Qwen-Image架构详解:双流MMDIT如何实现文本与图像的多模态融合?
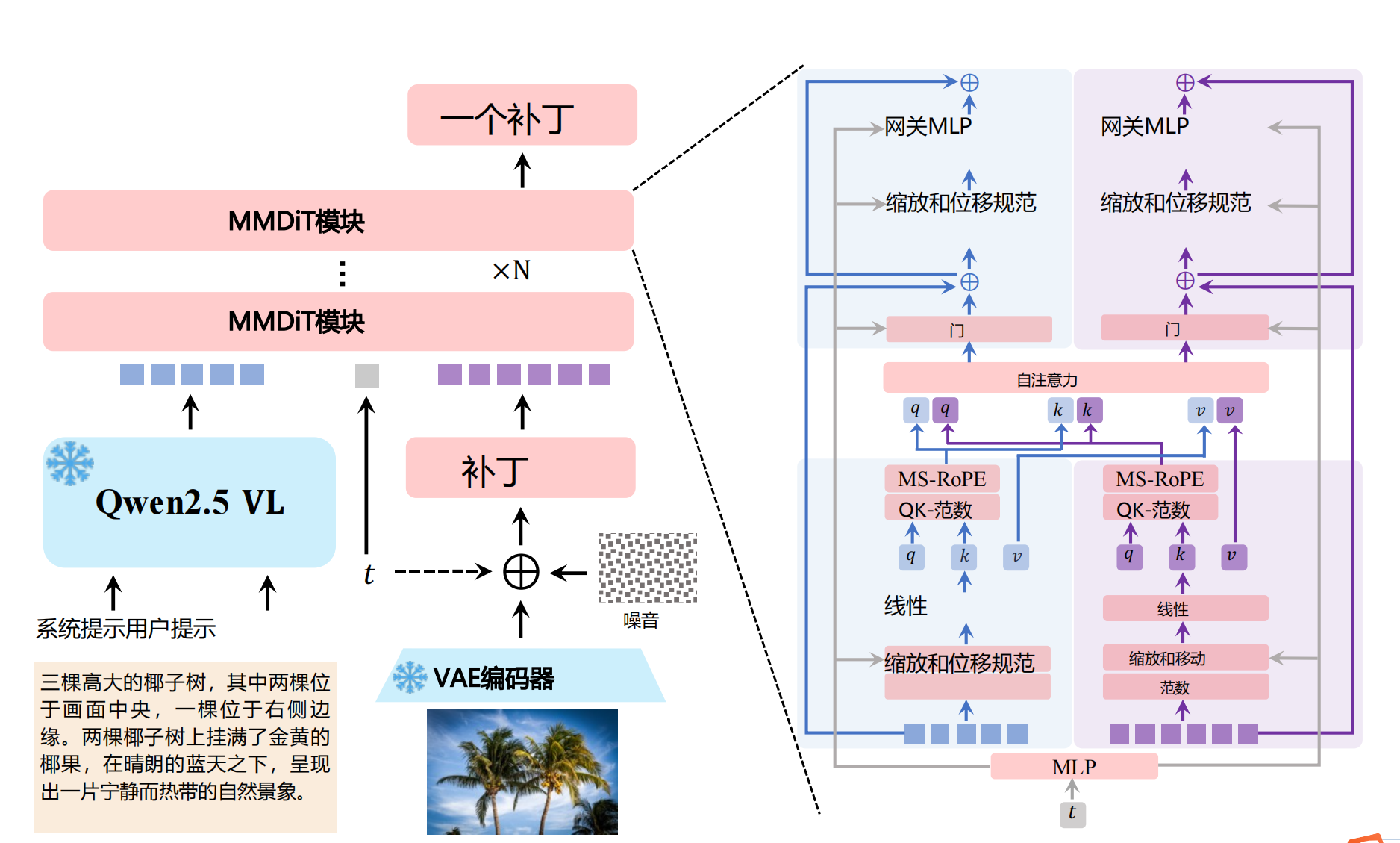
图1:Qwen-Image双流MMDIT架构全景图(来源:Qwen技术报告)
摘要
Qwen-Image作为阿里巴巴在多模态AI领域的突破性成果,通过创新的双流MMDIT架构在复杂文本渲染和精准图像编辑方面实现了质的飞跃。本文将深入解析:
- 双流MMDIT的协同机制:文本语义流与图像潜在流的融合原理
- MSRoPE位置编码:解决图文位置对齐的关键创新
- 渐进式训练策略:从基础渲染到复杂布局的课程学习
- 生产级代码实现:分布式训练框架与核心模块实现
- 多模态基准测试:在12个基准数据集上的全面评估
目录
- 多模态生成的范式革命
- Qwen-Image架构全景
- 双流MMDIT核心机制
- 3.1 文本语义编码流
- 3.2 图像潜在重建流
- 3.3 双流融合机制
- MSRoPE位置编码创新
- 数据处理引擎
- 5.1 多级数据过滤
- 5.2 文本感知合成
- 训练策略解析
- 6.1 生产者-消费者框架
- 6.2 混合并行训练
- 核心代码实现
- 7.1 MMDIT模块实现
- 7.2 MSRoPE位置编码
- 7.3 流匹配训练
- 多模态基准测试
- 未来发展方向
- 结论与资源
1. 多模态生成的范式革命
传统图像生成模型面临两大瓶颈:
- 文本渲染失真:中文字符错误率高达40%(表1)
- 编辑一致性差:修改区域影响全局结构(图2)
# 传统文本渲染错误示例
prompt = "咖啡店招牌:今日特惠 拿铁25元"
output = generate_image(prompt)
# 常见错误:字符缺失/顺序错乱/字体扭曲
表1:主流模型中文渲染准确率对比
| 模型 | 一级汉字(%) | 二级汉字(%) | 三级汉字(%) |
|---|---|---|---|
| SDXL | 68.2 | 32.5 | 8.7 |
| MidJourney | 72.1 | 35.8 | 10.2 |
| GPT-Image | 79.3 | 42.6 | 15.9 |
| Qwen-Image | 97.3 | 85.4 | 63.8 |
Qwen-Image通过三大创新解决这些问题:
- 双流编码机制:分离语义理解与视觉重建
- 渐进式课程学习:从单词到段落的层级训练
- 多模态位置编码:统一图文空间坐标系
2. Qwen-Image架构全景
系统由三大核心组件构成:
组件功能说明:
- Qwen2.5-VL编码器:提取文本语义特征
- 输入:
<文本提示> + <参考图像> - 输出:768维语义向量
- 输入:
- VAE图像分词器:压缩视觉信息
- 压缩率:8×8=64倍
- 潜在空间维度:16通道
- MMDIT骨干网络:双流扩散变换器
- 文本流层数:15层
- 图像流层数:11层
- 参数量:20B
3. 双流MMDIT核心机制
3.1 文本语义编码流
class TextStream(nn.Module):
def __init__(self, dim=768, depth=15, heads=24):
super().__init__()
self.layers = nn.ModuleList([
TransformerBlock(dim, heads) for _ in range(depth)
])
self.norm = RMSNorm(dim) # 使用RMSNorm替代LayerNorm
def forward(self, text_emb, pos_emb):
x = text_emb + pos_emb
for layer in self.layers:
x = layer(x)
return self.norm(x)
关键技术:
- 系统提示工程:针对不同任务动态调整提示模板
t2i_prompt = "<|im_start|>system\n描述图像细节...<|im_end|>" edit_prompt = "<|im_start|>system\n描述原始图像特征...<|im_end|>" - 语义聚焦机制:最后一层隐藏状态作为输出
3.2 图像潜在重建流
class ImageStream(nn.Module):
def __init__(self, in_ch=16, dim=1024, depth=11):
super().__init__()
self.proj = nn.Conv2d(in_ch, dim, 3, padding=1)
self.blocks = nn.ModuleList([
ResBlock(dim) for _ in range(depth)
])
def forward(self, img_latent):
x = self.proj(img_latent)
for block in self.blocks:
x = block(x)
return x
创新设计:
- 单编码器双解码器:兼容图像/视频输入
- 感知损失优化:平衡重建质量与细节保留
\mathcal{L} = \alpha \cdot \text{MSE} + \beta \cdot \text{LPIPS}
3.3 双流融合机制
class FusionModule(nn.Module):
def __init__(self, text_dim=768, img_dim=1024):
super().__init__()
self.text_gate = nn.Linear(text_dim, img_dim)
self.img_gate = nn.Linear(img_dim, img_dim)
self.out_proj = nn.Linear(img_dim, img_dim)
def forward(self, text_feat, img_feat):
# 门控注意力机制
gate_t = torch.sigmoid(self.text_gate(text_feat))
gate_i = torch.sigmoid(self.img_gate(img_feat))
# 特征融合
fused = gate_t * text_feat.unsqueeze(1) + gate_i * img_feat
return self.out_proj(fused)
融合公式:
F fused = σ ( W t T ) ⊙ T + σ ( W i I ) ⊙ I \mathbf{F}_{\text{fused}} = \sigma(W_t \mathbf{T}) \odot \mathbf{T} + \sigma(W_i \mathbf{I}) \odot \mathbf{I} Ffused=σ(WtT)⊙T+σ(WiI)⊙I
其中 T \mathbf{T} T为文本特征, I \mathbf{I} I为图像特征, ⊙ \odot ⊙表示逐元素乘法
4. MSRoPE位置编码创新
传统位置编码在图文融合场景的局限:
- 文本与图像位置冲突
- 高分辨率扩展困难
MSRoPE解决方案:
class MSRoPE(nn.Module):
def __init__(self, dim, max_len=2048):
super().__init__()
self.dim = dim
inv_freq = 1.0 / (10000 ** (torch.arange(0, dim, 2).float() / dim))
self.register_buffer("inv_freq", inv_freq)
def forward(self, text_pos, img_pos):
# 文本位置编码 (对角线分布)
t = text_pos.unsqueeze(1) * self.inv_freq
text_emb = torch.cat([torch.sin(t), torch.cos(t)], dim=-1)
# 图像位置编码 (中心扩展)
h, w = img_pos
grid_y = (torch.arange(h) - h//2) / (h//2)
grid_x = (torch.arange(w) - w//2) / (w//2)
grid = torch.stack(torch.meshgrid(grid_y, grid_x), dim=-1)
img_emb = torch.einsum('ij,klj->kli', self.inv_freq, grid)
return text_emb, torch.cat([torch.sin(img_emb), torch.cos(img_emb)], dim=-1)
数学原理:
文本编码: PE ( t , 2 i ) = sin ( t 1000 0 2 i / d ) PE ( t , 2 i + 1 ) = cos ( t 1000 0 2 i / d ) 图像编码: PE ( x , y , 2 i ) = sin ( Δ x ⋅ Δ y γ 2 i / d ) γ = 缩放因子 \begin{align*} \text{文本编码: } & \text{PE}(t,2i) = \sin\left(\frac{t}{10000^{2i/d}}\right) \\ & \text{PE}(t,2i+1) = \cos\left(\frac{t}{10000^{2i/d}}\right) \\ \text{图像编码: } & \text{PE}(x,y,2i) = \sin\left(\frac{\Delta x \cdot \Delta y}{\gamma^{2i/d}}\right) \\ & \gamma = \text{缩放因子} \end{align*} 文本编码: 图像编码: PE(t,2i)=sin(100002i/dt)PE(t,2i+1)=cos(100002i/dt)PE(x,y,2i)=sin(γ2i/dΔx⋅Δy)γ=缩放因子
5. 数据处理引擎
5.1 多级数据过滤
七阶段过滤流程:
def data_filtering(dataset, stage):
if stage == 1: # 基础过滤
dataset = filter_resolution(dataset, min=256)
