
- 论文题目:Point Transformer V3: Simpler, Faster, Stronger
- 发布期刊:CVPR
- 通讯地址:1香港大学 2上海人工智能实验室 3香港中文大学(深圳) 4北京大学 5麻省理工学院
- 代码地址: https://github.com/Pointcept/PointTransformerV3
介绍
这篇论文的主要内容是介绍Point Transformer V3 (PTv3),一个用于3D点云处理的模型,目标是解决精度与效率之间的权衡问题。PTv3在设计上强调简化和提升效率,优先考虑模型的扩展能力,而不是通过复杂的机制来提升局部的精度。论文的贡献主要体现在以下几个方面:

- 更强的性能:PTv3在多个室内和室外的3D感知任务上取得了最新的最优性能。
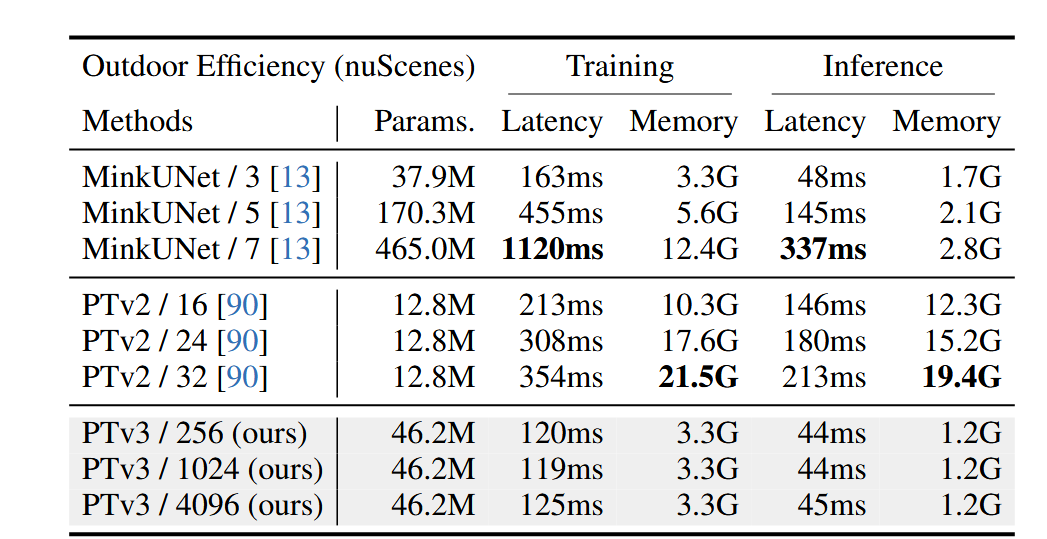
- 更广的感受野:通过简化设计,PTv3将感受野从16个点扩展到1024个点,同时保持了高效性。
- 更快的速度:PTv3在处理速度上有显著提升,比前代模型快3倍,并且在推理过程中减少了内存消耗。
- 低内存消耗:与PTv2相比,PTv3的内存消耗减少了10倍,使其更适合资源受限的环境。
核心思想
Point Transformer V3 (PTv3) 的核心思想是通过简化设计和提升模型的扩展能力,解决3D点云处理中精度与效率之间的权衡问题。它提出模型性能更大程度上取决于模型的规模扩展(scaling),而非复杂的设计细节。具体来说,PTv3 的核心思想可以归纳为以下几个方面:
优先考虑效率与扩展性
PTv3 优先简化模型中的复杂机制,以实现更好的扩展性。论文提出,与其在局部设计上过度追求精度,不如通过减少计算复杂度和内存消耗来扩大感受野和模型的规模。这种方法允许模型能够处理更大的点云数据,达到更好的全局性能。
舍弃复杂机制,采用高效的替代方案
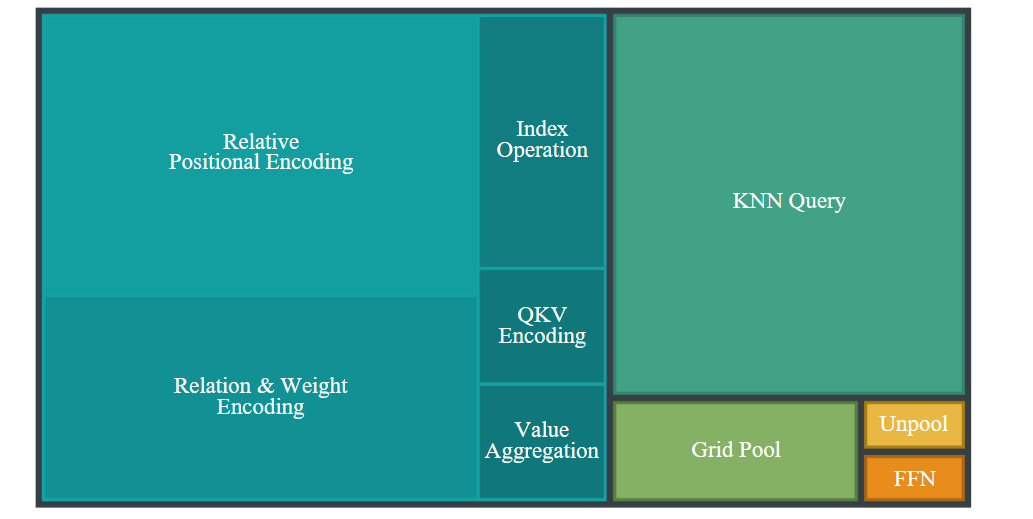
PTv3 去掉了在前代模型中占用大量计算时间和内存的复杂机制,比如:
- KNN 近邻搜索:占用大量计算时间,PTv3 使用了序列化邻域映射替代了精确的近邻搜索。
- 相对位置编码:这在以前的模型中占用了大量计算资源,PTv3 则采用了更简单的稀疏卷积预处理层来替代。
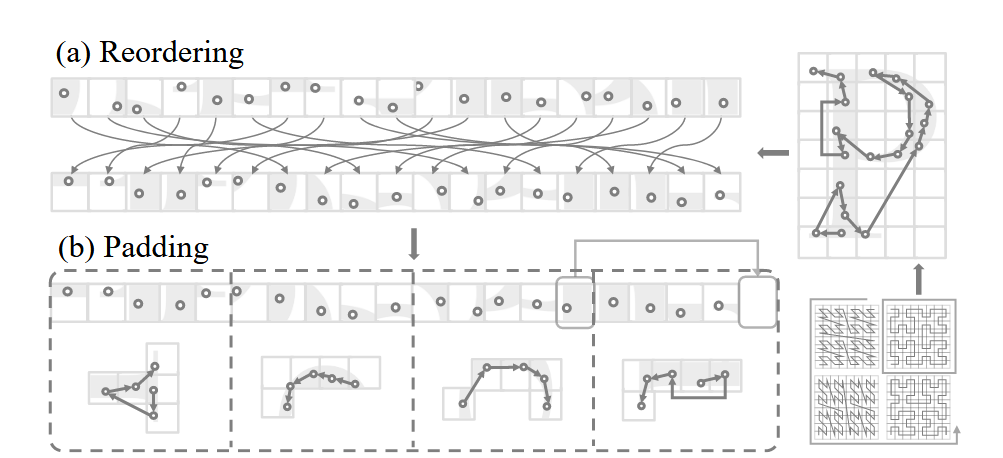
图 补丁分组。 (a) 根据从特定序列化模式导出的顺序对点云进行重新排序。 (b) 通过借用相邻补丁的点来填充点云序列,以确保它可以被指定的补丁大小整除。
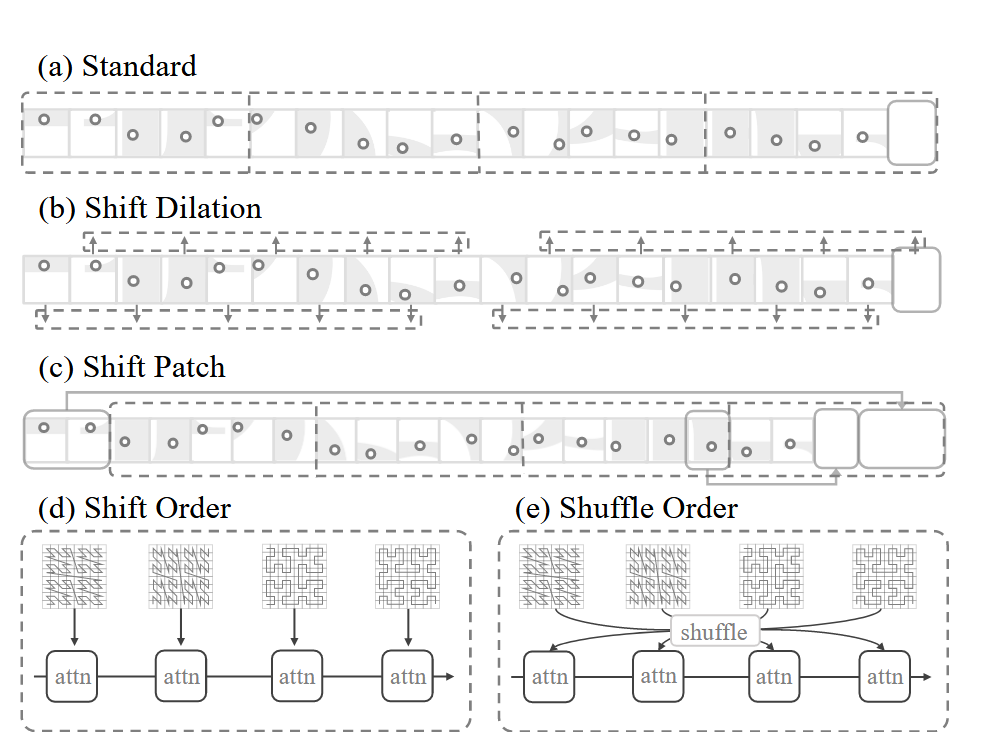
图 补丁交互。 (a) 标准斑块分组,具有规则的、非移位的排列; (b) 平移扩张,其中点按规则间隔分组,产生扩张效果; © Shift Patch,采用类似于移位窗口方法的移位机制; (d) Shift Order,其中不同的序列化模式被循环分配给连续的注意力层; (d) 洗牌顺序,序列化模式的序列在输入到注意层之前被随机化。
序列化点云处理
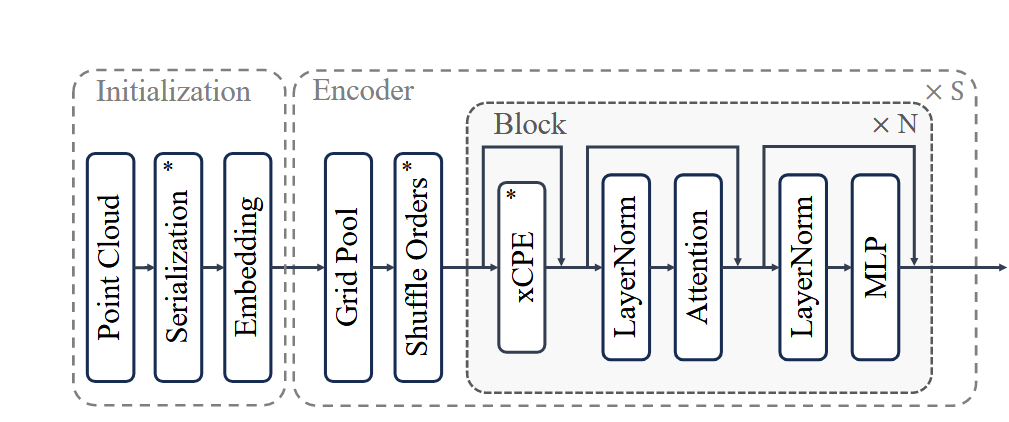
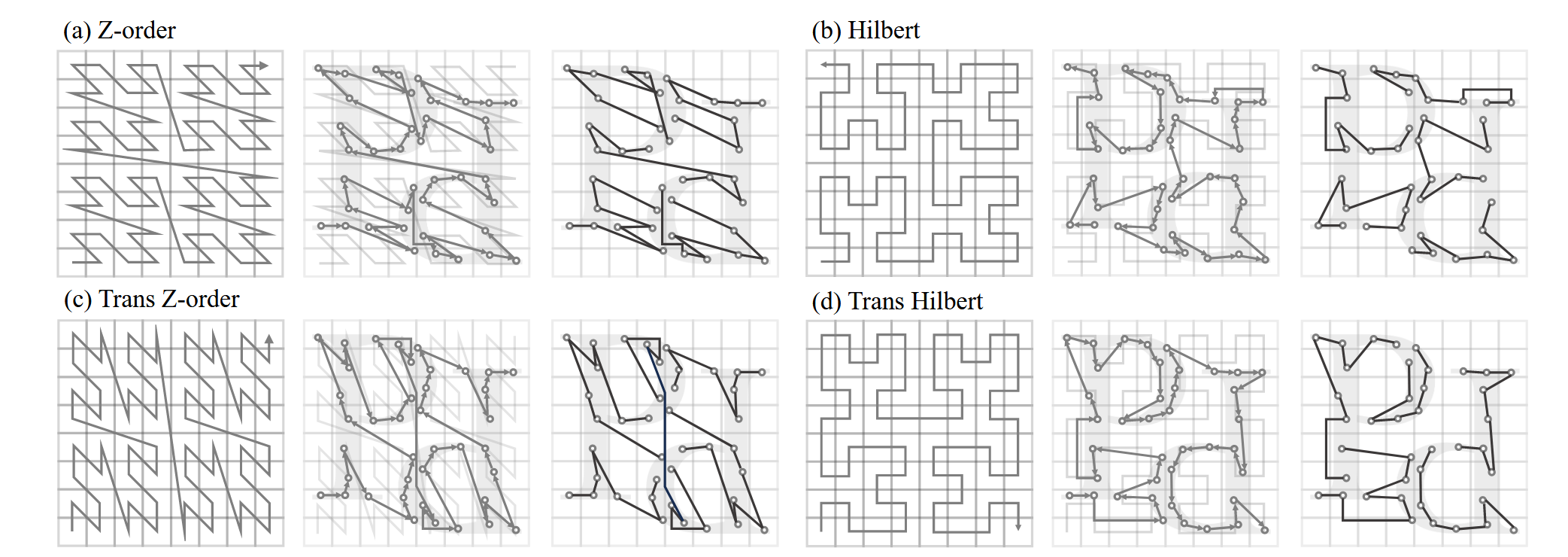
PTv3 引入了点云序列化的概念,将原本无序的3D点云数据转换为有序的结构。通过利用空间填充曲线(如 Z-order 和 Hilbert 曲线),它将点云数据转换为一维序列,进而优化处理过程。这种方法有效地保留了空间邻近性,同时大幅提高了处理效率。
图 补丁交互。 (a) 标准斑块分组,具有规则的、非移位的排列; (b) 平移扩张,其中点按规则间隔分组,产生扩张效果; © Shift Patch,采用类似于移位窗口方法的移位机制; (d) Shift Order,其中不同的序列化模式被循环分配给连续的注意力层; (d) 洗牌顺序,序列化模式的序列在输入到注意层之前被随机化。
扩大感受野
PTv3 强调模型在大规模数据下的表现,成功将感受野从16个点扩展到1024个点,这极大地提升了模型的全局感知能力。而通过简化设计,它不仅能够扩大感知范围,还能保持较高的效率。
性能与效率并重
PTv3 在保持高效性的同时,通过扩展感受野和采用更高效的注意力机制,取得了在多个3D感知任务上的最佳性能。相比前代模型,PTv3 的推理速度提高了约3倍,内存消耗减少了10倍,这使得它能够在实际应用中实现更快的处理和更广泛的部署。
核心代码实现讲解
Point Transformer V3 的核心思想是通过简化3D点云处理中的复杂机制,使用序列化的方式来增强模型的效率和扩展性。这一设计基于点云数据的序列化处理,同时采用稀疏卷积和注意力机制来有效提升模型的处理速度、内存效率以及感知能力。以下是核心思想结合代码的讲解:
序列化点云处理
Point Transformer V3 通过将点云数据序列化(serialization)转变成有序的结构来处理点云。传统的点云数据无序,无法直接应用卷积等操作,而通过将点云数据按照特定的空间曲线(如Z-order或Hilbert曲线)排序,可以将其转化为有序结构,提升处理效率。
代码实现:
- 在
Point类中的serialization方法中,通过计算点的grid_coord(网格坐标),并基于输入参数order(如 z-order 或 Hilbert)生成点云的serialized_code、serialized_order和serialized_inverse,实现点云的序列化处理。
def serialization(self, order="z", depth=None, shuffle_orders=False):
# 根据点云的坐标和批次信息进行序列化编码
code = [
encode(self.grid_coord, self.batch, depth, order=order_) for order_ in order
]
# 序列化顺序和反序列化
self["serialized_code"] = code
self["serialized_order"] = order
self["serialized_inverse"] = inverse
稀疏卷积和特征稀疏化
由于点云数据的稀疏性,Point Transformer V3 使用了稀疏卷积(SparseConv),该方法允许仅对有效的点进行卷积运算,而不是对整个三维空间进行操作。这样可以大幅降低计算复杂度,提高内存效率。
代码实现:
Point类中的sparsify方法负责将点云特征和稀疏卷积张量(SparseConvTensor)关联起来。稀疏卷积操作通过生成sparse_shape和sparse_conv_feat完成。
def sparsify(self, pad=96):
sparse_conv_feat = spconv.SparseConvTensor(
features=self.feat,
indices=torch.cat([self.batch.unsqueeze(-1).int(), self.grid_coord.int()], dim=1).contiguous(),
spatial_shape=sparse_shape,
batch_size=self.batch[-1].tolist() + 1,
)
self["sparse_conv_feat"] = sparse_conv_feat
自注意力机制
Point Transformer V3 使用了序列化注意力机制(SerializedAttention)来处理点云中的局部和全局关系。该注意力机制通过将点云数据划分为多个片段(patch),对每个片段执行注意力操作,同时利用序列化的顺序来实现快速的局部关系建模。
代码实现:
- 在
SerializedAttention类中,模型根据输入点云的特征计算qkv三个矩阵(query、key、value),并通过点的相对位置关系来进行加权。 - 如果启用了
flash_attn,则可以进一步加速注意力操作。
