1.PaddleOCR简介
PaddleOCR 是基于百度 飞桨(PaddlePaddle) 深度学习框架的开源文字识别工具套件。它提供了从 数据准备 → 文本检测 → 文本识别 → 后处理 的完整 OCR 解决方案。PaddleOCR 支持中英文以及 80+ 种语言,还可以处理竖排、弯曲、手写等复杂文本场景,应用广泛,例如票据识别、文档数字化、车牌识别、工业场景等。
PaddleOCR 的优点
-
开箱即用:官方提供了大量预训练模型,直接下载即可推理和测试,适合快速上手。
-
支持多语言:覆盖中英文、日文、韩文、阿拉伯语等 80+ 语言。
-
轻量高效:提供多种轻量级模型(如 PP-OCR 系列),在移动端和嵌入式设备上也能流畅运行。
-
模块化设计:检测、识别、方向分类器等模块可以自由组合,也支持替换为自己的模型。
-
训练与部署一体化:不仅支持从零开始训练和微调,还能轻松导出到推理引擎(如 Paddle Lite、TensorRT),方便部署到实际应用
PaddleOCR官方网站
github
官方网站
2.环境配置
默认已经安装CUDA、cudnn、conda和编译器等深度学习基础环境
2.1创建并进入conda虚拟环境
conda create -n paddleocr python=3.10conda activate paddleocr2.2安装PaddlePaddle
根据下述网站选择自己的系统和cuda版本获取指令安装
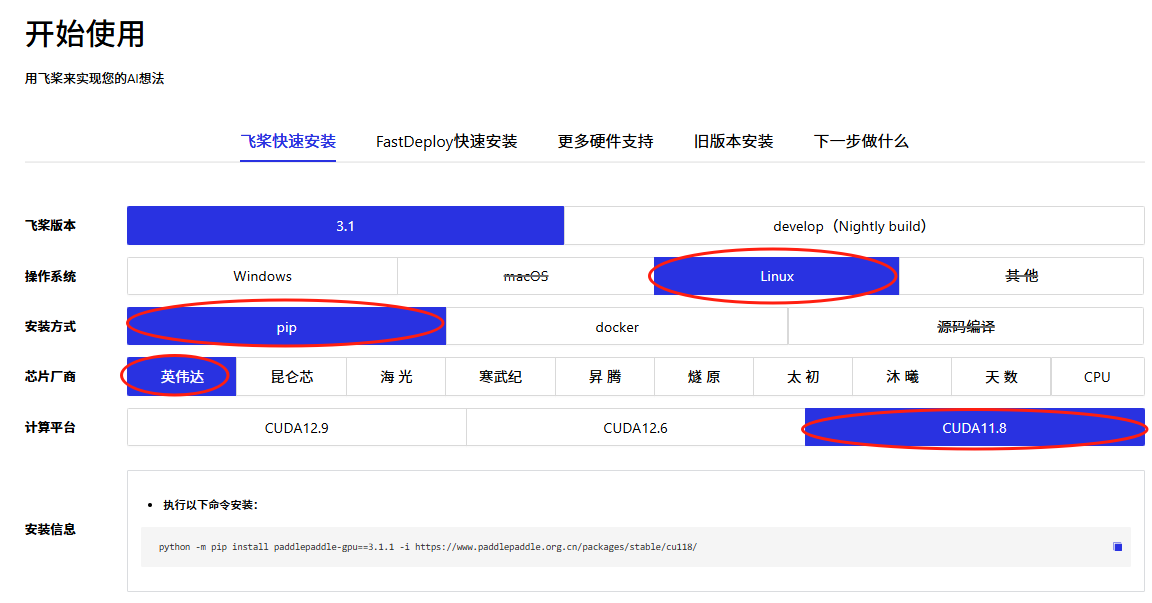
例如:你是Linux系统和CUDA11.8使用这个指令
python -m pip install paddlepaddle-gpu==3.1.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu118/2.3安装Paddleocr
pip install paddleocr3.制作自己的数据集
3.1.1获取标注工具源代码
在下方网站下载获取标注工具