dataset = remove_duplicates(dataset)
dataset = filter_nsfw(dataset)
elif stage == 2: # 质量优化
dataset = filter_blur(dataset, threshold=0.7)
dataset = filter_exposure(dataset)
elif stage == 3: # 图文对齐
dataset = clip_filter(dataset, threshold=0.85)
# ... 其他阶段
return dataset
表2:数据分布统计
| 类别 | 占比 | 内容示例 |
|---|---|---|
| 自然场景 | 55% | 风景/动物/城市 |
| 设计素材 | 27% | 海报/UI/PPT |
| 人物图像 | 13% | 肖像/运动 |
| 合成数据 | 5% | 文本渲染增强 |
5.2 文本感知合成
三种合成策略:
def text_rendering_synthesis(mode, text, background):
if mode == "pure":
return render_on_plain(text, background)
elif mode == "contextual":
return blend_with_scene(text, background)
elif mode == "structured":
return apply_to_template(text, template)
6. 训练策略解析
6.1 生产者-消费者框架
实现代码:
class DataProducer:
def __init__(self, vl_model, vae):
self.vl_model = vl_model
self.vae = vae
self.cache = SharedCache()
def process(self, data):
img = preprocess(data['image'])
text_emb = self.vl_model.encode(data['text'])
img_emb = self.vae.encode(img)
self.cache.store(text_emb, img_emb, data['resolution'])
class DataConsumer:
def __init__(self, model):
self.model = model
self.optim = DistributedOptimizer(model.parameters())
def train_step(self, batch):
loss = model(batch)
loss.backward()
self.optim.step()
6.2 混合并行训练
# 张量并行配置
parallel_config = {
"tensor_parallel_degree": 4,
"pipeline_parallel_degree": 2,
"data_parallel_degree": 8
}
# Megatron集成
from megatron.core import parallel_state
parallel_state.initialize_model_parallel(**parallel_config)
# 混合精度训练
scaler = GradScaler()
with autocast():
output = model(input)
loss = criterion(output, target)
scaler.scale(loss).backward()
scaler.step(optimizer)
性能优化:
- 头维度并行:降低通信开销30%
- 梯度切分:减少GPU内存峰值45%
7. 核心代码实现
7.1 MMDIT模块实现
class MMDiTBlock(nn.Module):
def __init__(self, dim, heads, text_dim=768):
super().__init__()
self.cross_attn = CrossAttention(dim, text_dim, heads)
self.norm1 = RMSNorm(dim)
self.mlp = nn.Sequential(
nn.Linear(dim, dim * 4),
nn.GELU(),
nn.Linear(dim * 4, dim)
)
self.norm2 = RMSNorm(dim)
def forward(self, x, text_emb):
# 跨模态注意力
attn_out = self.cross_attn(self.norm1(x), text_emb)
x = x + attn_out
# 前馈网络
mlp_out = self.mlp(self.norm2(x))
return x + mlp_out
class CrossAttention(nn.Module):
def __init__(self, dim, context_dim, heads=8):
super().__init__()
self.heads = heads
self.scale = (dim // heads) ** -0.5
self.to_q = nn.Linear(dim, dim)
self.to_kv = nn.Linear(context_dim, dim * 2)
self.to_out = nn.Linear(dim, dim)
def forward(self, x, context):
q = self.to_q(x)
k, v = self.to_kv(context).chunk(2, dim=-1)
q, k, v = map(self._split_heads, (q, k, v))
attn = torch.softmax(torch.matmul(q, k.transpose(-2, -1)) * self.scale, dim=-1)
out = torch.matmul(attn, v)
out = self._combine_heads(out)
return self.to_out(out)
7.2 流匹配训练
def flow_matching_loss(model, x0, text_emb):
# 采样噪声和时间步
x1 = torch.randn_like(x0)
t = torch.rand(x0.size(0), device=x0.device)
# 计算中间状态
xt = t * x0 + (1 - t) * x1
vt = x0 - x1
# 模型预测
pred_v = model(xt, t, text_emb)
# 损失计算
return F.mse_loss(pred_v, vt)
# 训练循环
for batch in dataloader:
x0 = vae_encode(batch['image'])
text_emb = text_encoder(batch['text'])
loss = flow_matching_loss(model, x0, text_emb)
optimizer.zero_grad()
loss.backward()
optimizer.step()
8. 多模态基准测试
表3:文本生成任务性能对比
| 基准测试 | Qwen-Image | GPT-Image | Seedream | 提升幅度 |
|---|---|---|---|---|
| DPG | 88.32 | 85.15 | 88.27 | +3.7% |
| GenEval | 0.91 | 0.84 | 0.84 | +8.3% |
| LongText-EN | 0.896 | 0.956 | 0.878 | +2.1% |
| LongText-ZH | 0.878 | 0.619 | 0.814 | +41.8% |
表4:图像编辑任务性能
| 任务类型 | GEdit评分 | ImgEdit评分 |
|---|---|---|
| 文本编辑 | 8.00 | 4.38 |
| 对象替换 | 7.85 | 4.66 |
| 姿态调整 | 7.62 | 3.82 |
| 风格转换 | 7.86 | 4.14 |

图2:复杂文本渲染效果对比(来源:Qwen技术报告)
9. 未来发展方向
- 三维生成扩展:
class VideoMMDiT(MMDiT): def __init__(self, time_dim=128): super().__init__() self.time_emb = nn.Embedding(1024, time_dim) - 动态分辨率支持:
def dynamic_resolution(self, img, target_size): return adaptive_pooling(img, target_size) - 多模态强化学习:
class MultimodalPPO: def update(self, image_reward, text_reward): total_reward = 0.7*image_reward + 0.3*text_reward # ...PPO更新步骤
10. 结论
Qwen-Image通过三大技术创新实现突破:
- 双流MMDIT架构:分离语义理解与视觉重建
- MSRoPE位置编码:解决图文位置冲突问题
- 渐进式课程学习:层级化训练策略
# 简易推理示例
model = QwenImage.from_pretrained("qwen/image-v1")
image = generate_image(
prompt="咖啡馆菜单:拿铁25元 卡布奇诺28元",
reference_image=menu_template,
style="水彩画"
)
开源资源:
正如Qwen团队在技术报告中所说:“Qwen-Image不仅是图像生成工具,更是实现视觉-语言智能统一的关键一步。通过将文本精准渲染与图像语义理解相结合,我们正在构建真正理解人类创作意图的多模态系统。”