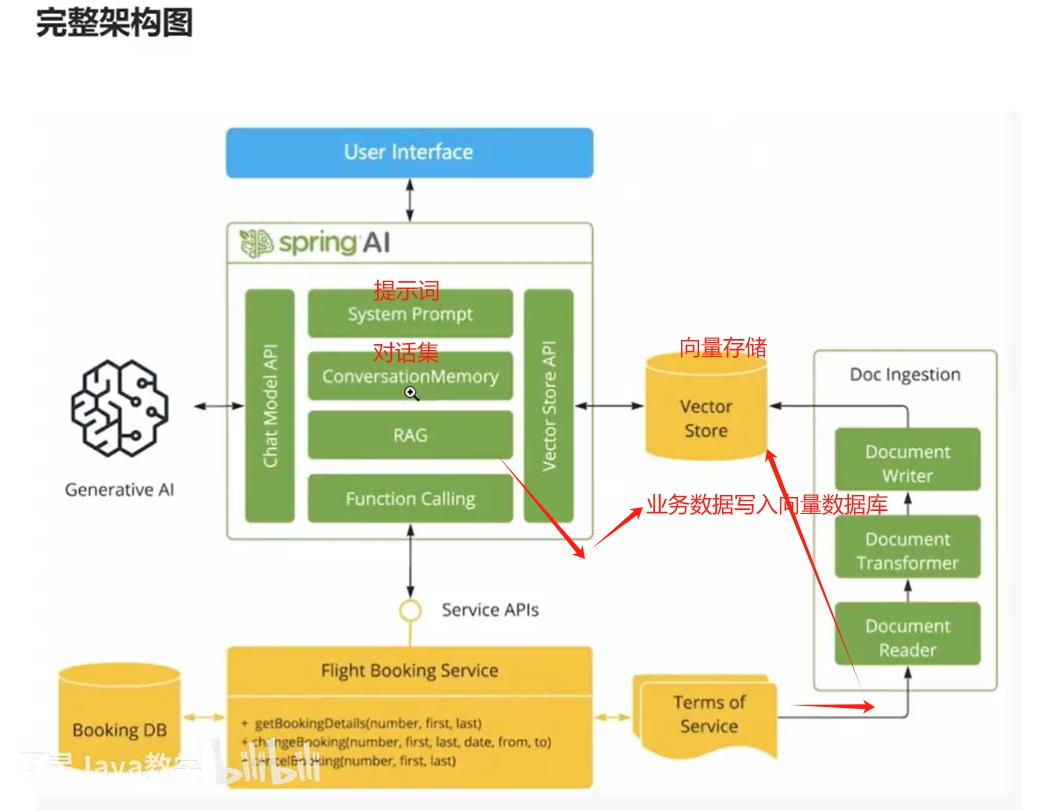
SpringAi主要依赖
System Prompt :设置提示词 用来预设角色
ConversationMemory: 对话集
RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接
Function Calling 用来调用自己的api
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>1.0.0-M6</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<!--Springai依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
<!--pgVector向量数据库-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pgvector-store-spring-boot-starter</artifactId>
</dependency>
<!--doc解析器-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!--分词器-->
<dependency>
<groupId>com.knuddels</groupId>
<artifactId>jtokkit</artifactId>
<version>1.1.0</version>
</dependency>
</dependencies>
yml配置
ai:
ollama:
language: zh
response-language: zh
chat:
options:
model: qwen2:7b
embedding:
enabled: true
model: bge-m3
base-url: http://172.21.198.208:11434/
vectorstore:
pgvector:
index-type: HNSW
distance-type: COSINE_DISTANCE
dimension: 1024
batching-strategy: TOKEN_COUNT
max-document-batch-size: 10000
chat.options.model: qwen2:7b 这个是默认的模型(但是后期不需要了我们从数据库中拿)
embedding.model: bge-m3 这个模型是用来进行向量化的模型
base-url: http://172.21.198.208:11434/ 这个是ollama模型访问地址
我这里用的是pgvector来作为向量库 vectorstore.pgvector:
dimension: 1024 这个至关重要 这里写多少创建向量库的时候就要写多少 如果两边不一致的话向向量库向量会失败
创建向量库
-- 增加扩展
create extension if not exists vector;
create extension if not exists hstore;
create extension if not exists "uuid-ossp";
create table if not exists vector_store
(
id uuid primary key default uuid_generate_v4(),
content text,
metadata json,
embedding vector(1024) //这个的参数要和配置文件的一样,要不插入不进去 这个就是向量数据库的维度
);
create index on vector_store using hnsw(embedding vector_cosine_ops);
ollama对话模型
/**
* Ollama模型配置类
* 负责配置和管理不同的Ollama模型实例
*/
@Slf4j
@Configuration
public class OllamaModelConfig {
/**
* 创建OllamaChatModel的通用方法
* @param baseUrl Ollama服务地址
* @param modelName 模型名称
* @param temperature 温度参数
* @return 配置好的OllamaChatModel实例
*/
public OllamaChatModel createOllamaModel(String baseUrl, String modelName, double temperature) {
Assert.hasText(baseUrl, "Ollama服务地址不能为空");
Assert.hasText(modelName, "模型名称不能为空");
Assert.isTrue(temperature >= 0 && temperature <= 1, "温度参数必须在0-1之间");
try {
log.debug("开始创建Ollama模型: {}, 温度参数: {}, 服务地址: {}", modelName, temperature, baseUrl);
OllamaApi ollamaApi = new OllamaApi(baseUrl);
OllamaOptions options = OllamaOptions.builder()
.model(modelName)
.temperature(temperature)
.build();
OllamaChatModel model = OllamaChatModel.builder()
.ollamaApi(ollamaApi)
.defaultOptions(options)
.observationRegistry(ObservationRegistry.NOOP)
.build();
log.debug("Ollama模型创建成功: {}", modelName);
return model;
} catch (Exception e) {
log.error("创建Ollama模型失败: {}", modelName, e);
throw new RuntimeException("创建Ollama模型失败: " + modelName, e);
}
}
}
temperature温度的值越小回答的越准确
调用实例
// 使用模型配置创建OllamaChatModel
OllamaChatModel chatModel = ollamaModelConfig.createOllamaModel(
aiModel.getAimodelAccessAddress(),
aiModel.getAimodelName(),
aiModel.getAimodelTemperature());
ChatClient chatClient = ChatClient.builder(chatModel).build();
// 使用响应式流处理对话
return chatClient.prompt()
.user(message)
.stream()
.content()
.onErrorResume(e -> {
log.error("聊天过程发生错误: ", e);
return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");
});
接下来介绍上面提到的主要的四个属性
1.System Prompt :设置提示词 用来预设角色
systemPrompt="你是一位专业的室内设计顾问,精通各种装修风格、材料选择和空间布局。请基于提供的参考资料,为用户提供专业、详细且实用的建议。在回答时,请注意:\n" +
"1. 准确理解用户的具体需求\n" +
"2. 结合参考资料中的实际案例\n" +
"3. 提供专业的设计理念和原理解释\n" +
"4. 考虑实用性、美观性和成本效益\n" +
"5. 如有需要,可以提供替代方案";
// 创建聊天客户端
ChatClient chatClient = ChatClient.builder(ollamaChatModel)
.defaultSystem(systemPrompt)
.build();
将预设词放入defaultSystem中之后ai就会根据我们的提示词进行工作
2.ConversationMemory: 对话集
package com.system.ai.config;
import lombok.extern.slf4j.Slf4j;
import org.springframework.ai.chat.memory.ChatMemory;
import org.springframework.ai.chat.messages.AssistantMessage;
import org.springframework.ai.chat.messages.Message;
import org.springframework.ai.chat.messages.UserMessage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.context.annotation.Configuration;
import org.springframework.jdbc.core.JdbcTemplate;
import java.util.List;
//持久化对话
@Slf4j
@Configuration
public class AiChatMemory implements ChatMemory {
//这个是存储在内存中
Map<String, List<Message>> conversationHistory = new ConcurrentHashMap<>();
//新增持久化 (现在没有做持久化所以都存在了内存中 重启后会丢失对话记忆)
@Override
public void add(String conversationId, List<Message> messages) {
log.error("对话id: {}", conversationId);
this.conversationHistory.putIfAbsent(conversationId, new ArrayList<>());
this.conversationHistory.get(conversationId).addAll(messages);
}
//获取
@Override
public List<Message> get(String conversationId, int lastN) {
List<Message> all = this.conversationHistory.get(conversationId);
return all != null ? all.stream().skip(Math.max(0, all.size() - lastN)).toList() : List.of();
}
//清除
@Override
public void clear(String conversationId) {
this.conversationHistory.remove(conversationId);
}
}
这个是我们创建的自己的AiChatMemory他继承了ChatMemory类,可以看到他其实就是将消息存储到List内 保存到内存中 当我们程序重启之后就会从内存删除
使用我们自己的AiChatMemory
@Autowired
private AiChatMemory aiChatMemory ;
ChatClient chatClient = ChatClient.builder(ollamaChatModel)
.defaultAdvisors(new PromptChatMemoryAdvisor(aiChatMemory))//设置上下文
.build();
Flux<String> content = chatClient.prompt()
.user(message)
.advisors(advisorSpec -> //设置持久化对话的查询的联通上下文
//设置聊天记忆检索的大小为100
advisorSpec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)
// 设置对话ID 在聊天应用中,不同用户或不同会话的对话历史应该是相互独立的。
// 通过设置对话ID,可以让聊天记忆顾问根据不同的对话ID来管理和检索相应的对话历史记录。
// 这样,当用户发起新的对话时,系统可以根据对话ID准确地获取该用户之前的对话内容,从而提供更连贯和个性化的服务。
.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "测试固定id")
)
.stream()
.content();
//聊天交互的场景中, content 流会不断地发出聊天响应的文本片段,
// 而 [complete] 这个字符串可以作为一个特殊的标识,用来表示聊天响应已经结束。
// 当客户端接收到这个 "[complete]" 标识时,就可以知道整个聊天响应已经全部接收完毕,
// 从而可以进行相应的处理,例如关闭连接、更新 UI 状态等。
设置上下文有两个点
第一个点就是创建ChatClient的时候的:
.defaultAdvisors(new PromptChatMemoryAdvisor(aiChatMemory))//设置上下文
这里指定的是在哪里取上下文
.advisors(advisorSpec -> //设置持久化对话的查询的联通上下文
//设置聊天记忆检索的大小为100
advisorSpec.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY, 100)
// 设置对话ID 在聊天应用中,不同用户或不同会话的对话历史应该是相互独立的。
// 通过设置对话ID,可以让聊天记忆顾问根据不同的对话ID来管理和检索相应的对话历史记录。
// 这样,当用户发起新的对话时,系统可以根据对话ID准确地获取该用户之前的对话内容,从而提供更连贯和个性化的服务。
.param(AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY, "测试固定id")
)
这里指定的是会话的key和取出的上下文条数
AbstractChatMemoryAdvisor.CHAT_MEMORY_RETRIEVE_SIZE_KEY= 取出的上下文条数
AbstractChatMemoryAdvisor.CHAT_MEMORY_CONVERSATION_ID_KEY = 会话id
也可以通过向量库存储对话上下文上下文
//对话历史向量库
AbstractChatMemoryAdvisor chatMemoryAdvisor = VectorStoreChatMemoryAdvisor.builder(历史对话向量库)
.protectFromBlocking(true)
.chatMemoryRetrieveSize(取出多少条)
.conversationId(会话id)
.build();
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultAdvisors(chatMemoryAdvisor) //向量库版的历史对话
.build();
3.RAG: 检索增强生成 将业务数据存储在向量数据库中(做相似性检索)通过RAG进行链接
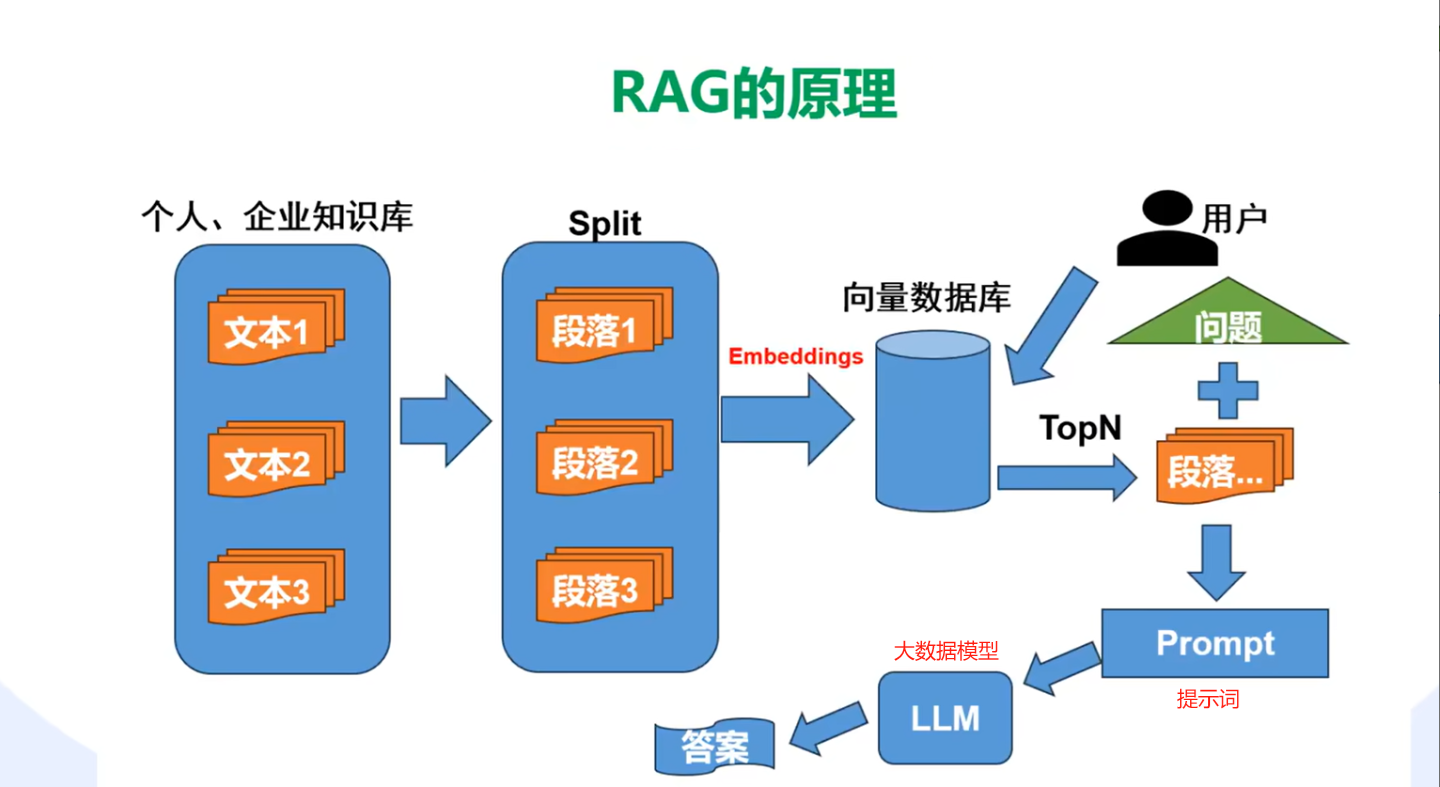
对文件进行向量化
@Autowired
@Qualifier("secondaryJdbcTemplate")
private JdbcTemplate jdbcTemplate;
//引入嵌入模型
@Autowired
@Qualifier("ollamaEmbeddingModel")
private EmbeddingModel embeddingModel;
/**
* 创建向量存储的通用方法
*/
private PgVectorStore.Builder createVectorStoreBuilder(JdbcTemplate jdbcTemplate,
EmbeddingModel embeddingModel,
String tableName) {
Assert.notNull(jdbcTemplate, "JdbcTemplate 不能为空");
Assert.notNull(embeddingModel, "EmbeddingModel 不能为空");
Assert.hasText(tableName, "表名不能为空");
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.dimensions(dimensions)
.vectorTableName(tableName);
}
public Result saveVectorStoreByType(String filePath, String dfileFid) {
try {
// 检查文件是否存在
File file = new File(filePath);
if (!file.exists()) {
return Result.error("文件不存在: " + filePath);
}
Resource resource = new FileSystemResource(filePath);
TikaDocumentReader reader = new TikaDocumentReader(resource);
List<Document> documentList = reader.read();
// 创建文本分割器并配置智能参数
TextSplitter textSplitter = TokenTextSplitter.builder()
.withChunkSize(300) // 适中的块大小
.withMinChunkSizeChars(100) // 最小块字符数
.withKeepSeparator(true) // 保留分隔符
.withMaxNumChunks(1000) // 最大块数量限制
.build();
// 应用智能分块
List<Document> splitDocuments = textSplitter.apply(documentList);
// 对分块结果进行后处理,确保质量
List<Document> processedDocuments = new ArrayList<>();
for (Document doc : splitDocuments) {
String text = doc.getText().trim();
// 跳过过短的块
/*if (text.length() < 50) {
continue;
}*/
// 处理过长的块
if (text.length() > 1000) {
// 在适当的位置进行二次分割
List<String> subChunks = splitLongText(text);
for (String subChunk : subChunks) {
if (subChunk.trim().length() >= 50) {
Map<String, Object> metadata = new HashMap<>(doc.getMetadata());
metadata.put("knowledgeId", dfileFid);//知识库id
processedDocuments.add(new Document(subChunk.trim(), metadata));
}
}
} else {
// 添加元数据
Map<String, Object> metadata = new HashMap<>(doc.getMetadata());
metadata.put("knowledgeId", dfileFid);//知识库id
processedDocuments.add(new Document(text, metadata));
}
}
VectorStore vectorStore = vectorStoreFactory.createVectorStoreByTableName(jdbcTemplate, embeddingModel, "vector_store");
vectorStore.add(processedDocuments);
log.info("成功将文件加载到向量数据库,共 {} 个文档片段", processedDocuments.size());
return Result.ok("成功将文件 " + file.getName() + " 加载到向量数据库,共 " + processedDocuments.size() + " 个文档片段");
} catch (Exception e) {
log.error("保存向量存储失败", e);
throw new RuntimeException("保存向量存储失败: " + e.getMessage());
}
}
ollamaEmbeddingModel 注入的是 ai.ollama.embedding.model: bge-m3 模型
当将数据向量化后,创建获取
/**
* 创建向量存储的通用方法
*/
private PgVectorStore.Builder createVectorStoreBuilder(JdbcTemplate jdbcTemplate,
EmbeddingModel embeddingModel,
String tableName) {
Assert.notNull(jdbcTemplate, "JdbcTemplate 不能为空");
Assert.notNull(embeddingModel, "EmbeddingModel 不能为空");
Assert.hasText(tableName, "表名不能为空");`在这里插入代码片`
return PgVectorStore.builder(jdbcTemplate, embeddingModel)
.dimensions(dimensions)
.vectorTableName(tableName);
}
@Bean
@Qualifier("VectorStore ")
public VectorStore enterpriseVectorStore(@Qualifier("secondaryJdbcTemplate") JdbcTemplate jdbcTemplate,
@Qualifier("ollamaEmbeddingModel") EmbeddingModel embeddingModel) {
try {
return createVectorStoreBuilder(jdbcTemplate, embeddingModel, "vector_store")
.build();
} catch (Exception e) {
throw new RuntimeException("创建向量库失败", e);
}
}
- 从向量库中查询相关信息 转为提示词给ai
// 从向量库中查询相关信息
private String getVectorStoreStr(String message) {
List<String> relevantInfo = new ArrayList<>();
try {
List<Document> similarDocs = enterpriseVectorStore.similaritySearch(message);
for (Document doc : similarDocs) {
relevantInfo.add(doc.getText());
}
log.error("从向量库获取到{}条相关信息", relevantInfo.size());
} catch (Exception e) {
log.error("向量库查询失败,将继续使用原始对话: {}", e.getMessage());
}
// 如果找到相关信息,添加到系统提示中
StringBuilder context = new StringBuilder();
String systemPrompt="";
if (!relevantInfo.isEmpty()) {
context.append("以下是一些相关的背景信息,请参考这些信息来回答问题:\n\n");
for (String info : relevantInfo) {
context.append("- ").append(info).append("\n");
}
context.append("\n请基于以上信息,结合自己的知识来回答用户的问题。如果上述信息不足以完整回答问题,可以使用自己的知识进行补充。");
systemPrompt=context.toString();
}
return systemPrompt;
}
//放入预设角色中
ChatClient chatClient = ChatClient.builder(ollamaChatModel)
.defaultSystem(getVectorStoreStr(message))
.build();
- 创建检索增强顾问
private Advisor getSearchEnhancementConsultant(VectorStore vectorStore,List<String> knowledge) {
// 1. 构建复杂的文档过滤条件
var b = new FilterExpressionBuilder();
Object[] array = knowledge.toArray();
// 使用in条件,匹配指定的知识库ID列表
var filterExpression = b.in("knowledgeId", array);
// 2. 配置文档检索器
// 设置相似度阈值和返回文档数量,同时应用过滤条件
DocumentRetriever retriever = VectorStoreDocumentRetriever.builder()
.vectorStore(vectorStore)
.similarityThreshold(0.5) // 设置相似度阈值,大于0.5的文档才会被返回
.topK(3) // 返回相似度最高的前3个文档
.filterExpression(filterExpression.build())
.build();
// 3. 创建并配置检索增强顾问
// allowEmptyContext设置为true,确保在没有找到相关文档时也能回答问题
Advisor advisor = RetrievalAugmentationAdvisor.builder()
.queryAugmenter(ContextualQueryAugmenter.builder()
.allowEmptyContext(true) // 允许空上下文,当没有找到相关文档时也会回答
.build())
.documentRetriever(retriever)
.build();
return advisor;
}
chatClient.prompt()
.user(message)
.advisors(advisor) // 只有在开启向量库时才添加检索增强顾问 // 添加检索增强顾问
.stream()
.content()
.onErrorResume(e -> {
log.error("聊天过程发生错误: ", e);
return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");
});
- 使用ai重写查询后再去向量库查询
private Advisor getSearchEnhancementConsultant2(ChatClient chatClient, VectorStore vectorStore) {
Advisor retrievalAdvisor = RetrievalAugmentationAdvisor.builder()
.queryTransformers(
RewriteQueryTransformer.builder()
.chatClientBuilder(chatClient.mutate())//使用ai优化查询
.build()
)
.documentRetriever(
VectorStoreDocumentRetriever.builder()
.similarityThreshold(0.50)
.vectorStore(vectorStore)
.build()
)
.build();
return retrievalAdvisor;
}
chatClient.prompt()
.user(message)
.advisors(advisor) // 只有在开启向量库时才添加检索增强顾问 // 添加检索增强顾问
.stream()
.content()
.onErrorResume(e -> {
log.error("聊天过程发生错误: ", e);
return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");
});
4.Function Calling 用来调用自己的api (这个官网上淘汰了)
@Bean
@Description("处理机票退订")//告诉ai什么时候调用这个方法
public Function<CancelBookingRequest, String> cancelBooking() {
return cancelBookingRequest -> {
//在这调用方法
flightBookingService.cancelBooking(cancelBookingRequest.bookingId(),cancelBookingRequest.name() );
return "退订成功";
};
}
ChatClient chatClient = ChatClient.builder(chatModel)
.defaultFunctions("cancelBooking") //这指定的是调用那些方法的bean的名称 多个用逗号分割
.build();
5.Tools (这个有个问题调用工具后返回就不是流式的了)
public class ToolsFactory {
@Tool(description = "获取用户的数量")
void getUserCount() {
System.out.println("ai获取用户的数量");
}
}
chatClient.prompt()
.user(message)
.tools(new ToolsFactory()) 加上这个工具后 流式返回就失效了
.stream()
.content()
.onErrorResume(e -> {
log.error("聊天过程发生错误: ", e);
return Flux.just("抱歉,处理您的请求时出现了错误,请稍后重试。");
});