def forward(self, point):
qkv = self.qkv(point.feat)[order]
if not self.enable_flash:
q, k, v = qkv.reshape(-1, K, 3, H, C // H).permute(2, 0, 3, 1, 4).unbind(dim=0)
attn = self.softmax(attn)
feat = (attn @ v).transpose(1, 2).reshape(-1, C)
else:
feat = flash_attn.flash_attn_varlen_qkvpacked_func(...)
return point
模块化与层次化的设计
Point Transformer V3 通过模块化的设计(如PointModule和PointSequential),使模型可以灵活地构建多层次的编码器和解码器结构,逐步提取不同尺度下的点云特征。这一设计让模型能够在复杂的三维场景中进行多级处理,并且可以很好地适应不同任务。
代码实现:
- 通过
PointSequential类实现模块的序列化执行,并支持自动加载不同的模块(如稀疏卷积、注意力机制等)。 - 在
PointTransformerV3类中,定义了编码器和解码器的结构,编码器主要用于提取高层次特征,解码器则将这些特征逐步还原到原始空间中。
class PointTransformerV3(PointModule):
def __init__(self, in_channels=6, ...):
self.enc = PointSequential()
for s in range(self.num_stages):
enc = PointSequential()
if s > 0:
enc.add(SerializedPooling(...))
for i in range(enc_depths[s]):
enc.add(Block(...))
