前模型的对数概率。
-
这个公式实际上是基于以下数学推导:
-
原始的KL散度公式:
在这里,P(x) 是参考模型的概率,Q(x) 是当前模型的概率。 -
对数概率的表示:
-
代入对数概率:
-
简化公式: 在代码中,为了计算每个令牌的KL散度,使用了以下公式:
-
这个公式可以进一步理解为:
,其中
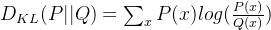
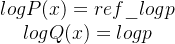
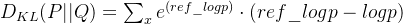
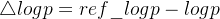
解释
-
exp(Δlogp):这是参考模型和当前模型对数概率差异的指数。它表示参考模型的概率与当前模型的概率的比值。
-
Δlogp:这是参考模型和当前模型对数概率的直接差异。
-
减去1:这个操作是为了调整公式,使其在 Δlogp=0 时(即两个模型的概率相同)结果为0。
这个公式在某些情况下用于近似KL散度,特别是在处理对数概率时。它避免了直接计算概率比值的对数,从而在数值上更加稳定。此外,它还提供了一个关于两个模型对数概率差异的直观度量。该公式是基于对数概率差异的一种近似计算方式。它在数值上更加稳定,并且能够有效地衡量两个模型之间的差异。
-
-
6.总结
DeepSeek-R1的意义在于其通过创新的训练方法和技术突破,为大型语言模型(LLMs)在推理能力、训练效率和成本控制等方面树立了新的标杆。其采用的多阶段训练策略,结合冷启动数据微调、强化学习(RL)和监督微调(SFT),不仅显著提升了模型在复杂推理任务中的表现,还解决了传统单阶段训练方法难以克服的挑战。DeepSeek-R1的训练过程证明了强化学习可以有效提升模型的推理能力,同时其创新的GRPO算法大幅降低了训练成本,使得高性能推理模型的开发更加高效和经济。此外,DeepSeek-R1还通过拒绝采样和数据飞轮机制,进一步优化了模型的通用性和适应性,使其在多种任务场景中都能表现出色。
如果你觉得这篇文章对你有帮助,不妨点个赞、关注一下,或者收藏起来,方便以后随时查阅。你的支持是我不断创作的动力,感谢你的陪伴!