本文主要介绍博主自己复现以下代码时遇到的问题,代码链接:https://github.com/robodhruv/visualnav-transformer?tab=readme-ov-file
该代码主要复现了三种视觉导航模型:GNM,ViNT,NoMaD,相关的论文链接如下:GNM,ViNT,NoMaD。
首先,按照README里面的教程先在代码主文件夹下创建虚拟环境nomad_train:
conda env create -f train/train_environment.yml其中,会安装pytorch以及一系列的依赖,由于各个电脑的显卡版本、cuda版本的不同,建议自己先去pytorch官网安装与自身电脑配对版本的pytorch,再使用上述命令安装其他库。
其次,继续按着README中的教程:
激活虚拟环境
conda activate vint_train安装vint_train库
pip install -e train/安装diffusion_policy库
git clone git@github.com:real-stanford/diffusion_policy.git
pip install -e diffusion_policy/到此为止,代码运行的虚拟环境就配置完成了。
接下来,需要下载模型使用的数据集并进行预处理,由于电脑空间有限,故选择了最小的一个数据集:go_stanford。
使用以下代码对数据集进行预处理:
import os
import re
import shutil # 新增:用于文件复制
def get_numbered_images(folder_path):
"""获取文件夹中所有带数字编号的图片文件,并按编号排序"""
# 支持的图片扩展名
image_extensions = ('.jpg', '.jpeg', '.png', '.gif', '.bmp', '.tiff')
# 正则表达式匹配文件名中的数字(假设文件名格式为xxx数字xxx.扩展名)
number_pattern = re.compile(r'(\d+)')
image_files = []
for file in os.listdir(folder_path):
file_path = os.path.join(folder_path, file)
# 检查是否为图片文件
if os.path.isfile(file_path) and file.lower().endswith(image_extensions):
# 提取文件名中的数字
match = number_pattern.search(file)
if match:
try:
number = int(match.group(1))
image_files.append((file, number))
except ValueError:
continue
# 按数字编号排序
image_files.sort(key=lambda x: x[1])
# 返回排序后的文件名列表
return [f[0] for f in image_files]
def copy_and_rename_images(parent_dir):
"""
重命名指定文件夹中的所有子文件夹为traj_1, traj_2, ...
并为每个子文件夹中的最后一个编号图片**复制副本**,重命名为T_num
参数:
parent_dir: 包含子文件夹的父文件夹路径
"""
# 检查父文件夹是否存在
if not os.path.exists(parent_dir):
print(f"错误: 文件夹 '{parent_dir}' 不存在")
return
if not os.path.isdir(parent_dir):
print(f"错误: '{parent_dir}' 不是一个文件夹")
return
# 获取所有子文件夹,排除文件
subfolders = [f for f in os.listdir(parent_dir)
if os.path.isdir(os.path.join(parent_dir, f))]
if not subfolders:
print(f"在 '{parent_dir}' 中没有找到子文件夹")
return
# 按创建时间排序
subfolders.sort(key=lambda x: os.path.getctime(os.path.join(parent_dir, x)))
# 重命名子文件夹并处理图片(复制+重命名副本)
for i, folder in enumerate(subfolders, start=1):
old_folder_path = os.path.join(parent_dir, folder)
new_folder_name = f"traj_{i}"
new_folder_path = os.path.join(parent_dir, new_folder_name)
# 如果新文件夹名称已存在,跳过
if os.path.exists(new_folder_path):
print(f"警告: 文件夹 '{new_folder_name}' 已存在,跳过重命名 '{folder}'")
continue
# 先重命名文件夹
os.rename(old_folder_path, new_folder_path)
print(f"重命名文件夹: '{folder}' -> '{new_folder_name}'")
# 获取文件夹中的编号图片并排序
image_files = get_numbered_images(new_folder_path)
if image_files:
# 获取最后一个图片(编号最大的图片)
last_image = image_files[-1]
original_image_path = os.path.join(new_folder_path, last_image) # 原图片路径
# 获取图片扩展名,构建副本名称(T_num.扩展名)
_, ext = os.path.splitext(last_image)
copied_image_name = f"T_{i}{ext}"
copied_image_path = os.path.join(new_folder_path, copied_image_name) # 副本路径
# 如果副本已存在,跳过复制
if os.path.exists(copied_image_path):
print(f"警告: 副本 '{copied_image_name}' 已存在,跳过复制")
continue
# 复制原图片到副本(核心修改:用shutil.copy复制而非os.rename重命名)
shutil.copy(original_image_path, copied_image_path)
print(f" 已复制并命名: '{last_image}' -> '{copied_image_name}'(原图片保留)")
else:
print(f" 在 '{new_folder_name}' 中未找到带编号的图片")
print(f"完成!共处理了 {len(subfolders)} 个子文件夹")
if __name__ == "__main__":
# 替换为你的父文件夹路径
parent_folder = "/home/charles/桌面/go_stanford"
copy_and_rename_images(parent_folder)
运行上述代码后,数据集的格式应该如以下形式:
├── <dataset_name>
│ ├── <name_of_traj1>
│ │ ├── 0.jpg
│ │ ├── 1.jpg
│ │ ├── ...