https://github.com/PFCCLab/PPOCRLabel
3.1.2获取图片数据集
以下是飞桨官方社区提供数据集的网站链接:
可以搜索合适的数据集进行下载使用:
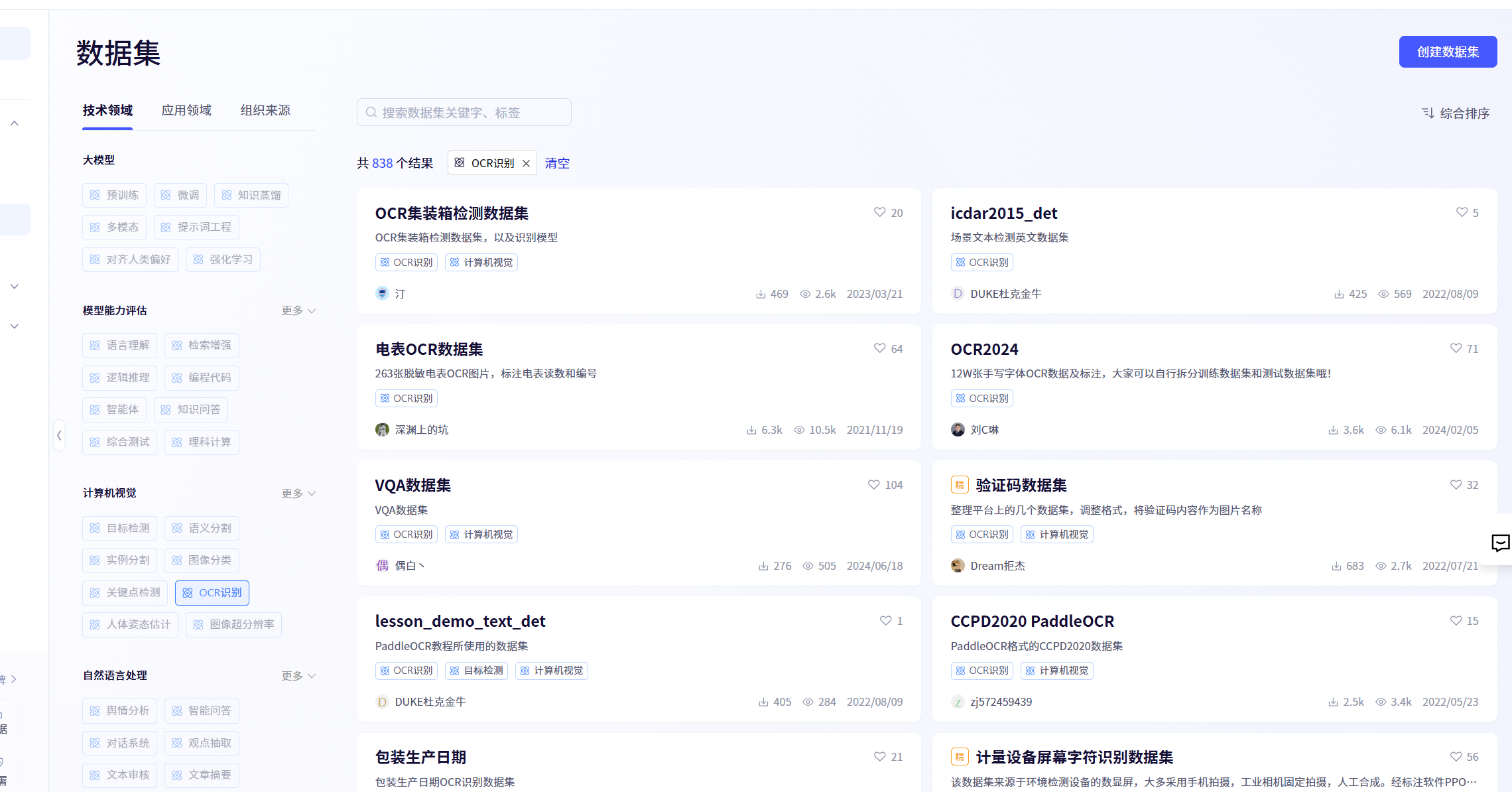
也可以利用自建的OCR数据集
3.2运行PPOCRLabel.py
下载完解压后,运行PPOCRLabel.py
CD自动到PPOCRLabel-main路径后在终端中输入下方代码,或者直接使用编译器运行
python ./PPOCRLabel.py点击左上角文件,打开目录选择需要打标签的数据集文件夹,如下图所示
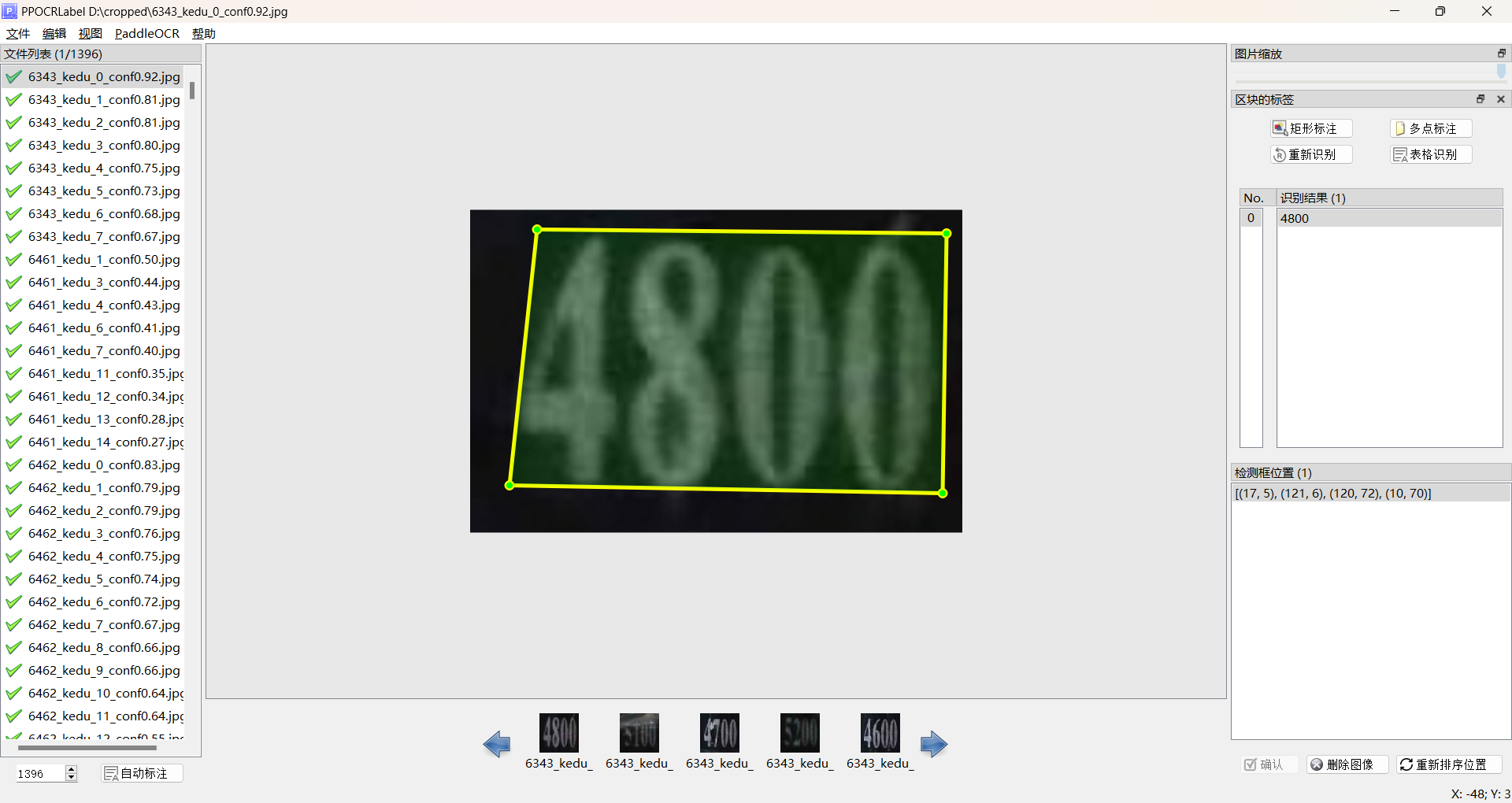
3.3自动标注
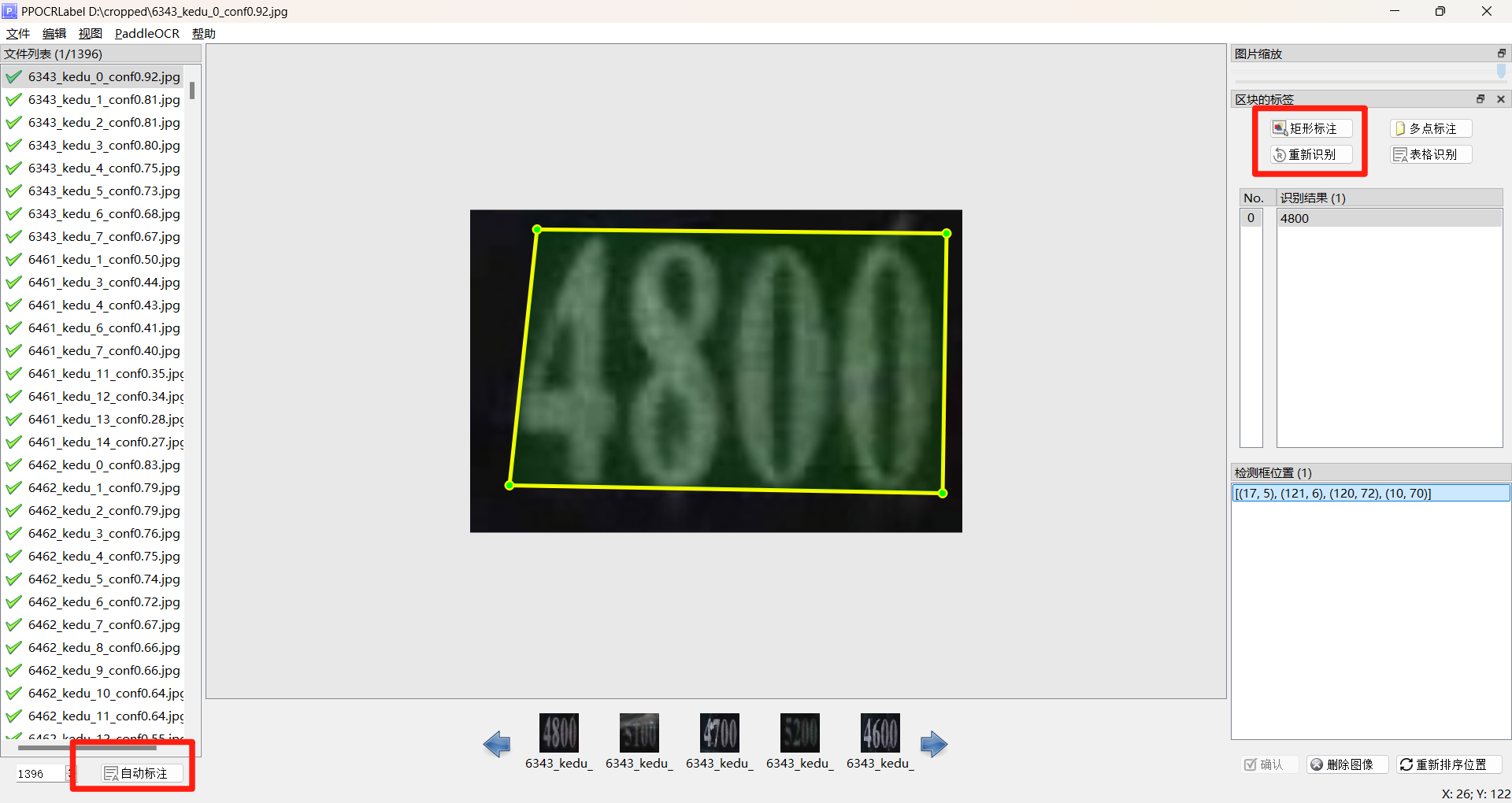
然后下方的自动标注,就会进行一波自动标注
自动标注完成后从第一张图片开始检查:
- 漏标的文字:按Q键多点进行标注,或者按W键进行矩形框标注
- 在左上角点击"文件"选项,即可看到"自动重新识别"和"自动保存"功能。
- 标签错误的文字:点击对应方框,在右侧修改关键词(编辑→更改box关键词信息)
- 删除无用信息后,按D键切换至下一张
确认无误的标注点击下方确认按钮
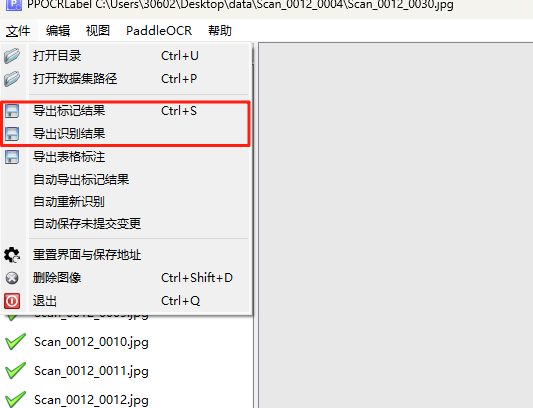
3.4导出标注结果
完成标注后
- 点击文件→导出标记结果
- 点击文件→导出识别结果
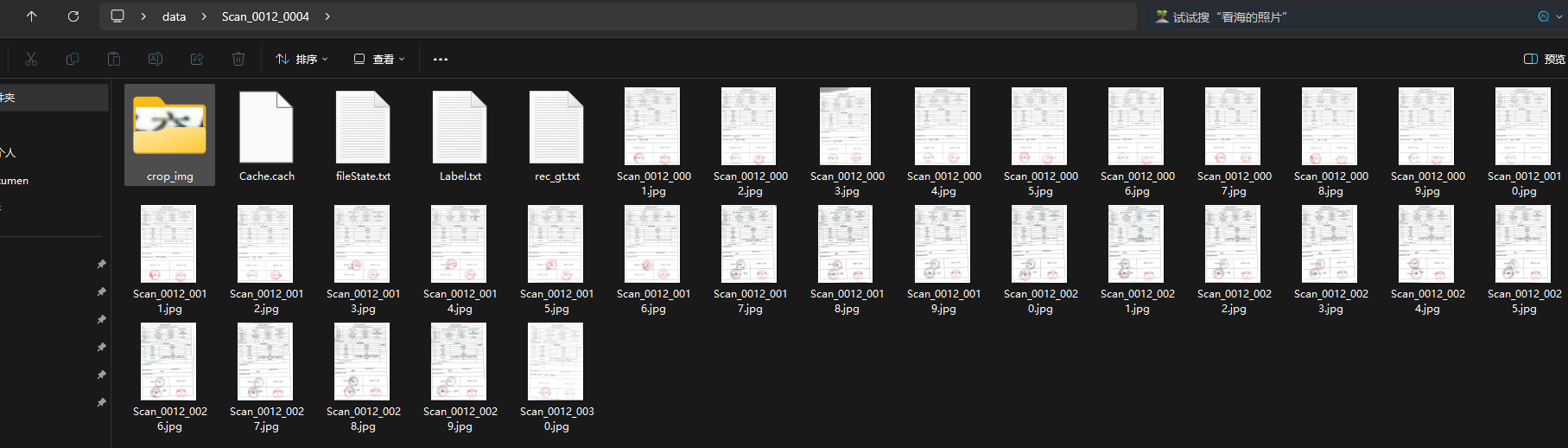
- 系统生成四个文件:
- fileState:记录图片标注状态
- Label:文字检测模型训练标签
- rec_gt:文字识别模型训练标签
- crop_img:文字识别模型的训练图片集
导出结果如例
4.准备数据集和权重
4.1划分数据集
打开终端,CD进入PPOCRLabel文件夹后,执行以下命令划分数据集,将标注数据划分为训练集、验证集和测试集。