self.enc.add(module=enc, name=f"enc{
s}")
如何改进PointNet++
将 Point Transformer V3 (PTv3) 的核心思想应用到 PointNet++ 中,可以帮助改进后者的局部特征学习、全局建模能力以及处理效率。以下是几种改进方向以及实现步骤,详细讲述如何将 PTv3 的技术融入到 PointNet++ 中。
改进局部特征学习:引入自注意力机制
PointNet++ 在特征提取时,使用了局部的特征聚合方法,比如基于点的邻域进行特征学习。你可以通过引入 PTv3 的自注意力机制,替换 PointNet++ 中的简单特征聚合操作,从而改进局部特征的学习能力。
实现步骤:
- 在每个局部区域中,使用 PTv3 的 Serialized Attention 替换 PointNet++ 中的 MLP 或简单卷积操作。
- 序列化每个局部区域中的点(如基于 Hilbert 曲线),然后在这些有序点中计算 Query、Key、Value,执行局部的注意力机制,以捕捉点之间的关系。
- 对每个区域生成的特征进行注意力加权,并使用投影层重新组合特征。
示例代码片段:
# 局部区域内特征提取替换为自注意力
class LocalAttentionFeatureExtractor(nn.Module):
def __init__(self, in_channels, out_channels, patch_size, num_heads):
super().__init__()
self.attn = SerializedAttention(
channels=in_channels,
num_heads=num_heads,
patch_size=patch_size,
qkv_bias=True
)
def forward(self, point_cloud):
point_cloud = self.attn(point_cloud)
return point_cloud
解释:
- 这个
LocalAttentionFeatureExtractor类使用 PTv3 的SerializedAttention模块来提取局部区域内的特征,相比 PointNet++ 原有的 MLP 操作,能够更好地捕捉点的局部关系。
扩展感受野:扩大感受野和全局特征聚合
PointNet++ 的局部特征提取机制(通过球形区域搜索或 KNN 选择邻域)在全局建模时可能不够充分。通过引入 PTv3 的 全局自注意力机制,可以实现更大的感受野,让模型更好地捕捉全局信息。
实现步骤:
- 在多层次特征提取的过程中,使用 PTv3 的 Multi-scale Attention,结合 PointNet++ 的多层级结构,将不同尺度的局部区域特征合并,并对整个点云进行全局自注意力计算。
- 通过扩大感受野,让模型能够学习到全局的上下文信息,而不是仅限于局部的邻域。
示例代码片段:
class GlobalFeatureExtractor(nn.Module):
def __init__(self, in_channels, num_heads, patch_size):
super().__init__()
self.global_attention = SerializedAttention(
channels=in_channels,
num_heads=num_heads,
patch_size=patch_size,
enable_flash=True
)
def forward(self, point_cloud):
point_cloud = self.global_attention(point_cloud)
return point_cloud
解释:
- 通过
GlobalFeatureExtractor类,你可以将全局自注意力机制应用于整个点云,扩展模型的感受野,并且通过 Flash Attention 提升计算效率。
提升效率:使用稀疏卷积(Sparse Convolution)和序列化处理
PointNet++ 在点云处理时,通常会用全局的 MLP 或基于 KNN 的操作,这些操作可能在大规模点云上效率不高。通过引入 PTv3 的 稀疏卷积(Sparse Convolution) 和 序列化处理,可以显著提升计算效率,减少内存消耗。
实现步骤:
- 在 PointNet++ 的每一层采样阶段,使用 PTv3 的
sparsify方法将点云转化为稀疏卷积张量,减少冗余计算。 - 使用 PTv3 的序列化方法,将点云数据通过空间填充曲线进行排序,并应用稀疏卷积和注意力机制以优化计算。
示例代码片段:
class SparseFeatureExtractor(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.sparse_conv = spconv.SparseConv3d(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=3,
stride=1,
padding=1
)
def forward(self, point_cloud):
point_cloud.sparsify()
point_cloud = self.sparse_conv(point_cloud.sparse_conv_feat)
return point_cloud
解释:
- 使用
SparseFeatureExtractor类将点云数据转换为稀疏卷积形式,并进行高效的卷积操作。相比 PointNet++ 的全连接操作,稀疏卷积在大规模点云上具有更好的效率。
结合多尺度特征:融合局部和全局特征
通过结合 局部自注意力 和 全局自注意力,可以让模型同时学习到局部特征的细节和全局的上下文信息,从而提升对复杂几何结构的感知能力。
实现步骤:
- 在 PointNet++ 的多层特征提取模块中,使用 PTv3 的局部注意力模块提取邻域内特征,再使用全局自注意力模块获取全局信息。
- 将多尺度的局部特征和全局特征融合起来,并在模型的后续层进行进一步的处理。
示例代码片段:
class MultiScaleFeatureFusion(nn.Module):
def __init__(self, local_in_channels, global_in_channels, out_channels):
super().__init__()
self.local_attention = LocalAttentionFeatureExtractor(local_in_channels, out_channels, patch_size=128, num_heads=4)
self.global_attention = GlobalFeatureExtractor(global_in_channels, num_heads=8, patch_size=1024)
def forward(self, local_point_cloud, global_point_cloud):
local_features = self.local_attention(local_point_cloud)
global_features = self.global_attention(global_point_cloud)
fused_features = torch.cat([local_features.feat, global_features.feat], dim=1)
return fused_features
解释:
MultiScaleFeatureFusion类实现了局部特征和全局特征的融合。通过将局部特征和全局特征拼接后,模型能够更好地理解点云的全貌以及细节信息。