│ │ ├── T_1.jpg
│ │ └── traj_data.pkl
│ ├── <name_of_traj2>
│ │ ├── 0.jpg
│ │ ├── 1.jpg
│ │ ├── ...
│ │ ├── T_2.jpg
│ │ └── traj_data.pkl
│ ...
└── └── <name_of_trajN>
├── 0.jpg
├── 1.jpg
├── ...
├── T_N.jpg
└── traj_data.pkl接下来,使用train文件夹中的data_split.py划分训练集和测试集:
python data_split.py -i "/home/charles/桌面/go_stanford_cropped" -d "go_stanford" -s 0.7 -o "/home/charles/桌面/data_splits"划分后的数据集形似如下:
├── <dataset_name>
│ ├── train
| | └── traj_names.txt
└── └── test
└── traj_names.txt 接下来就可以使用train文件夹中的train.py进行训练了:
python train.py -c /home/charles/桌面/visualnav-transformer-main/train/config/gnm_copy.yaml训练的配置文件在train下的config文件夹中,可按自身需求进行更改。
运行上述代码遇到的第一个问题:
Traceback (most recent call last):
File "train.py", line 2, in <module>
import wandb
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/__init__.py", line 26, in <module>
from wandb import sdk as wandb_sdk
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/sdk/__init__.py", line 5, in <module>
from . import wandb_helper as helper # noqa: F401
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/sdk/wandb_helper.py", line 6, in <module>
from .lib import config_util
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/sdk/lib/config_util.py", line 7, in <module>
from wandb.util import load_yaml
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/util.py", line 51, in <module>
import requests
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/requests/__init__.py", line 48, in <module>
from charset_normalizer import __version__ as charset_normalizer_version
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/charset_normalizer/__init__.py", line 24, in <module>
from .api import from_bytes, from_fp, from_path, is_binary
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/charset_normalizer/api.py", line 5, in <module>
from .cd import (
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/charset_normalizer/cd.py", line 14, in <module>
from .md import is_suspiciously_successive_range
AttributeError: partially initialized module 'charset_normalizer' has no attribute 'md__mypyc' (most likely due to a circular import)该问题是由于charset_normalizer 模块被损坏或版本不对应导致的,采用以下方式重新安装:
# 先卸载现有版本
pip uninstall -y charset-normalizer
# 再安装最新稳定版
pip install --upgrade charset-normalizer解决后遇到第二个问题:
Traceback (most recent call last):
File "train.py", line 17, in <module>
from diffusers.schedulers.scheduling_ddpm import DDPMScheduler
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/diffusers/__init__.py", line 46, in <module>
from .pipeline_utils import DiffusionPipeline
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/diffusers/pipeline_utils.py", line 35, in <module>
from .dynamic_modules_utils import get_class_from_dynamic_module
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/diffusers/dynamic_modules_utils.py", line 29, in <module>
from huggingface_hub import HfFolder, cached_download, hf_hub_download, model_info
ImportError: cannot import name 'cached_download' from 'huggingface_hub' (/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/huggingface_hub/__init__.py)这个问题是由于 huggingface_hub 库的版本与 diffusers 库不兼容导致的。cached_download 函数在较新的 huggingface_hub 版本中已被移除或重命名,而我的 diffusers 版本仍然依赖这个函数。可以安装相对应版本的库解决这一问题:
# 已知兼容的版本组合
pip install diffusers==0.20.0 huggingface_hub==0.17.0接下来遇到了不能理解的问题:
已放弃 (核心已转储)我在将gnm.yaml中的wandb设置成false后解决了这一问题,具体原因还未知。
之后,又遇到了一个问题:
QObject::moveToThread: Current thread (0x56142e475720) is not the object's thread (0x56142e58d940).