python gen_ocr_train_val_test.py --trainValTestRatio 6:2:2 --datasetRootPath ./data/Scan_0012_0004参数解释:
--trainValTestRatio 6:2:2 #训练集、验证集和测试集的比例
--datasetRootPath #数据集路径
运行后会生成一个train_data的文件夹
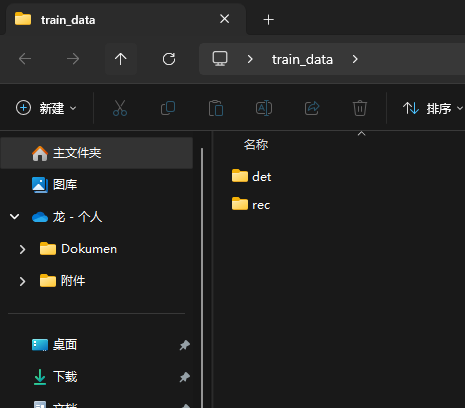
训练完成后,train_data文件夹将生成以下文件:
- det/ :存放文字检测训练数据
- rec/ :存放文字识别训练数据
此时文字检测与识别数据集已准备就绪。
4.2下载预训练权重
微调模型官方说明文档:
(1)下载文本检测模块的训练模型
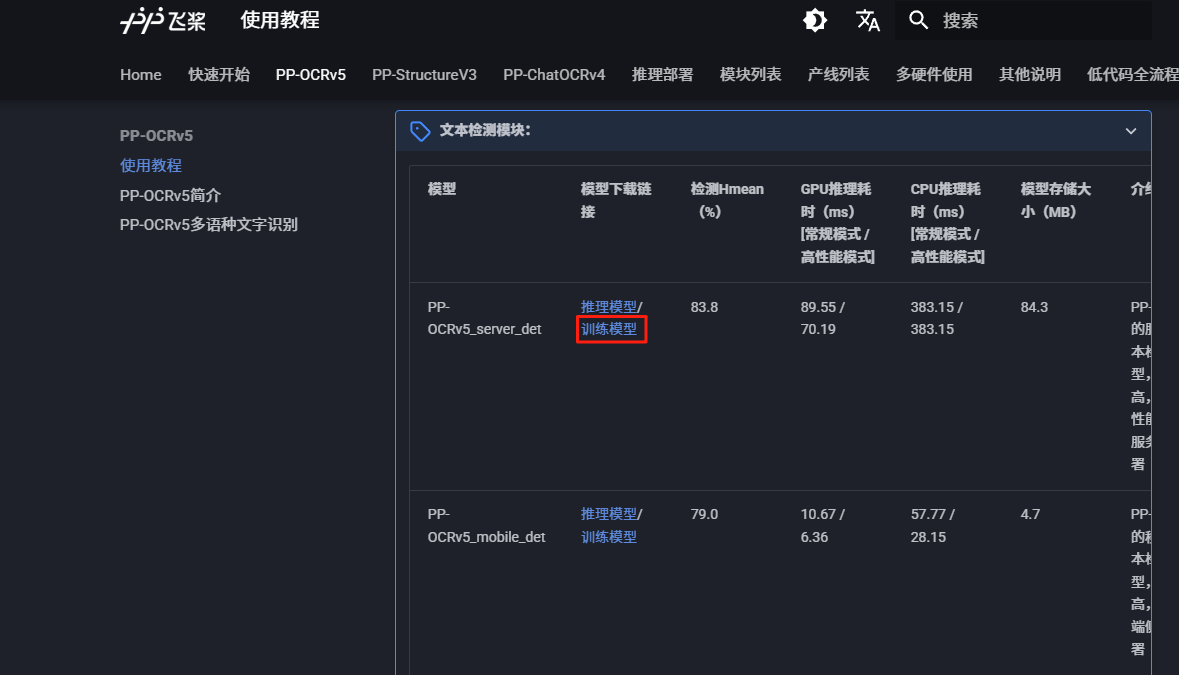
或者利用wget下载:
# 下载 PP-OCRv5_server_det 预训练模型
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/official_pretrained_model/PP-OCRv5_server_det_pretrained.pdparams(2)下载文本识别模块的训练模型
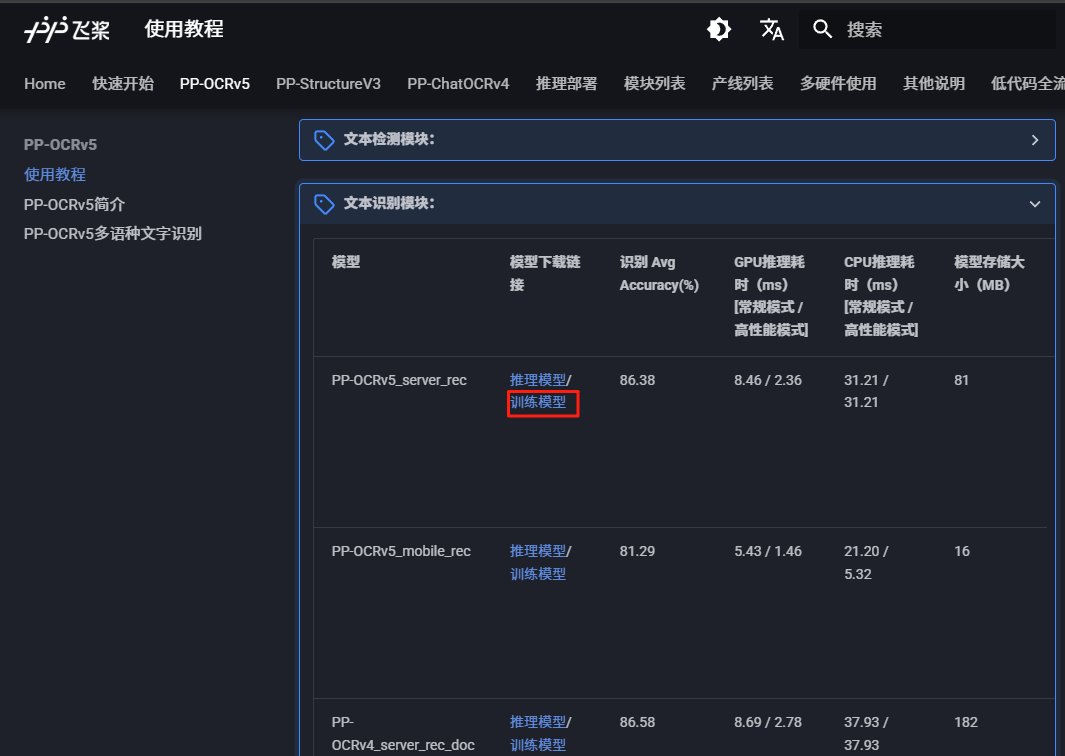
或者利用wget下载:
# 下载 PP-OCRv5_server_rec 预训练模型
wget https://paddle-model-ecology.bj.bcebos.com/paddlex/official_pretrained_model/PP-OCRv5_server_rec_pretrained.pdparams 建议创建一个名为model的文件夹,并将下载的两个模型参数文件存放其中。
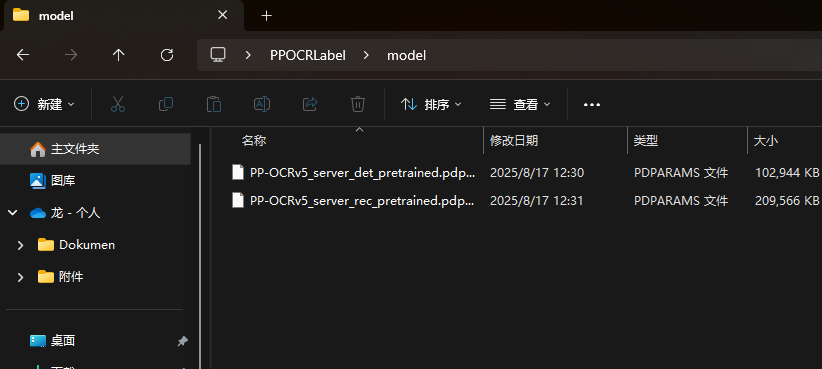
5.训练
5.0下载训练paddlerocr代码!
将代码从该GitHub仓库克隆到本地,解压后进入项目目录
https://github.com/PaddlePaddle/PaddleOCR
5.1训练文本检测模型
先再安装一些库
pip install albumentations scikit-image lmdb rapidfuzz 文本检测模型训练命令如下:
#单卡训练 (默认训练方式)
python3 tools/train.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \
-o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams \
Train.dataset.data_dir=./train_data/det \
Train.dataset.label_file_list='[./train_data/det/train.txt]' \
Eval.dataset.data_dir=./train_data/det \
Eval.dataset.label_file_list='[./train_data/det/val.txt]'
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py \
-c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \
-o Global.pretrained_model=./PP-OCRv5_server_det_pretrained.pdparams \
Train.dataset.data_dir=./ocr_det_dataset_examples \
Train.dataset.label_file_list='[./ocr_det_dataset_examples/train.txt]' \
Eval.dataset.data_dir=./ocr_det_dataset_examples \
Eval.dataset.label_file_list='[./ocr_det_dataset_examples/val.txt]'参数解释:
# -配置文件路径,默认下载源代码时候就有,不用修改。
-c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml
# 预训练权重文件路径,就是4.2小节下载的文件,我们放在model文件夹下了,所以是:
-o Global.pretrained_model=./model/PP-OCRv5_server_det_pretrained.pdparams
#训练数据集路径,就是4.1小节整理后的数据,我们放在train_data文件夹下了
Train.dataset.data_dir=./train_data/det
#训练数据集txt文件路径
Train.dataset.label_file_list='[./train_data/det/train.txt]'
#验证数据集路径,就是4.1小节整理后的数据,我们放在train_data文件夹下了
Eval.dataset.data_dir=./train_data/det
#训练数据集txt文件路径
Eval.dataset.label_file_list='[./train_data/det/val.txt]'
想修改更多参数可以打开configs/det/PP-OCRv5/PP-OCRv5_server_det.yml 文件进行修改!!
要是报错就把所有地址都换成绝对路径
训练过程:
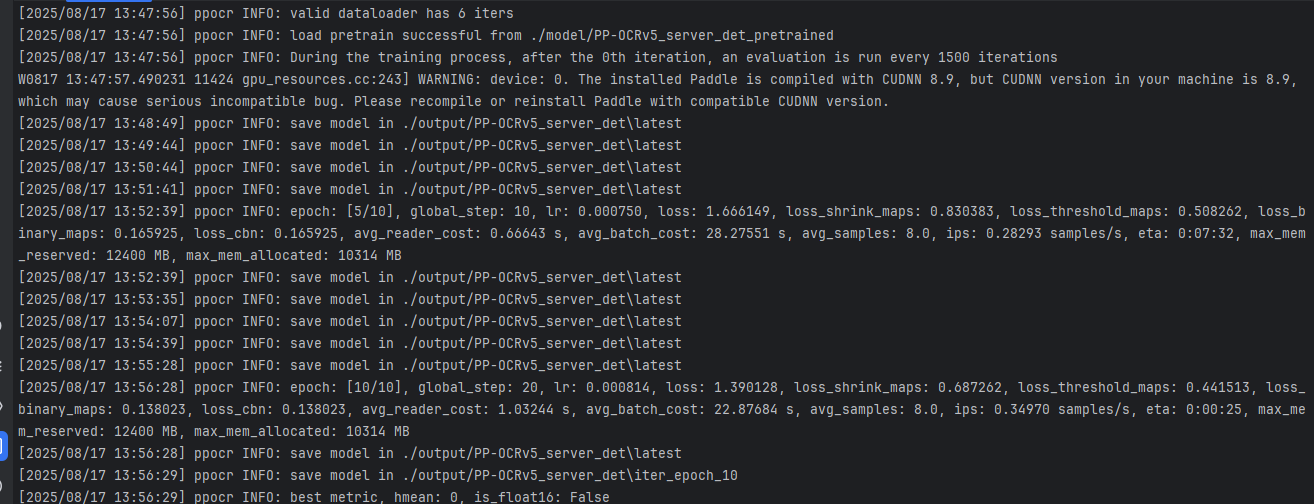
训练完成后保存的文件:
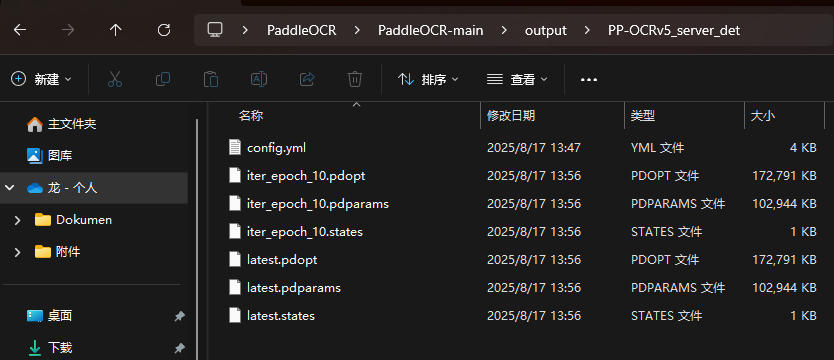
5.2训练文本识别模型
文本识别模型训练命令:
#单卡训练 (默认训练方式)
python3 tools/train.py -c configs/rec/PP-OCRv5/PP-OCRv5_server_rec.yml \
-o Global.pretrained_model=./model/PP-OCRv5_server_rec_pretrained.pdparams \
Train.dataset.data_dir=./train_data/rec \
Train.dataset.label_file_list='[./train_data/rec/train.txt]' \
Eval.dataset.data_dir=./train_data/rec \
Eval.dataset.label_file_list='[./train_data/rec/val.txt]'
#多卡训练,通过--gpus参数指定卡号
python3 -m paddle.distributed.launch --gpus '0,1,2,3' tools/train.py -c configs/rec/PP-OCRv5/PP-OCRv5_server_rec.yml \
-o Global.pretrained_model=./PP-OCRv5_server_rec_pretrained.pdparams
单行命令
python tools/train.py -c configs/rec/PP-OCRv5/PP-OCRv5_server_rec.yml -o Global.pretrained_model=./model/PP-OCRv5_server_rec_pretrained.pdparams Train.dataset.data_dir=./train_data/rec Train.dataset.label_file_list=["./train_data/rec/train.txt"] Eval.dataset.data_dir=./train_data/rec Eval.dataset.label_file_list=["./train_data/rec/val.txt"]参数解释和5.1小节是一样的
记得,修改更多参数到配置文件下PP-OCRv5_server_rec.yml进行修改:如epoch、学习率等等
6.模型评估
6.1评估文本检测模型
可以评估已经训练好的权重,如,output/PP-OCRv5_server_det/best_accuracy.pdprams,使用如下命令进行评估:
# 注意将pretrained_model的路径设置为本地路径。若使用自行训练保存的模型,请注意修改路径和文件名为{path/to/weights}/{model_name}。
# demo 测试集评估
python3 tools/eval.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml \
-o Global.pretrained_model=output/PP-OCRv5_server_det/best_accuracy.pdparams \
Eval.dataset.data_dir=./ocr_det_dataset_examples \
Eval.dataset.label_file_list='[./ocr_det_dataset_examples/val.txt]'模型导出:
python3 tools/export_model.py -c configs/det/PP-OCRv5/PP-OCRv5_server_det.yml -o \
Global.pretrained_model=output/PP-OCRv5_server_det/best_accuracy.pdparams \
Global.save_inference_dir="./PP-OCRv5_server_det_infer/"导出模型后,静态图模型会存放于当前目录的./PP-OCRv5_server_det_infer/中,在该目录下,您将看到如下文件:
./PP-OCRv5_server_det_infer/
├── inference.json
├── inference.pdiparams
├── inference.yml至此,二次开发完成,该静态图模型可以直接集成到 PaddleOCR 的 API 中。
6.2评估文本识别模型
您可以评估已经训练好的权重,如,output/xxx/xxx.pdparams,使用如下命令进行评估:
#注意将pretrained_model的路径设置为本地路径。若使用自行训练保存的模型,请注意修改路径和文件名为{path/to/weights}/{model_name}。
#demo 测试集评估
python3 tools/eval.py -c configs/rec/PP-OCRv5/PP-OCRv5_server_rec.yml -o \
Global.pretrained_model=output/xxx/xxx.pdparams模型导出:
python3 tools/export_model.py -c configs/rec/PP-OCRv5/PP-OCRv5_server_rec.yml -o \
Global.pretrained_model=output/xxx/xxx.pdparams \
Global.save_inference_dir="./PP-OCRv5_server_rec_infer/"导出模型后,静态图模型会存放于当前目录的./PP-OCRv5_server_rec_infer/中,在该目录下,您将看到如下文件:
./PP-OCRv5_server_rec_infer/
├── inference.json
├── inference.pdiparams
├── inference.yml至此,二次开发完成,该静态图模型可以直接集成到 PaddleOCR 的 API 中。
下一篇更新paddleocr的部署工作,可以关注