Cannot move to target thread (0x56142e475720)
qt.qpa.plugin: Could not load the Qt platform plugin "xcb" in "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/cv2/qt/plugins" even though it was found.
This application failed to start because no Qt platform plugin could be initialized. Reinstalling the application may fix this problem.
Available platform plugins are: xcb, eglfs, minimal, minimalegl, offscreen, vnc, webgl.这个问题是由于opencv-python版本过高导致的,使用下述代码安装特定版本的opencv-python:
pip install opencv-python==4.3.0.36在训练完成1轮后再次报错:
Traceback (most recent call last):
File "train.py", line 402, in <module>
main(config)
File "train.py", line 304, in main
train_eval_loop(
File "/home/charles/桌面/visualnav-transformer-main/train/vint_train/training/train_eval_loop.py", line 126, in train_eval_loop
wandb.log({}, commit=False)
File "/home/charles/miniconda3/envs/nomad_train/lib/python3.8/site-packages/wandb/sdk/lib/preinit.py", line 36, in preinit_wrapper
raise wandb.Error(f"You must call wandb.init() before {name}()")
wandb.errors.Error: You must call wandb.init() before wandb.log()这是由于我们之前将wandb设置成了false,所以无法使用wandb.log(),我们只需要将train_eval_loop.py中的wandb.log()注释掉就好啦。
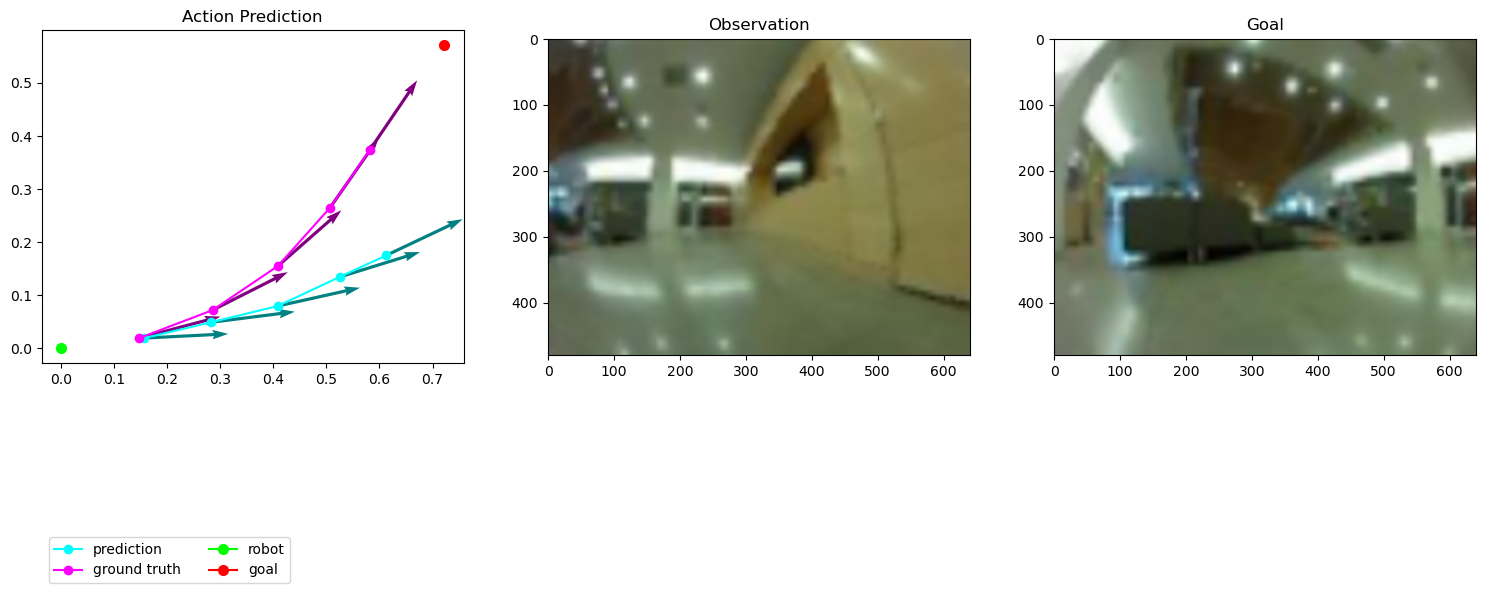
到此,可以成功训练和测试模型了,简单训练20轮后的结果如下: